Recommendation System
大约 11 分钟
Recommendation System
Content Based (CB)
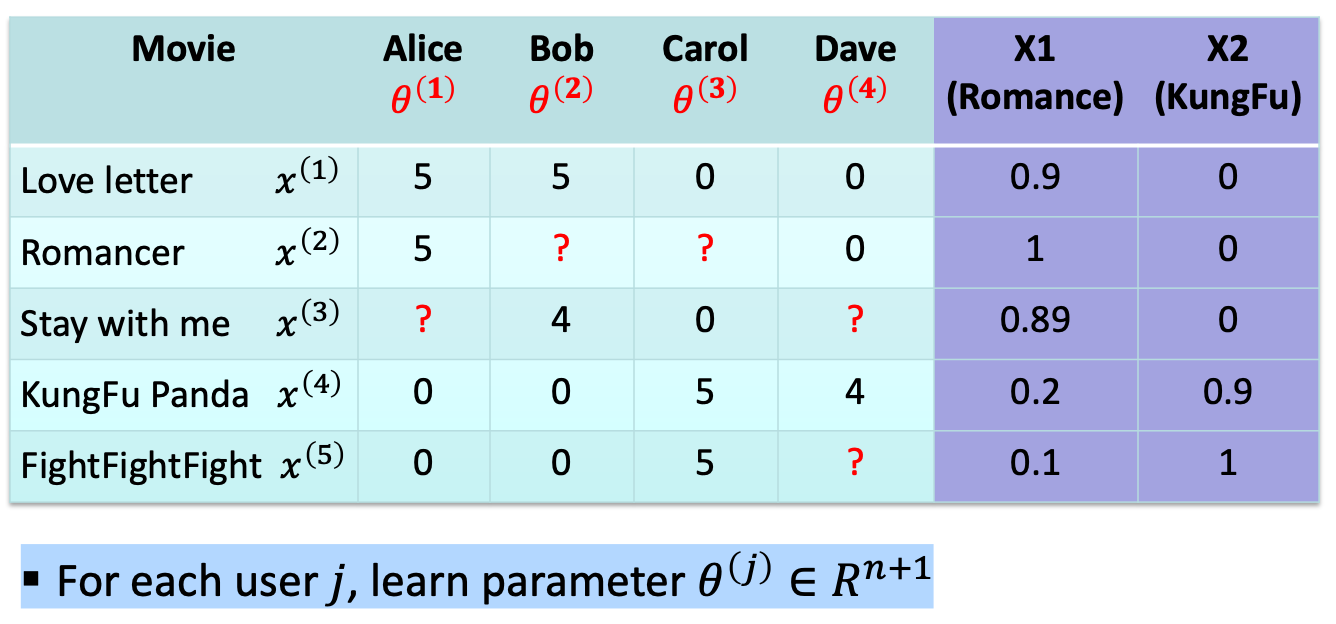
Objective
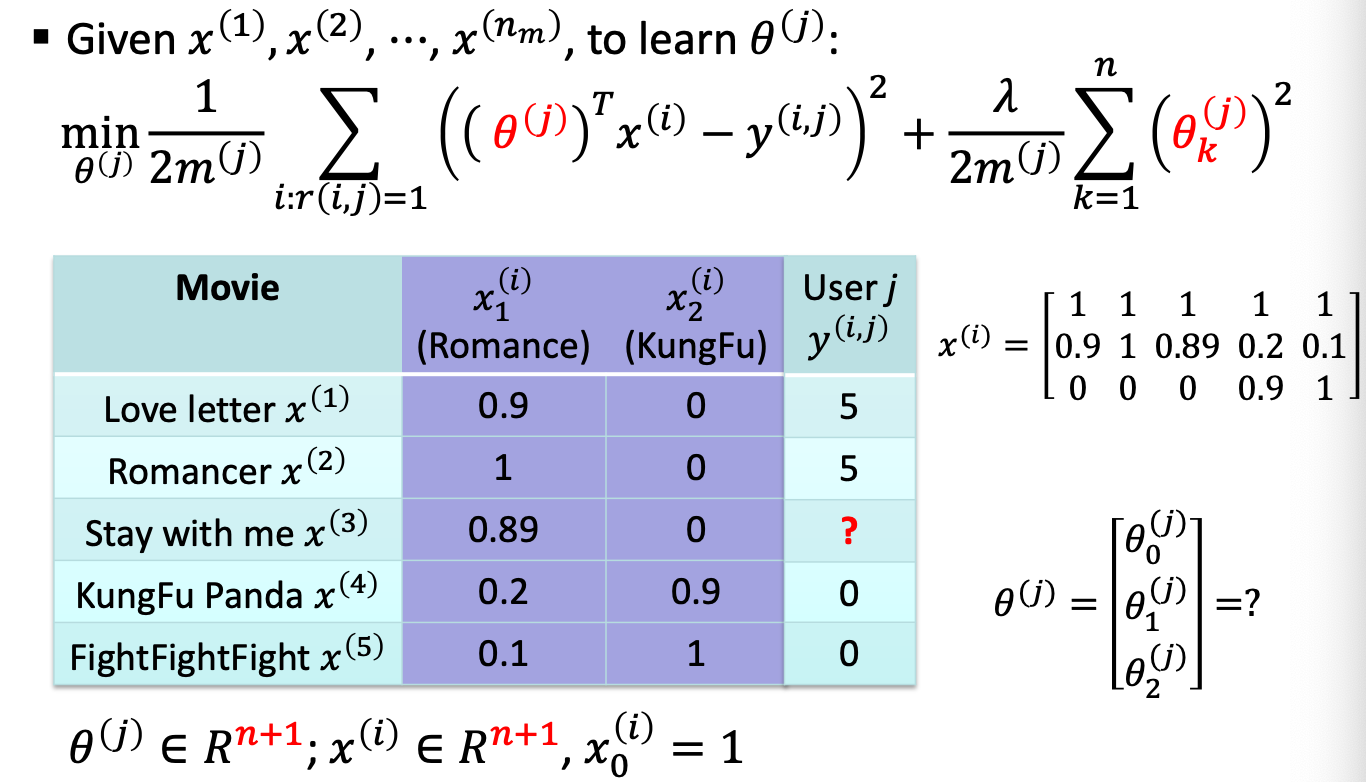
Objective in general
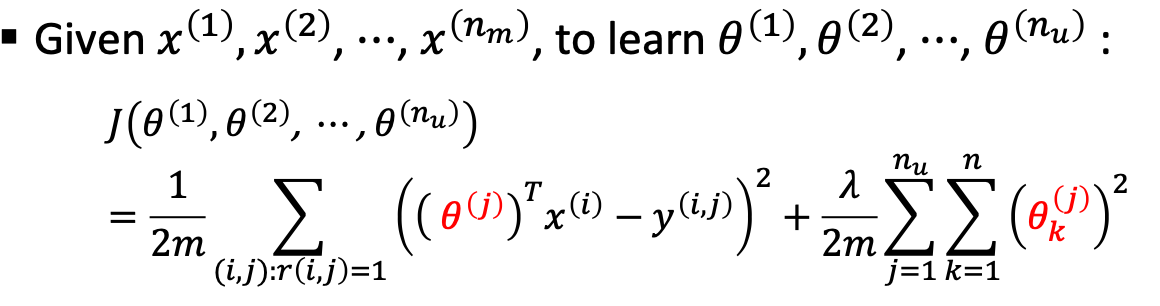
Pros
- 不需要其他用户的数据
- 能够向具有独特品味的用户推荐
- 能够推荐新的和不受欢迎的项目:没有冷启动项目问题
- 能够提供解释:可以通过列出导致项目被推荐的内容特征来提供对推荐项目的解释。
Cons
- 很难找到合适的特征:E.g., images, movies, music
- 给新用户的建议:如何建立一个用户档案?
- 过度专门化
- 从不推荐用户内容资料之外的项目
- 人们可能有多种兴趣
- 无法利用其他用户的质量判断
Collaborative Filtering (CF)
如果C和D都喜欢《功夫熊猫》,不喜欢《情书》,那么当C把新电影《搏击》评为好的时候,它就会向D推荐这部电影。
It learns feature itself - “Feature Learning”
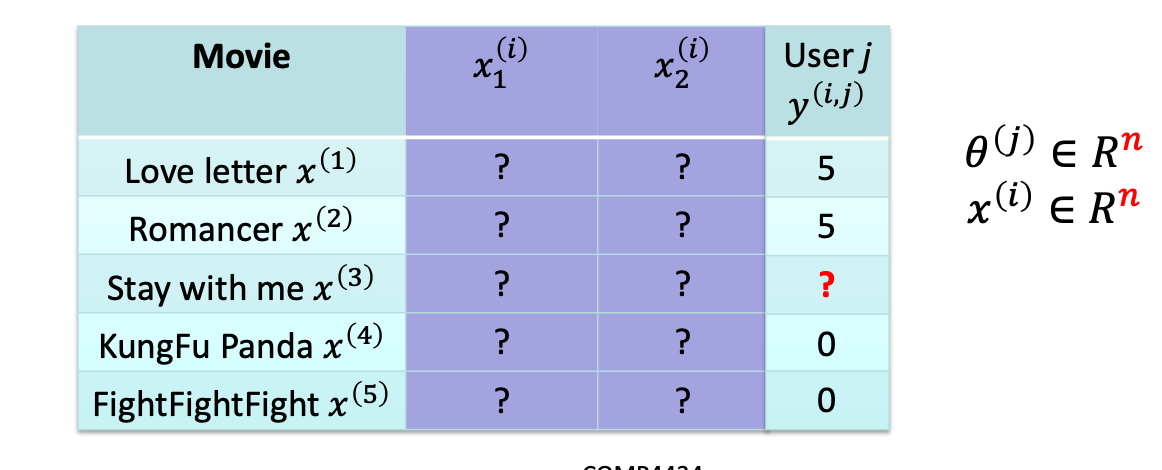

Process
Initialize: to small random values
Minimize using gradient decent
For a user with parameters 𝜃 and a movie with learned
features 𝑥, predict a rating of 𝜃T𝑥
Gradient Descent Update
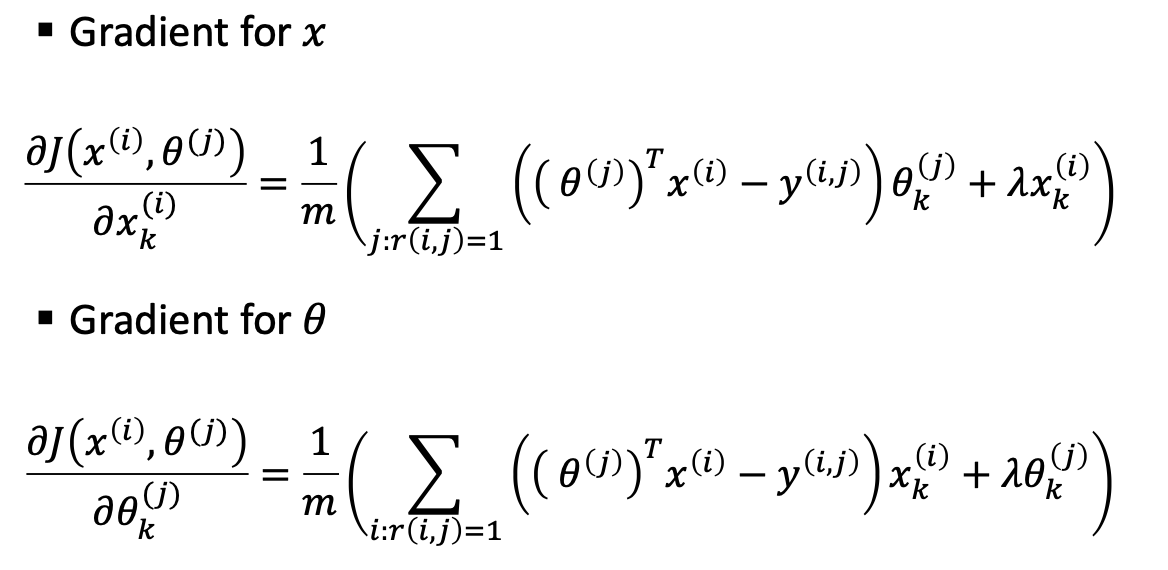

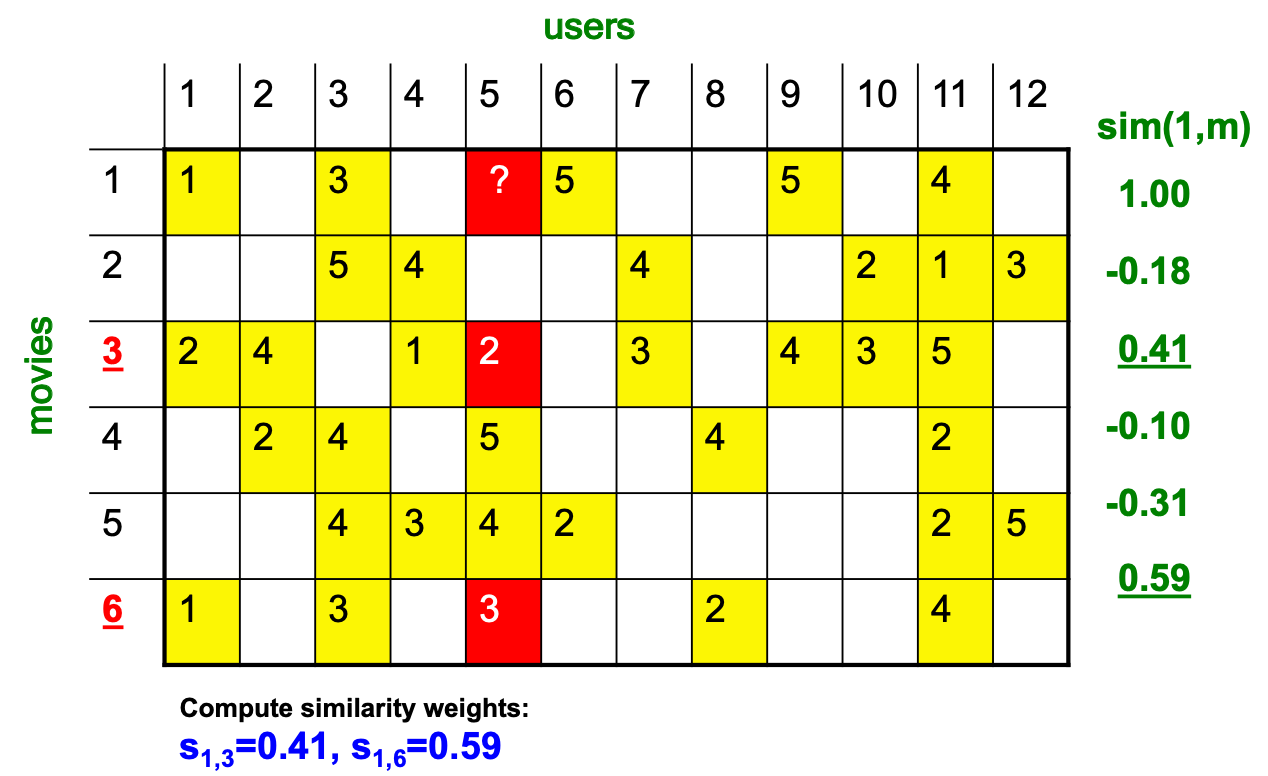
CF: Find “Similar” Users
rx =[*,_,_,*,***]ry =[*,_,**,**,_]
Let rx be the vector of user x's ratings
相关信息
在下面的脚注中,x 与 y 分别表示不同用户,而 i 表示 第 i 个 item。
Jaccard similarity measure
- Problem: Ignores the value of the rating
- Jaccard(A, B) = (A ∩ B) / (A ∪ B)
Cosine similarity measure
Problem: Treats missing ratings as “negative”
Pearson correlation coefficient
- Sxy = items rated by both users x and y
- -> avg. rating of x, y

提示
- 当皮尔逊相关系数为1时,表示两个变量之间存在完全正相关的线性关系;
- 当皮尔逊相关系数为-1时,表示两个变量之间存在完全负相关的线性关系;
- 当皮尔逊相关系数接近0时,表示两个变量之间没有或者只有很弱的线性关系。
一个正的皮尔逊相关系数表示两个用户在评分方面的趋势相似,而负值表示他们的评分趋势相反。
Rating Predictions
- 令 rx 为用户 x 评分的向量
- 设 N 为与 x 最相似的 k 个用户的集合,他们对项目 i 进行了评分
对用户x的项目i的预测:
选项1:
选项2:
Shorthand: S𝒙𝒚 = 𝒔𝒊𝒎 (𝒙, 𝒚)
CF: Item-Item
另一种观点:Item - item
- 对于项目i,找到其他类似的项目
- 根据相似项目的评分估计项目 i 的评分
- 可以使用与用户-用户模型中相同的相似度量和预测功能
- sij... 项目i和j的相似性
- rxj...用户u对项目j的评价
- N(i;x)... set of items rated by x similar to i
For example,
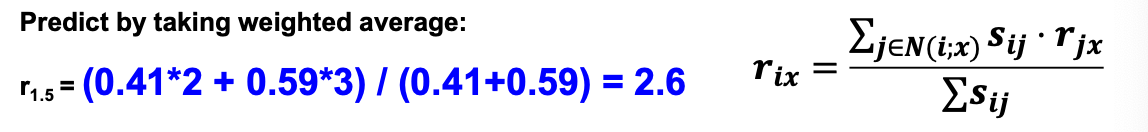
Common Practice in CF
- Define similarity Sij of items i and j
- Select k nearest neighbors N(i; x)
- tems most similar to i, that were rated by x
- 将评分 rxi 估计为加权平均值
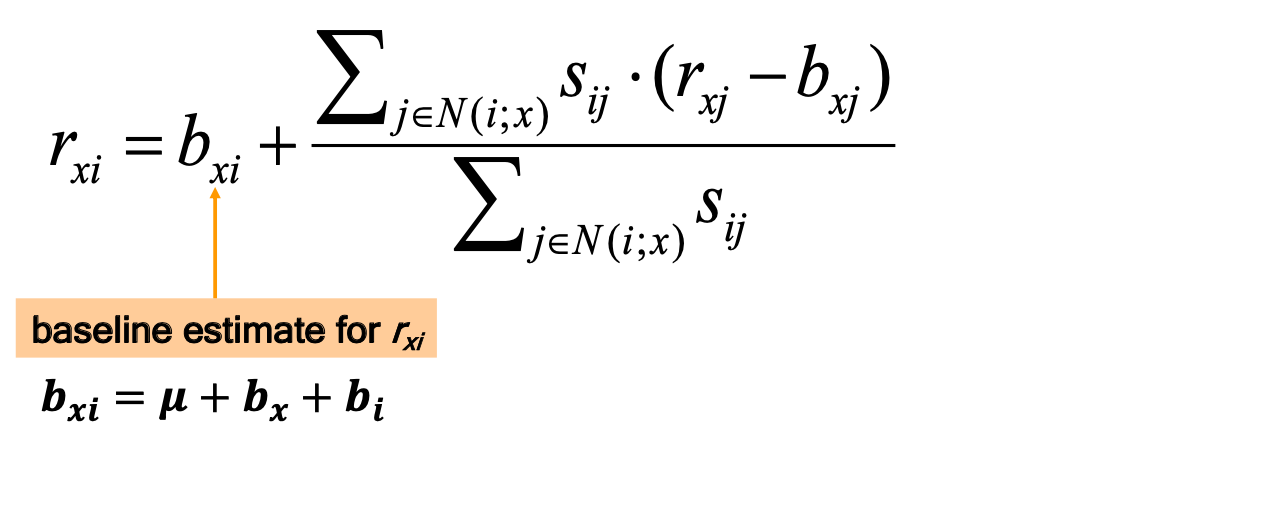
- μ = 总的平均电影评分
- bx= 用户 x 的评级偏差 = (avg. rating of user x) – μ
- bi= 电影 i 的评分偏差 = (avg. rating of movie i) – μ
In practice, it has been observed that item-item often works better than user-user, since Items are simpler, users have multiple tastes
Pros/Cons:
- 适用于任何类型的物品: No feature selection needed
- Cold Start: 需要系统中有足够的用户才能找到匹配项
- Sparsity「稀缺性」
- 用户/评分矩阵是稀疏的
- 很难找到给相同项目评分的用户
- 第一评分人
- 不能推荐以前没有被评级的项目
- 新项目,神秘「Esoteric」的项目
- Popularity bias
- 不能向有独特品味的人推荐物品
- 倾向于推荐受欢迎的项目