计算机文本编码,解码,字典简介
计算机文本编码,解码,字典简介
一个文件不是文本,就是二进制文件。
计算机文本的编码经过 “GUI控制器” 展示为可见字符。
- 计算机编码/计算机编码:0 与 1 形成的不定长组合。
- 可见字符:弘,の,!、e
每一种编码和解码方式都需要依照字典。
平时我们说 一个文件使用了某种编码,就是在说 这个文件应该使用某本字典来解读是正确的。
ASCII 字典
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符字典,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码 或者 ASCII 字典,一直沿用至今。
ASCII 字典 一共规定了128个字符的对应关系,比如
- 空格
SPACE是 32(二进制00100000) - 大写的字母
A是 65(二进制01000001)
这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
下表中是ASCII字典的局部,从左到右转换就是解码 (decode),从右到左就是编码 (encode)。ASCII编码和解码需要依照字典。
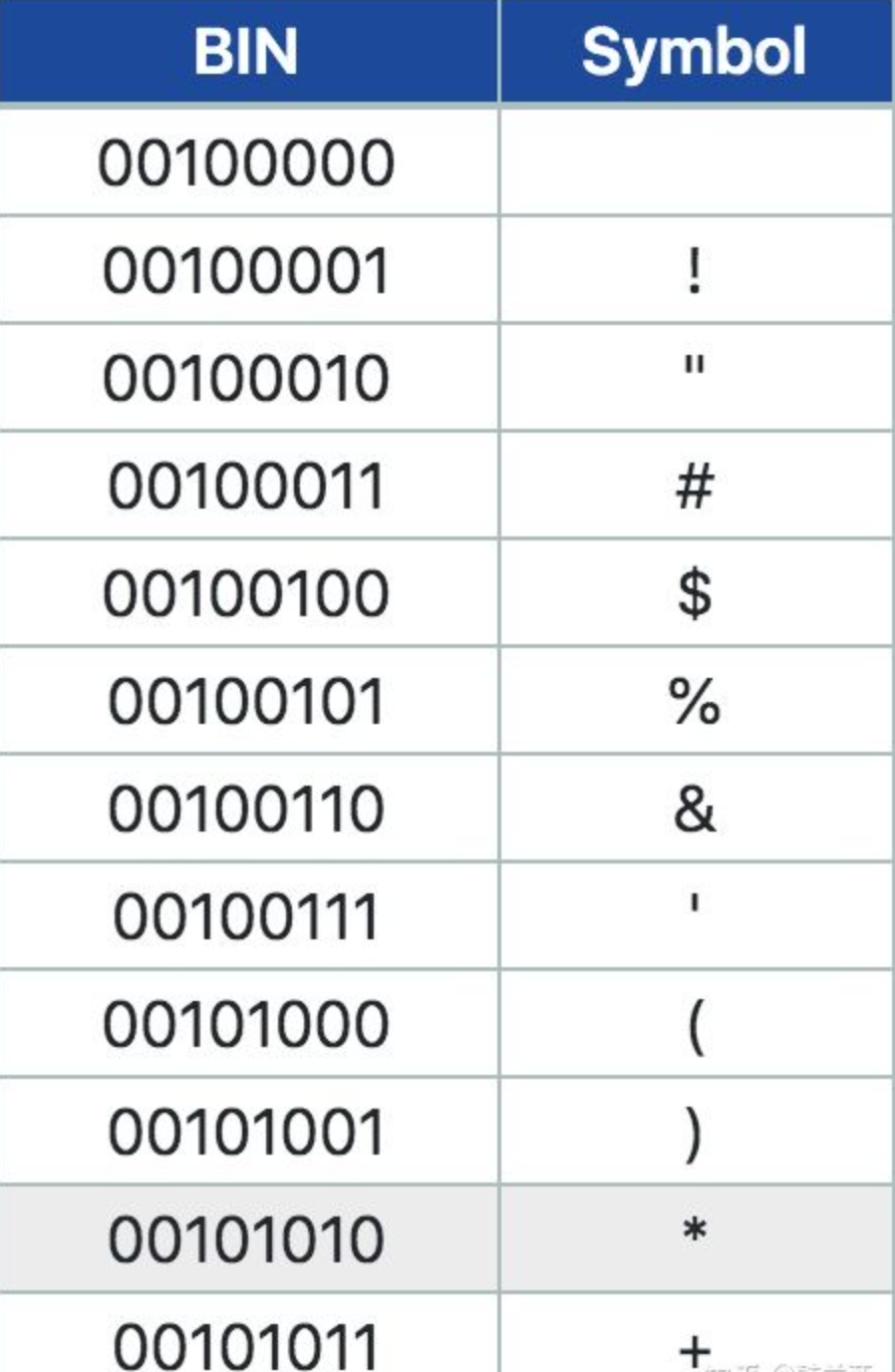
下面是 ASCII 字典
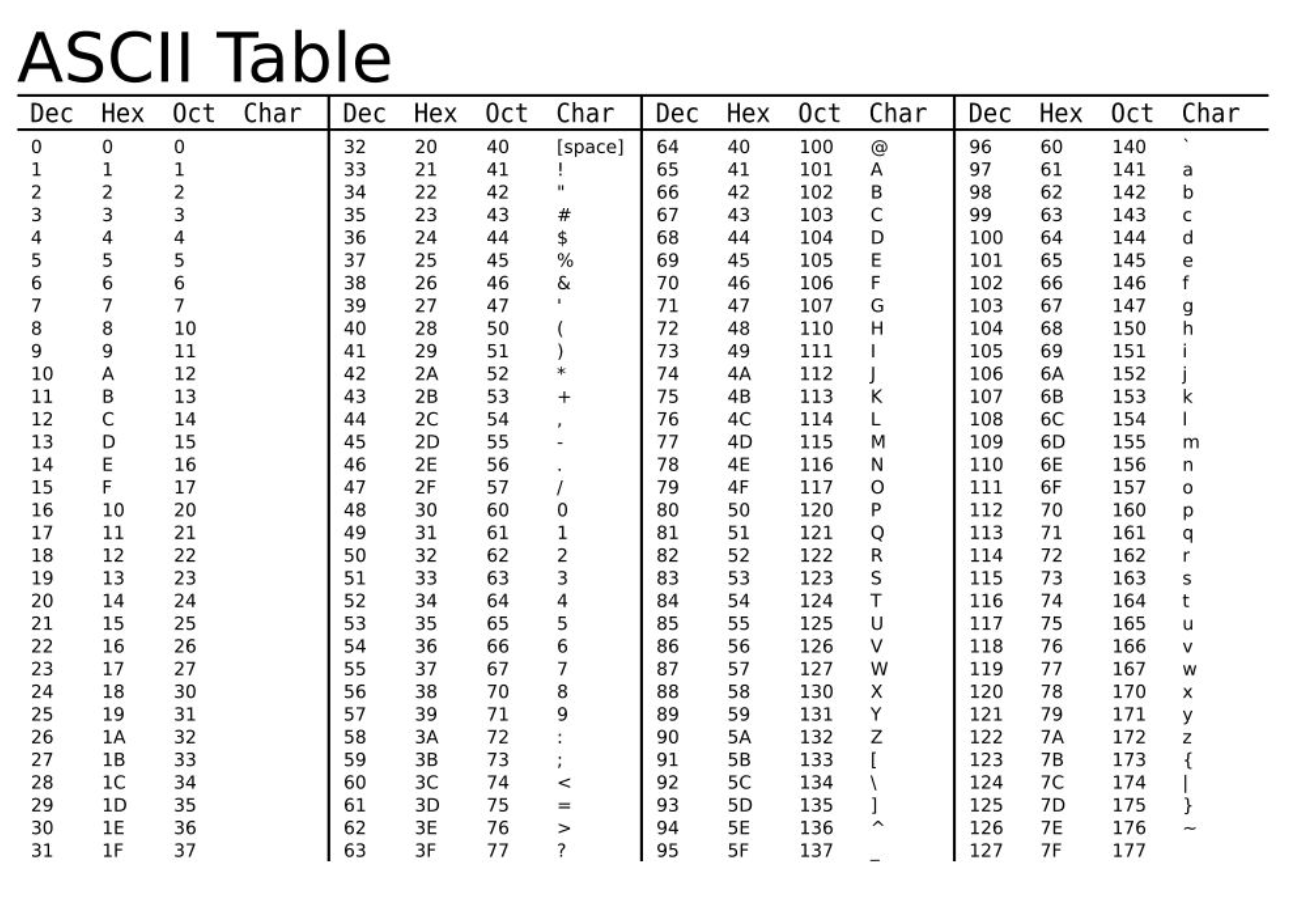
非 ASCII 字典
英语用128个符号就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,
- 130在法语编码中代表了
é, - 在希伯来语编码中却代表了字母
Gimel(ג), - 在俄语编码中又会代表另一个符号。
但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
什么是 Unicode?
为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的字典不一样。
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,即字典,否则用错误的编码方式解读,就会出现乱码。
可以想象,如果有一种字典,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码,或者说是 一本字典。
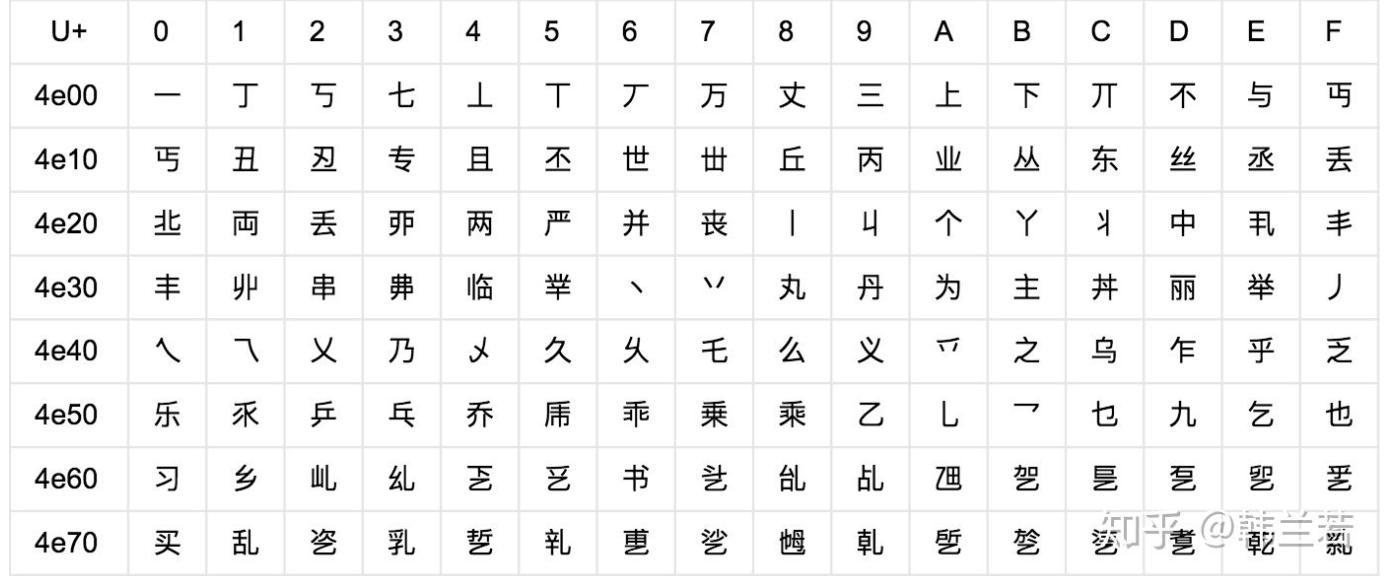
Unicode 字典有两个版本
- UCS-2(Universal Character Set coded in 2 octets),顾名思义,UCS-2是用两个字节来表示一个字符,其取值范围为 U+0000~U+FFFF。
- 为了能表示更多的文字,提出了UCS-4,即用四个字节表示一个字符。它的范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的。
提示
这种说法不太严谨
ISO 10646标准为“通用字符集”(UCS)定义了一种16位的编码形式(即UCS-2),其编码固定占用2个字节,它包含65536个编码空间。为了与Unicode保持相同,0xD800-0xDFFF之间的码位未使用。
UCS-4有20多亿个编码空间,但实际使用范围并不超过0x10FFFF,为了与Unicode保持相同,ISO也承诺将不会为超出0x10FFFF的UCS-4编码赋值。
因此说 UCS 就是 Unicode 字典的两个版本。
Unicode 制定者承诺 Unicode 编码范围不超过 0x10FFFF,即最长序列是17位。
Unicode 序列 分为17个平面(plane),每个平面包含2^16(即65536)个码位(code point)。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从00(16)到10(16),共计17个平面。
Unicode 的实现问题
要注意,UCS-2和UCS-4只规定了二进制序列和文字之间的对应关系,并没有规定序列如何在在硬盘中存储 和 如何在程序中处理,即 Unicode 只是一个符号字典。因为 char单位一般是 8bits = 1 byte (Java 的 char是2字节)。
规定存储方式的称为UTF(Unicode Transformation Format),其中应用较多的就是UTF-16和UTF-8了。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
问题导致:
- 出现了 Unicode 的多种存储方式,也就是说有许多种不同的 二进制格式,可以用来表示 Unicode字符。
- Unicode 在很长一段时间内无法推广,直到互联网的出现。
因此,不妨说Unicode是一本字典,而不用于实际编码。
不过,依照 Unicode 字典,实现了
- UTF-8 编码/解码器
- UTF-16 编码/解码器
- UTF-32 编码/解码器
- ......
UTF-8 编码/解码器
互联网的普及,强烈要求出现一种统一的编码方式。
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 规律很简单,只有二条:
- 对于 单字节 的 符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 - 对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。

比如『汉』这个字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001。
UTF-16 和 UTF-32 编码/解码器
UTF-16 和 UTF-32 都是直接把 Unicode 字典中 字符对应的二进制序列 进行补全后存储。
- UTF-16(一个字符用两个字节或四个字节表示)。
- UTF-32(一个字符用四个字节表示),不过在互联网上基本不用。

比如一个人想写一篇文章,包括英语和日语。依据 Unicode字典,
- 单字节编码可以表示英语,但是显然不能满足他写日语,因为他需要3个字节才能表示一个『あ』,也就是11100011 10000001 10000010。
- 他可以用双字节编码,这样他只需要一个双字节,也就是00110000 01000010。
所以他可以选择语言最高所需要的编码,也就是UTF-16. 如果他只需要写英语, 那UTF-8就可以。
对于中文而言,16bit长的编码里面已经包含了GB18030里面的所有汉字(27484个字),因此使用 UTF-16 比使用 UTF-32 更节省空间。
UTF-16 四字节 编码/解码器
思考 Java char 只能装 2bytes。 如果文件中包含 4字节序列 应该怎么处理?
前面提到过:Unicode编码点分为17个平面(plane),为 0~0x10FFFF,每个平面包含216(即65536)个码位(code point),而
- 第一个平面称为“基本多语言平面”(Basic Multilingual Plane,简称BMP),即 UTF-16 2bytes 可以产生 2^16 = 65536 = 0xFFFF个序列。基本多语言平面”(00xFFFF)中**0xD8000xDFFF**之间的序列作为保留,未使用。
- 其余平面称为“辅助平面”(Supplementary Planes),起始于0x10000 ,终止于0x10FFFF,共有 2^20 = 0xFFFFF个。尽管Unicode保证不会适应 2^17 之后的。
UTF-16 利用保留下来的 0xD800-0xDFFF 区段的码位来对“辅助平面”的字符的码位进行编码。怎么做呢?
对于“辅助平面”内的字符来说,0x10000 - 0x10FFFF 共计0xFFFFF = 2^20 个可以用 长为20的二进制序列表示。就将这个范围偏移0x10000,即得一个0~0xFFFFF的区间。即让这个数字 减去 0x10000,之后
- 该数字的前10位(bits)加上0xD800,就得到UTF-16四字节序列中的 前两个字节;
- 该数字的后10位(bits)加上0xDC00,就得到UTF-16四字节编码中的后两个字节。
来看下面这个字,
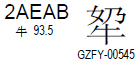
上面这个汉字的Unicode码位值为2AEAB,
- 减去0x10000得到1AEAB(二进制值为0001 1010 1110 1010 1011)
- 前10位加上D800得到D86B
- 后10位加上DC00得到DEAB。
于是该字的UTF-16编码值为D86BDEAB,该值为大端表示,小端为6BD8ABDE)。
Java使用USC2版UTF-16/Unicode 编码。在Java中,使用两个UCS2字符,即2个char表示4字节的字符。
比如,The unicode value of ucs-4 character '🤣' is 0001f923, it gets auto changed to the corresponding value of \uD83E\uDD23 when printing.
public static void main(String[] args) {
int input = 0x1f923;
int x = input - 0x10000;
int highTenBits = x >> 10;
int lowTenBits = x & ((1 << 10) - 1);
int high = highTenBits + 0xd800;
int low = lowTenBits + 0xdc00;
System.out.println(String.format("[%x][%x]", high, low));
}
Unicode 编码/解码器
前面说,Unicode 只能说是字典,不能说是编码解码方式。然而,某些地方还在不严谨的说 某某文件是 Unicode 编码。这里所说的 Unicode 编码,通常是指某种 UTF-16。
- Windows 记事本 中所说的 Unicode编码 是指 Little Endian 的UTF-16。
- 其他平台,如果直说是 Unicode编码而不具体说是哪一种,可认为在指 某种 UTF-16。
下面解释了什么是 Big Endian 和 Little Endian。
内存中的 UTF-16
为什么会 UTF-16 还有很多种 ?二进制 值 非0即1。我们要思考如何将 序列补全成为8的倍数。只有这样才能用于处理和存储。
内存中的UTF-16编码包括三种:UTF-16,UTF-16BE(Big Endian),UTF-16LE(Little Endian)。
比如 UTF-16 的 0xabcd, 以下这种存储格式为Big Endian,因为值(0xabcd)的高位(0xab)存储在前面:
| 地址 | 值 |
|---|---|
| 0x00000000 | AB |
| 0x00000001 | CD |
相反,以下这种存储格式为Little Endian:
| 地址 | 值 |
|---|---|
| 0x00000000 | CD |
| 0x00000001 | AB |
文件中的 UTF-16
很自然的,会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
这就需要通过在文件开头以名为BOM(Byte Order Mark)的字符来表明文件是Big Endian 还是 Little Endian。
- 如果一个文本文件的头两个字节是
FE FF,就表示该文件采用大头方式; - 如果头两个字节是
FF FE,就表示该文件采用小头方式。
举个例子,“ABC”这三个字符用各种方式编码后的结果如下:
| 文件编码方式 | 编码 |
|---|---|
| UTF-16BE | 00 41 00 42 00 43 |
| UTF-16LE | 41 00 42 00 43 00 |
| UTF-16(Big Endian) | FE FF 00 41 00 42 00 43 |
| UTF-16(Little Endian) | FF FE 41 00 42 00 43 00 |
| UTF-16(不带BOM) | 00 41 00 42 00 43 |
看文件存储的真实实例
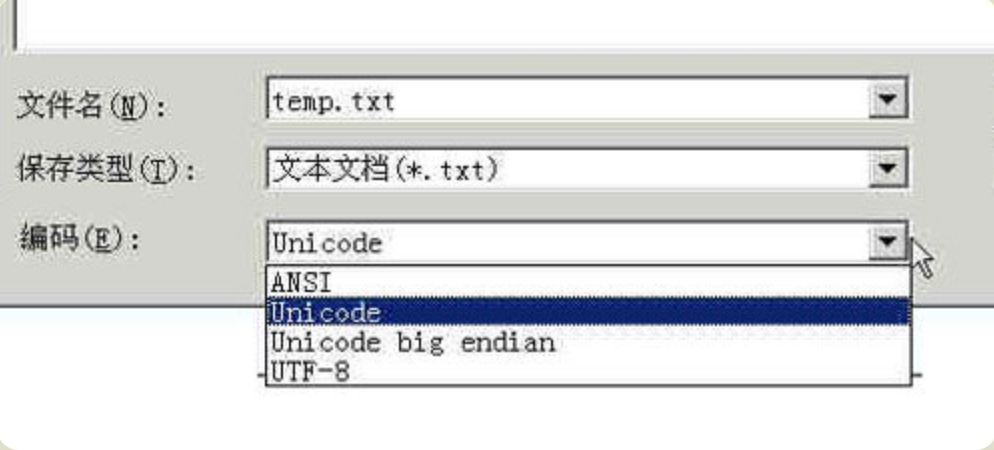
打开 Windows "记事本" 程序notepad.exe,新建一个文本文件,内容就是一个严字。用下面的编码方式保存
- Unicode (UTF-16 Little Endian):存储的编码是4个字节
FF FE 25 4E- 其中
FF FE表明是 Little Endian 存储。
- 其中
- Unicode Big Endian:存储的编码是4个字节
FE FF 4E 25FE FF表明是 Big Endian 存储。
- UTF-8:存储的编码是6个字节
EF BB BF E4 B8 A5EF BB BF表示这是UTF-8编码。
需要注意的是,这里的 BOM 是 Unicode 系列专有的。
文件中的 UTF-32
| 文件编码方式 | 编码 |
|---|---|
| UTF-32BE | 00 00 00 41 00 00 00 42 00 00 00 43 |
| UTF-32LE | 41 00 00 00 42 00 00 00 43 00 00 00 |
| UTF-32(Big Endian) | 00 00 FE FF 00 00 00 41 00 00 00 42 00 00 00 43 |
| UTF-32(Little Endian) | FF FE 00 00 41 00 00 00 42 00 00 00 43 00 00 00 |
| UTF-32(不带BOM) | 00 00 00 41 00 00 00 42 00 00 00 43 |
编码之间的的转换
严的 Windows-Unicode 码 是4E25,UTF-8 编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
Windows平台,有一个最简单的转化方法,就是使用内置的记事本小程序notepad.exe。打开文件后,点击文件菜单中的另存为命令,会跳出一个对话框,在最底部有一个编码的下拉条。
对比
| 对比 | UTF-8 | UTF-16 | UTF-32 | UCS-2 | UCS-4 |
|---|---|---|---|---|---|
| 编码空间 | 0-10FFFF | 0-10FFFF | 0-10FFFF | 0-FFFF | 0-7FFFFFFF |
| 最少编码字节数 | 1 | 2 | 4 | 2 | 4 |
| 最多编码字节数 | 4 | 4 | 4 | 2 | 4 |
| 是否依赖字节序 | 否 | 是 | 是 | 是 | 是 |
Reference
https://zhuanlan.zhihu.com/p/137875615
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://blog.csdn.net/imxiangzi/article/details/77371228
https://www.cnblogs.com/malecrab/p/5300503.html
https://www.zhihu.com/question/39262026/answer/127103286
https://stackoverflow.com/questions/57954090/convert-ucs-4-to-ucs-2