Dimensionality Reduction
大约 7 分钟
Dimensionality Reduction
- 假设:数据位于或接近一个低d维的子空间上
- 这个子空间的红轴是数据的有效代表
- 降维的目标是发现数据的红轴
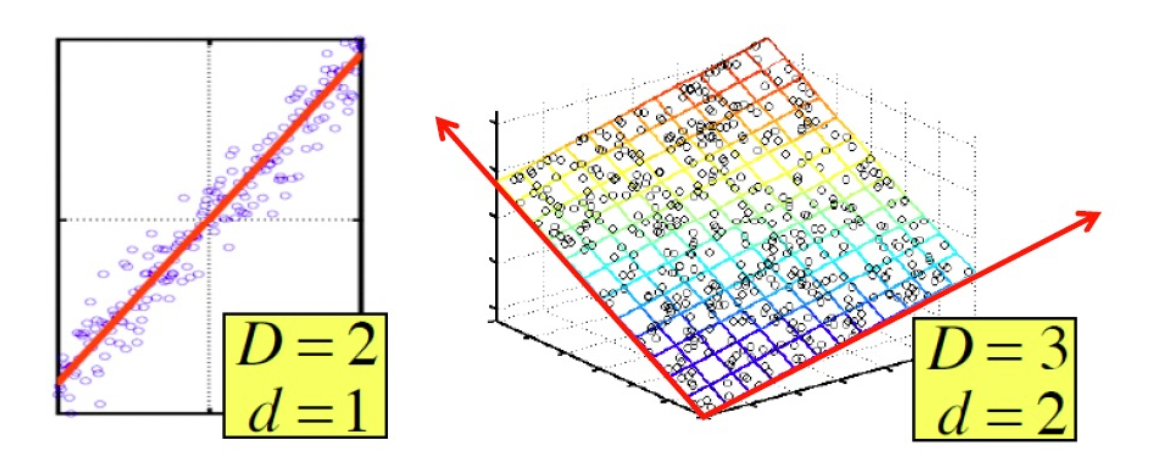
- 我们不是用2个坐标来表示每个点,而是用1个坐标来表示每个点(对应于红线上的点的位置)。
- 这样做我们会产生一点误差,因为这些点并不完全位于直线上。
Why
- 数据以前所未有的速度积累
- 数据预处理是有效的机器学习和数据挖掘的一个重要部分
- ML 和 DM 技术可能对高维数据无效
- 降维是缩小数据规模的一种有效方法
- 内在维度可能很小
- 发现隐藏的相关性/主题,例如,经常一起出现的词
- 去除冗余和嘈杂的特征,例如,并非所有单词都有用
- 解释和可视化
- 更容易存储和处理数据
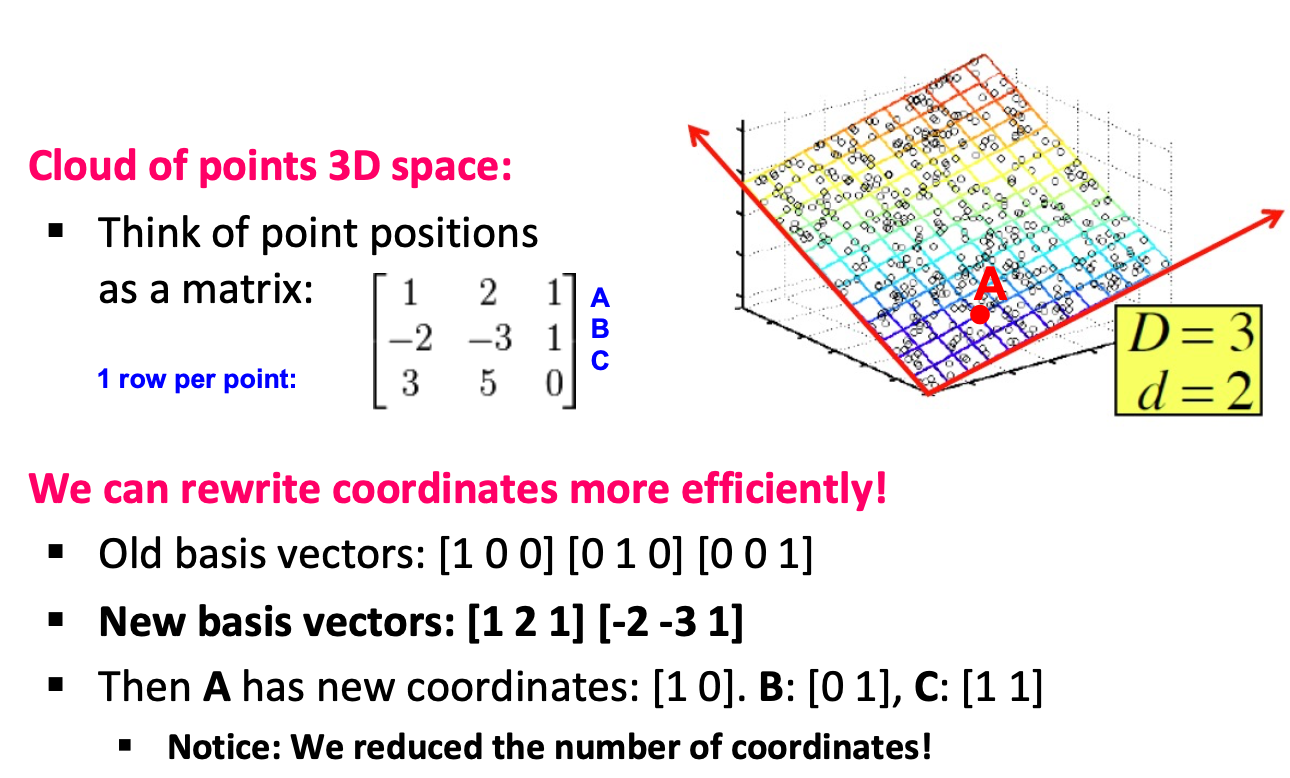
Rank of a Matrix
- Q: What is rank of a matrix A?
- A的线性独立列的数量
Latent Factor Models
SVD: A = U Σ VT

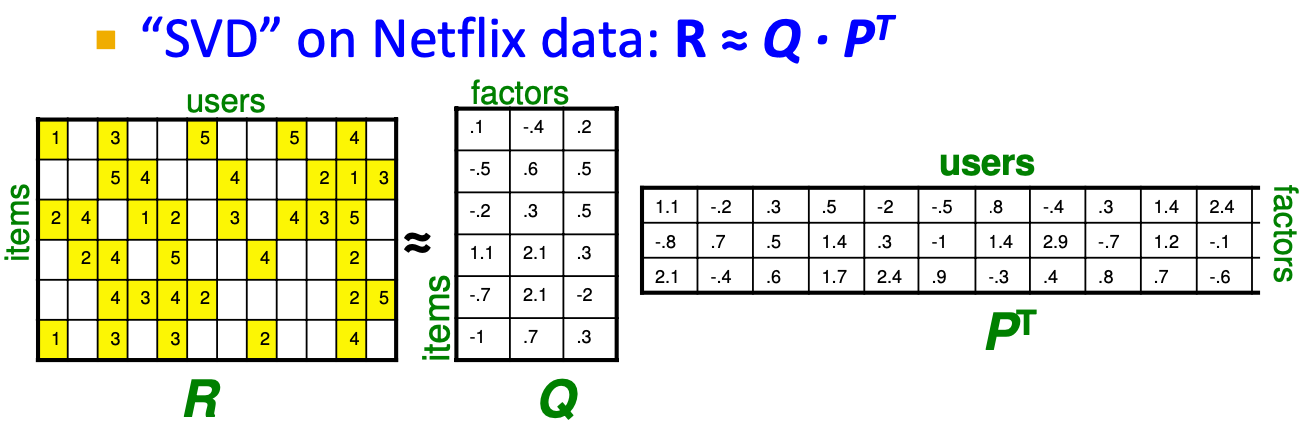
以因子的内积来估计未知的评级
Singular Value Decomposition
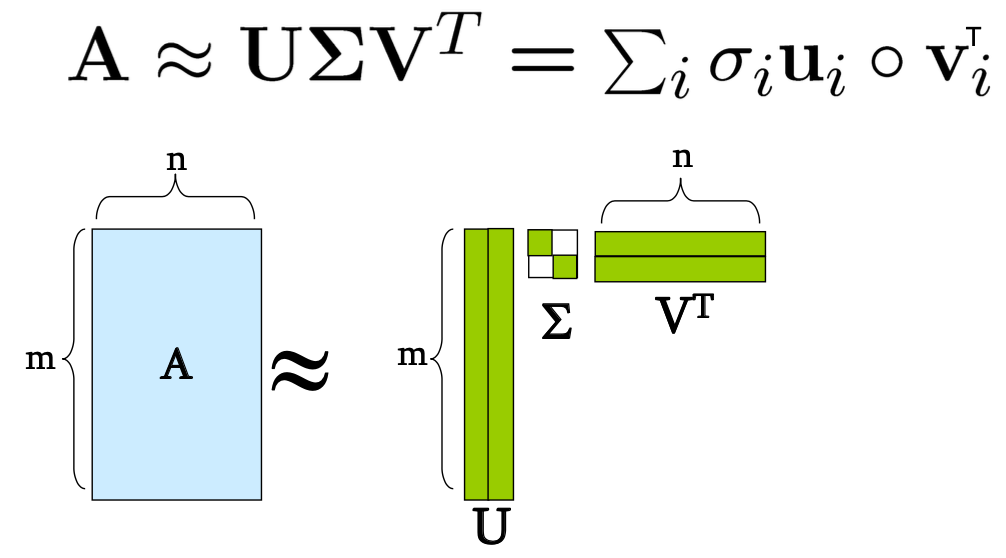
Properties
始终有可能将一个真实的 matrix A into A = U Σ VT ,where
- U, Σ**, V**: unique
- U,V:柱状正态「column orthonormal」
- UT U=I;VUT V=I (I: identity matrix)
- 列是正交的单位向量
- Σ: diagonal
- 条目(奇异值)为正数,并按递减顺序排序 (σ1 >= σ2 >= σ3 ... >= 0)
Definition
- A: Input data matrix
- m x n矩阵(例如,m个文件,n个术语)。
- U: Left singular vectors
- m x r矩阵(m文件,r概念)。
- Σ: Singular values
- r x r对角线矩阵(每个 "概念 "的强度)。
- (r : 矩阵A的 rank)
- V: Right singular vectors
- n x r matrix (n terms, r concepts)

DR with SVD
- 与其使用两个坐标(𝒙,𝒚)来描述点的位置,不如只使用一个坐标𝒛
- 点的位置是它沿着矢量𝒗𝟏的位置
- 如何选择𝒗𝟏?
- 最大限度地减少重建误差
目标:使重建误差之和最小化
where 𝒙𝒊𝒋 are the “old” and 𝒛𝒊𝒋 are the “new” coordinates
SVD给出了投射的 "最佳 "轴:'最佳'=最大限度地减少重建误差
换言之,最小重建误差