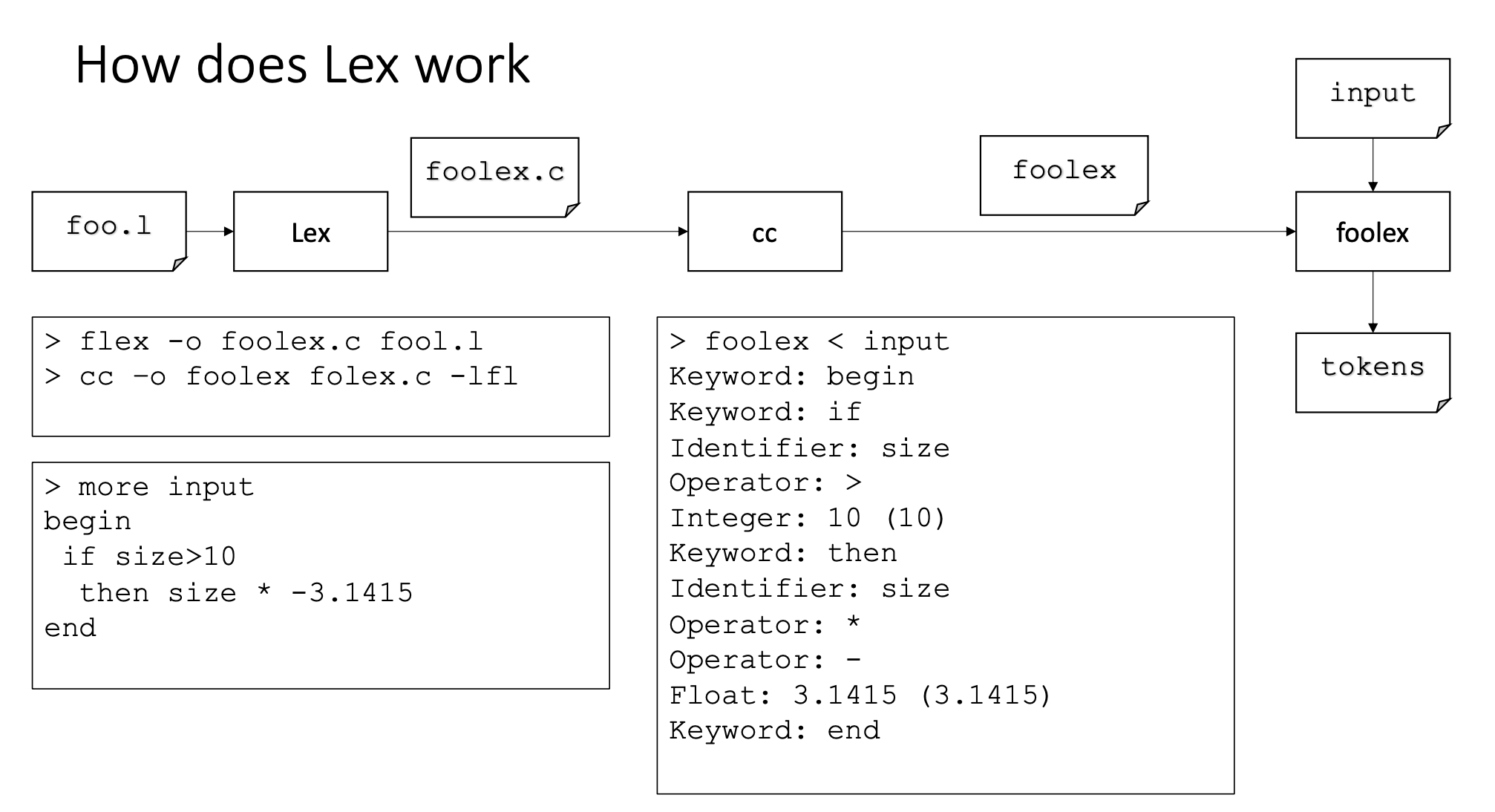
Lexical Analysis
大约 6 分钟
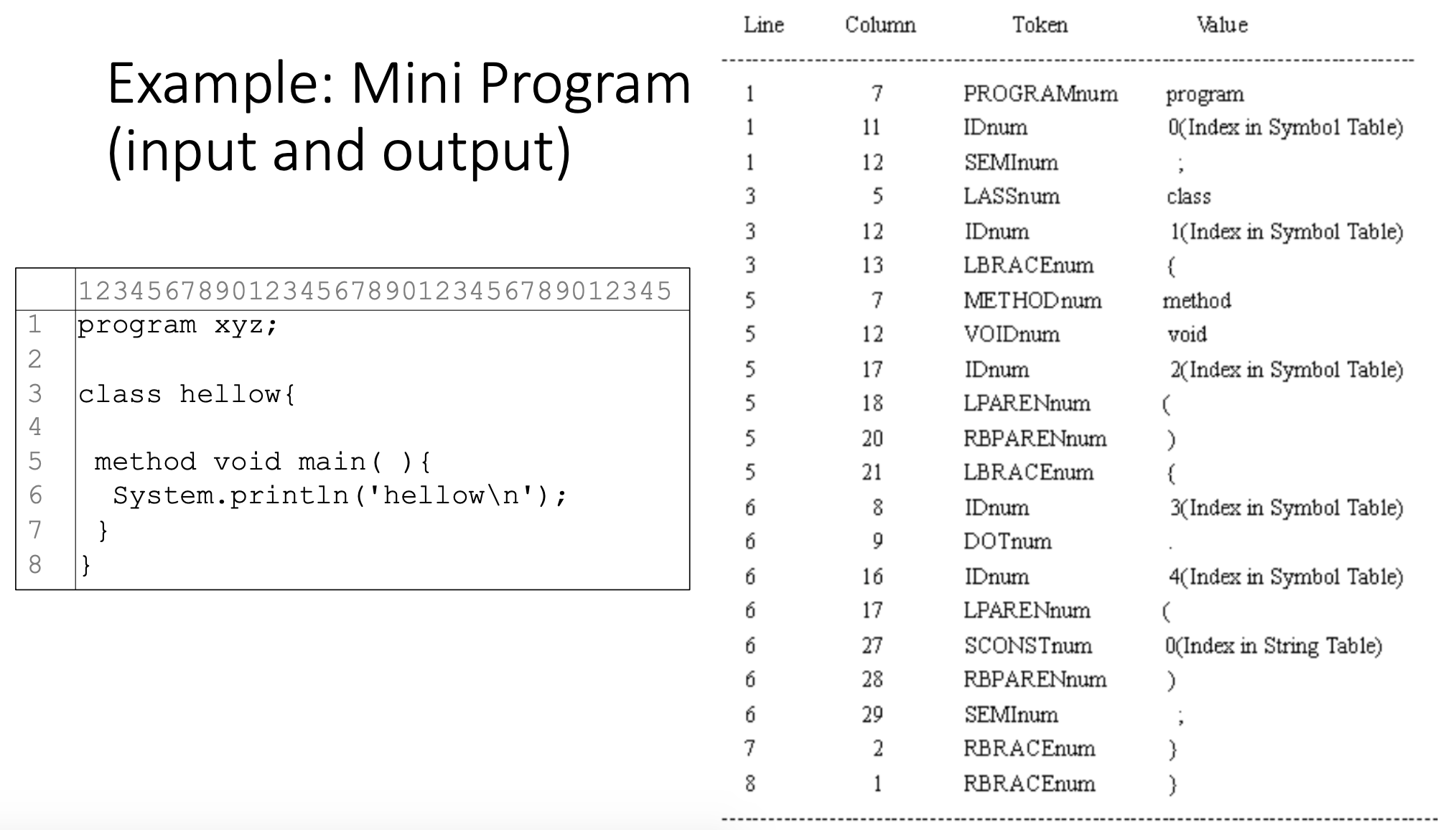
Lexical Analysis
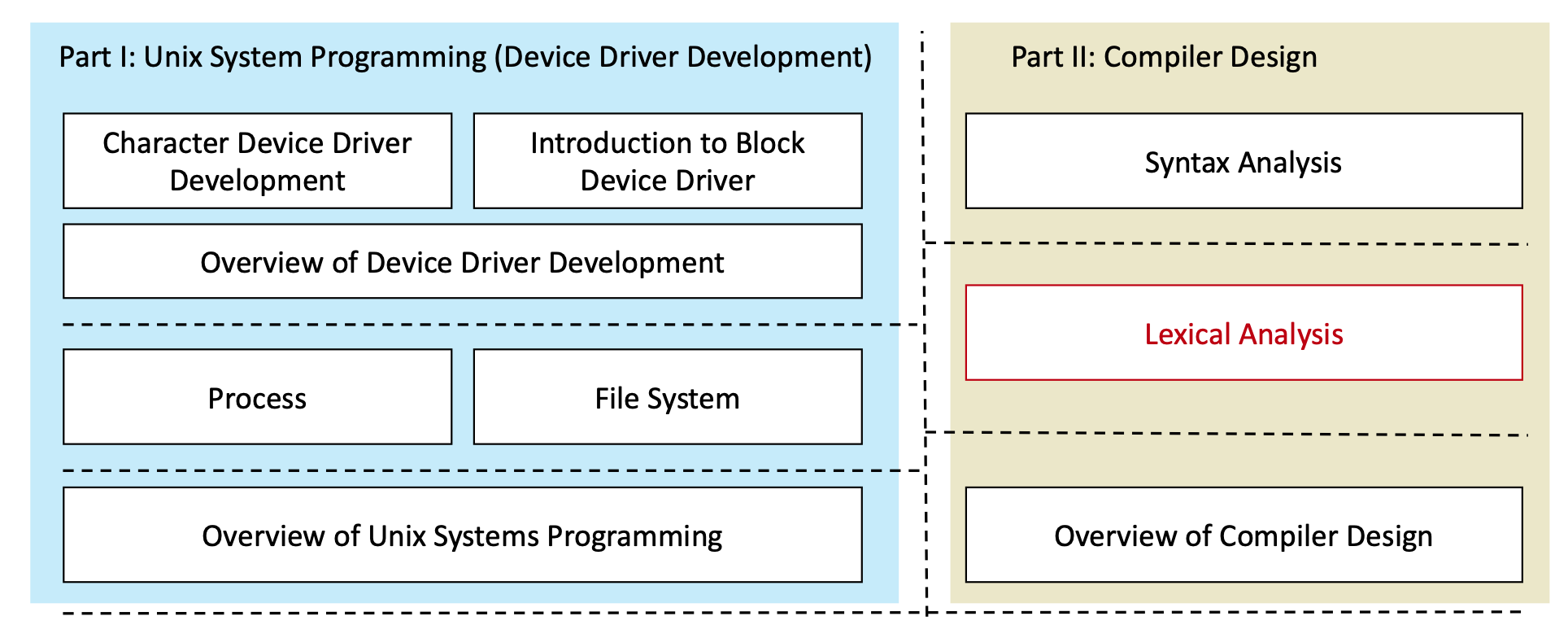
Introduction
- Why we need lexical analysis? Its input and output.
- How to specify「指定」 tokens: Regular Expression
- Regular Expression -> Lex (software tool)
- Regular Expression -> Finite Automata
为何需要词法分析
为什么我们需要词汇分析?给定一个程序,如何将这些字符分组为有意义的 "单词"?
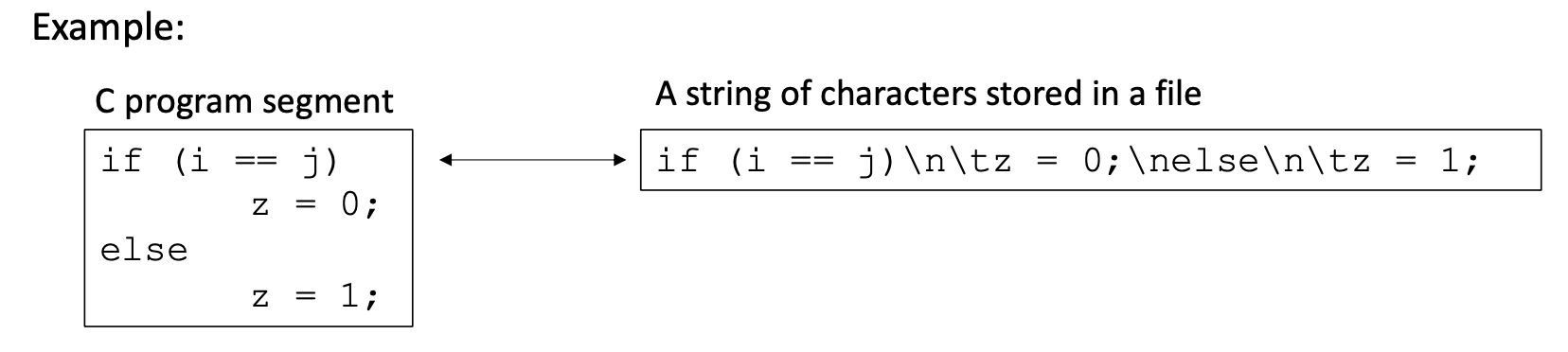
如何从字符串中识别 "if""else "是关键词;"i""j""z "是变量;等等?
In lexical analysis, a source program is read from left-to-right and grouped into tokens. A token is a sequence of characters with a collective meaning.「在词法分析中,源程序被从左到右阅读,并被分组为 token 。token 是一串具有集体意义的字符。」
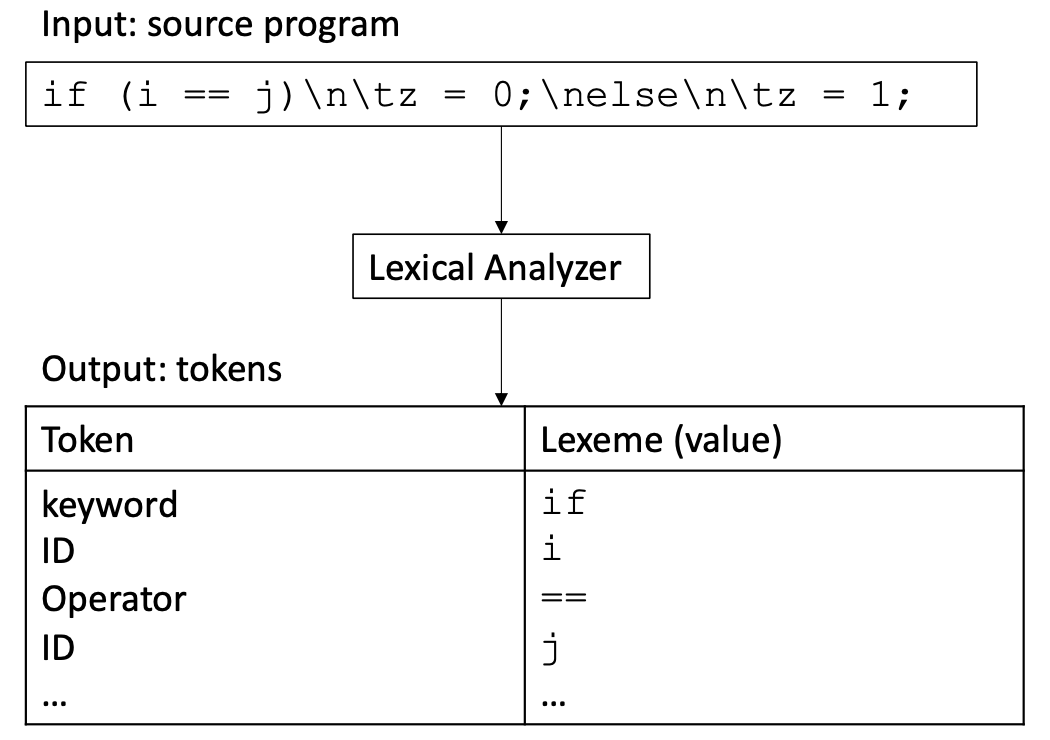
What is a token
- A syntactic category
- In English: a noun, a verb, an adjective, ...
- In a programming language: an identifier, an integer value, a keyword, a white space, ...
Tokens correspond to sets of strings with a collective meaning「标记对应于具有集体意义的字符串集」
- identifier: strings of letters and digits, starting with a letter
- Integer value: a non-empty string of digits
- Keyword: else, if, where, ...
For example,

What are tokens for
根据句法作用对程序子串进行分类。「Classify program substrings according to their syntactic role.」
As the output of lexical analysis, tokens are the input to the parser (syntax analysis)
- Parser relies on token distinctions「解析器依赖于标记的区分」
- e.g., a keyword is treated differently than an identifier.
How to recognize
- 首先,使用正则表达式(模式)指定标记
- 第二,基于正则表达式,有两种方法来实现词法分析器。
- Method 1: use Lex, a software tool
- Method 2: use finite automata (write your own program)「使用有限自动机(自己写程序)」
Specifying tokens
- 一个标记由一个模式指定:一套描述标记形成的规则。
- 词汇分析器使用该模式来识别词素:输入中与该模式相匹配的字符序列。一旦匹配,相应的标记就会被识别。
Example:
标识符的规则(模式):字母后跟字母和数字
Abc1 和 A1 By 匹配规则(模式),因此它们是标识符标记;
1 A 与规则(模式)不匹配,因此因此它不是标识符标记;
Implementation
在获得正则表达式后,我们有两种方法来实现词法分析器「lexical analyzer」。
Use tools: lex (for C), flex (for C/C++), jlex (for Java)
- 使用正则表达式指定标记
- Tool generates source code for the lexical analysis
使用正则表达式和有限自动机
- 写代码表达对token的识别
- Table drivern