Testing
Testing
Usability Test
毕业后,你想做一个机器学习的创业项目,分析视觉指向的区域。你设计分析原始数据的算法,并优化准确性。你去了市场,但没有卖出去。一年后,你就被淘汰了。怎么会这样?
你的眼睛被算法挡住了!
- 你在解决谁的问题?有视觉指向的需求吗?或者你只是被机器学习迷住了,为你那令人敬畏的算法找到了一个合适的应用领域?
- 你忽略了费茨定律,也没有做用户性能测试。你的系统在多大程度上改进了目前的视觉指向系统?一点点?巨大的改善?它对时间有什么作用?更慢?太快了?
- 你没有把性能和可用性联系起来。也许你提高了准确性,但在其他方面使系统变得不那么有用,例如,因为算法消耗了很多内存空间或不能离线使用。
- 您没有衡量与绩效相关的用户满意度。也许您的客户可以接受更多的课程解决方案和时不时的一些失误。改变的需要可能很小
- 如果没有 HCI,您可能会投入大量开发时间来改进某些系统,这会使您的最终产品比现有解决方案更昂贵,并且存在无人等待的风险
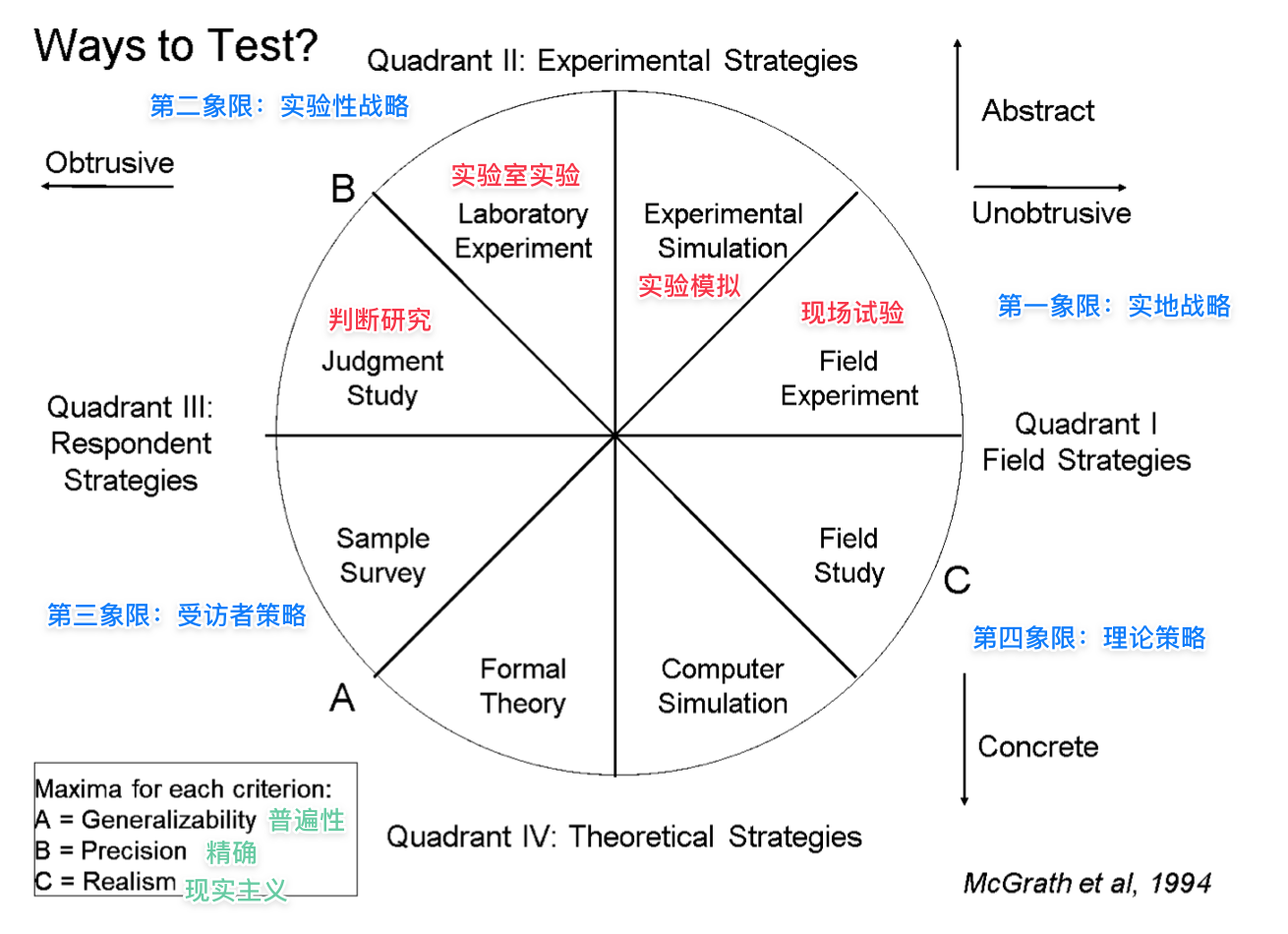
菲茨定律
Fitts 定律指出,一个人将指针(例如,鼠标光标)移动到目标区域所需的时间量是
关于 到目标的距离 除以 目标大小 的函数。
形成性(在系统开发期间,通常基于原型)
- 应用程序的可理解性「Understandability」
- 应用程序的完整性「Completeness」
- 应用程序的质量「Quality」
- 道德审查「Ethical review 」(e.g., health apps)
- 责任和法律 (e.g., self-driving cars)
总结(系统开发后)
- 过程评估(实施良好?)
- 影响「Impact」评估(对用户、其他人的影响)
Basic Concepts
Hypothesis
「假设」
- 假设是一个关于你的系统的精确问题陈述
- 说明「States」各组数据之间的预期统计关系
- 声明「statement」必须准确无误,并说明我们要测量的内容!
案例
- 不够精确: iPhone的键盘比黑莓的键盘好
- 稍微好一点: iPhone的键盘比黑莓的键盘打字更快
- 最精确:人们在 iPhone 键盘上输入短信的时间(以秒为单位)比在黑莓键盘上输入的时间少。
Null Hypothesis
「空白假设、无效假设」
空白假设指出了与预期的统计关系相反的保守「conservatively」说法
- 假设:与黑莓键盘相比,人们在iPhone键盘上输入短信的时间更短(以秒计算)。
- 无效假设:与黑莓键盘相比,人们在iPhone键盘上输入文本信息所需的时间(以秒为单位)持平或更长。
如果观察到的数据显示,这种情况明显不可能发生,那么就拒绝无效假设,接受替代假设。
类似于刑事审判:假定被告是无辜的(原假设),直到被证明有罪(拒绝原假设)排除合理怀疑(在统计上显着的程度)。
Qualitative vs Quantitative Data
「定性与定量数据」
测试可以产生定性的(如字符串)和定量的数据(如整数)。
- Qualitative evaluation「定性评价」
- 衡量标准更加主观和相对(传闻)。
- 给我们案例,数据结构化程度较低,更加多样化
- Quantitative evaluation「定量评价」
- 测量更精确,主观性更低
- 给我们带来更好的可控结果,结构化,更统一
- 更正式的数据,统计分析
“On average, it took users 30% less time to finish a transaction.”
在哪些情况下数字是有用的
- 有效性:任务成功完成率
- 效率:速度和准确性之间的权衡
- 完成任务的时间要求
- 在速度或错误数量上比较两个系统
- 努力: 难度、易用性,但也包括能源消耗
构建与测量,我们能直接测量/观察到它吗?
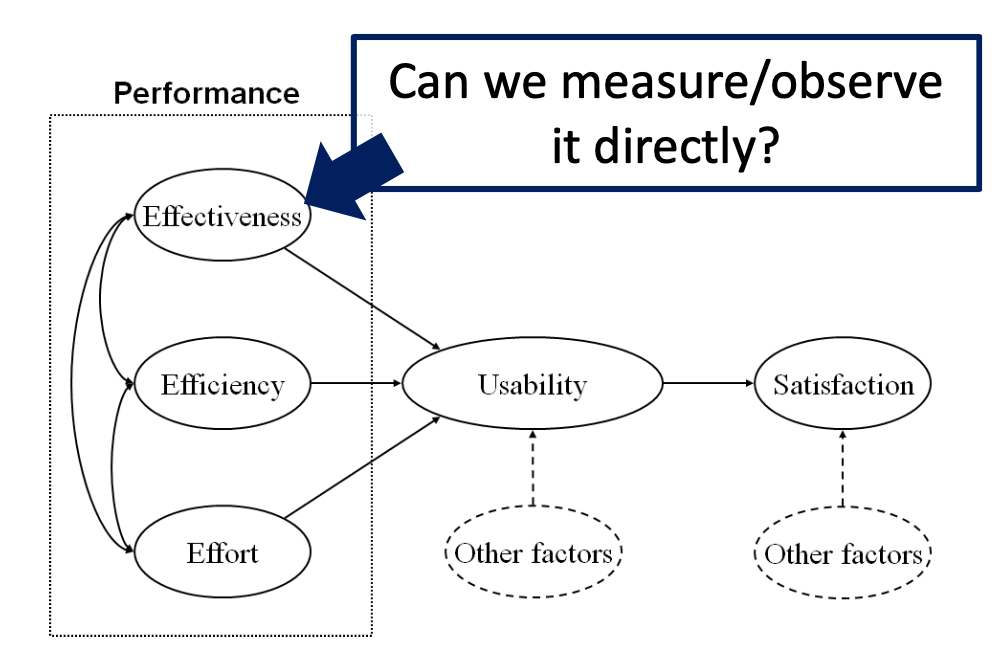
在人机交互研究中,可以很容易地对变量进行量化的例子
- 时间:容易测量,适合统计分析(如学习时间、任务完成时间等)。
- 错误率(系统中某一部分的错误频率)。显示系统中存在问题的地方。建议困难的原因。
- 系统的使用模式(系统的某一部分的使用频率)。研究使用的模式。对特定部分的偏爱和回避。
- 请求帮助的模式(访问在线帮助系统的频率)。研究用户感到困惑的地方。
混乱是你所做的任何应用的第一大不希望看到的效果!
因果变量与独立变量
「Dependent vs Independent Variables」
Independent Variables「独立变量」:由可用性研究人员系统地改变(操纵)的因素。
- 确定了对用户所经历的条件的修改
- 例如,界面类型,给用户的练习或培训
- “人们在 iPhone 上输入短信的时间比在黑莓手机上花的时间少”
- “人们在 10 分钟的教程之后比在 5 分钟的教程之后在执行交易时犯的错误更少”
- 也可能来自人口统计数据
- 例如,用户的性别或年龄
- “女性在使用 Interface A 20 分钟后记住的功能比男性多”
- "与年轻人相比,老年人对陪伴机器人的满意度更高"
Dependent Variables「因果变量」 - 取决于用户的行为或表现
特性有
- 容易观察到的,并且容易与某种测量尺度相关的。
- 稳定可靠,因此它们在恒定(实验)条件下不会发生变化
- 对独立变量的影响很敏感
例如:所犯错误的数量、完成给定任务所花费的时间、从错误中恢复所花费的时间、评分量表上显示的态度
提示
因果变量是由于自变量的操纵而发生变化的变量。这是你感兴趣的测量结果,它 "取决于 "你的自变量。
四种类型的变量
不是所有的变量都是可比较的
Nominal:
- 只有命名的变量(不能排序)。
- 例如,性别、宗教、用户群体等。
Ordinal「顺序」:
- 可以排序的变量(但每个类别之间的差异是未知的)
- 如:用户偏好排名
Interval「比率」:
- 距离是有意义的
- 例如,温度(C)(20C不是10C的 "两倍热")。
Ratio「比率」:
- 距离是有意义的,而且有一个非任意的零。
- 例如,重量、长度、所用时间、温度(K)等。
Data Collection Method
定性评价 - 观察协议加编码方案(以理论为依据)。
- 启发式评估—评估人员检查界面并判断其是否符合公认的可用性原则
- 认知演练—评估人员完成一系列任务并从用户的角度提出一系列问题
- 建设性互动 —当测试对象成对合作解决任务时,提供自然的思维朗读(例如,一个孩子和一个成年人)。
定量评估 - 现场和实验室实验
- 运行一个正式的实验并收集数据
- 如果有一个我们想要评估的具体事物(例如,测试一个假设),回答关于一个理论或系统的目标部分的具体问题,就可以发挥作用。
Heuristic Evaluation
「启发式评估」
Nielsen-Molich启发法指出,一个系统应该
- 适当地、及时地将其状况告知用户。
- 以用户从现实世界的运作方式中理解的方式,并以用户的语言来展示信息。
- 为用户提供控制权,让他们轻松撤销错误。
- 要保持一致,这样用户就不会对不同的词、图标等的含义感到困惑。
- 防止错误--系统应该避免出现错误的条件,或者在用户采取危险行动之前发出警告(例如,"你确定要这样做吗?")。
- 有可见的信息、指示等,让用户认识到选项、行动等,而不是强迫他们依赖记忆。
- 要有灵活性,以便有经验的用户找到更快的方法来实现目标。
- 没有杂乱无章,只包含与当前任务有关的信息。
- 提供有关错误和解决方案的简单语言帮助。
- 在精简的、可搜索的文件中列出克服问题的简明步骤。
Lab Experiment
Definition of an experiment: 实验旨在检验关于一个变量(自变量)对另一个变量(因变量)的作用的假设
在确认性数据分析,或统计假设测试中,我们有
- A hypothesis that we wish to “confirm" or “reject"
- Two sets of measurements of the dependent variable, each corresponding to one configuration of the independent variables
- A process that we will repeat with multiple subjects
- 我们将用一种统计方法来比较多组数据
Preventing confounding and order effects:
Randomization
- 控制自变量X对因变量Y的影响,使影响在各条件(组)之间随机分布。
- 随机分配人们先测试键盘布局A,或先测试布局B(以解决顺序效应)。
- 将人们随机分配到不同的组别中(以解决混杂的影响)
不能消除由于未知差异造成的影响,但确保由于受试者或条件之间的未知差异造成的任何影响是随机的(并将通过统计来解决)。
Counterbalancing
- 减轻主体内实验的顺序效应
- 独立变量在不同科目中以不同顺序变化
- 第 1 组:首先尝试键盘布局 A,然后尝试布局 B
- 第 2 组:首先尝试键盘布局 B,然后尝试布局 A
- 如果存在顺序效应,这将在所有组中分配效应,但不会消除它们
- 但是,如果条件之间的顺序效应不相等,这将失败:例如,键盘布局A比布局B更有效地 "预热 "人们......