用 Canal 实现异构数据库同步
大约 9 分钟
用 Canal 实现异构数据库同步
什么是异构数据
- 定义:异构数据指的是结构不同的数据。
- 例子:在实际工作中,数据主要存储在 MySQL 中,但 MySQL 在进行全文检索时性能不佳,这时通常会使用 Elasticsearch 或 Solr 这样的全文检索引擎。
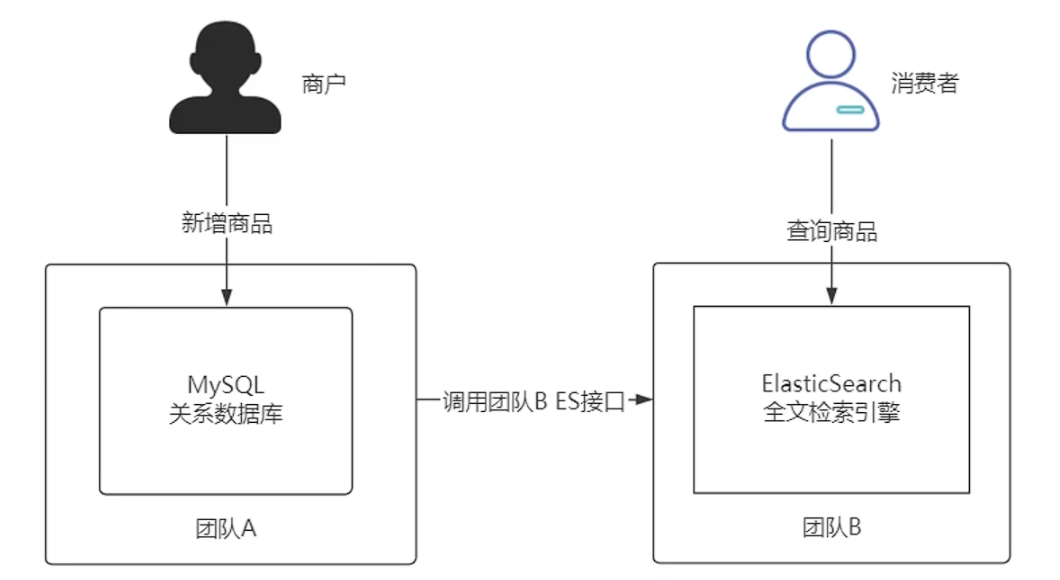
异构数据的实际应用场景 -> 电商平台:
- 商户通过后台系统添加商品到 MySQL 数据库。
- 为了让消费者能够查询到商品,需要将数据同步到 Elasticsearch 中。
- MySQL 和 Elasticsearch 的数据存储结构不同,因此称为异构数据。
异构数据带来的组织结构问题
团队分工:
- 商品管理由团队 A 负责,数据查询由团队 B 负责。
- 团队 B 负责 Elasticsearch 的数据维护和管理。
传统的同步方式及其问题: 在 Java 代码中进行修改,在新增 MySQL 数据时,同时调用团队 B 提供的接口进行 Elasticsearch 数据同步。
问题:
- 强耦合:团队 A 需要了解团队 B 的接口参数、传输规则和响应,增加了团队 A 的工作量。
- 扩展困难:如果新增团队 C 负责 MongoDB 的数据维护,团队 A 需要额外对接团队 C 的接口,增加了工作复杂度和协调难度。
解决方案目标
- 数据准实时同步:在几百毫秒或几秒钟内完成数据同步。
- 组织结构解耦:减少团队 A 调用其他团队接口的工作量。
解决方案工具:Canal
Canal 简介:
- 由阿里巴巴开源,用于监听数据库增量日志并进行数据订阅消费。
- 支持 MySQL 和 MariaDB。
Canal 的工作原理:
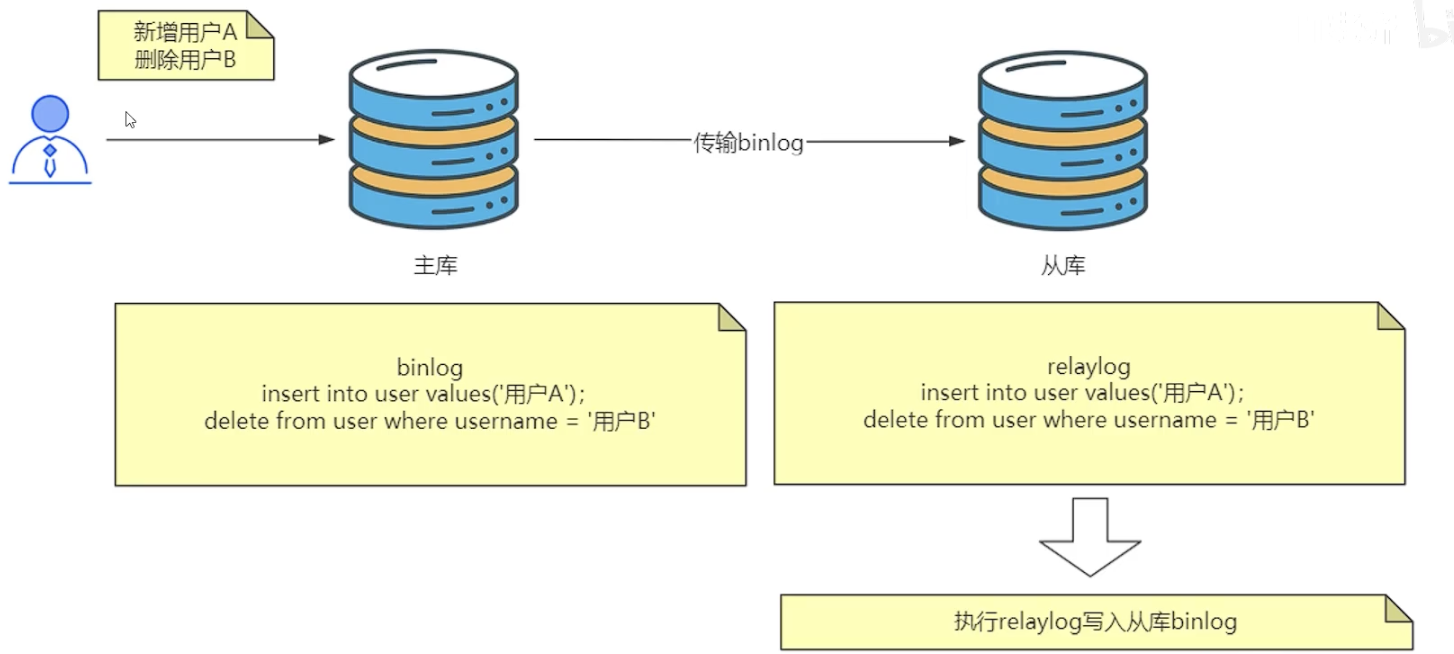
- MySQL 主从同步通过 binlog(Binary Log)实现。
- binlog 记录 SQL 语句,MySQL 从库通过 relay log 重放这些 SQL 语句实现数据同步。
- Canal 作为一个“假”从库,监听主库的 binlog,并触发指定的 Java 代码进行数据同步。
局限性与进一步解决方案:消息队列(MQ)
Canal 的局限性:仅解决数据监听问题,未解决团队之间的解耦问题。
引入消息队列(MQ):
- MQ 的作用:消息的订阅和发布。
- 架构图:
- 团队 A 负责将数据变化转换为消息并发送到 MQ。
- 团队 B 和其他团队订阅 MQ 消息队列,根据消息类型和内容进行相应的数据处理。
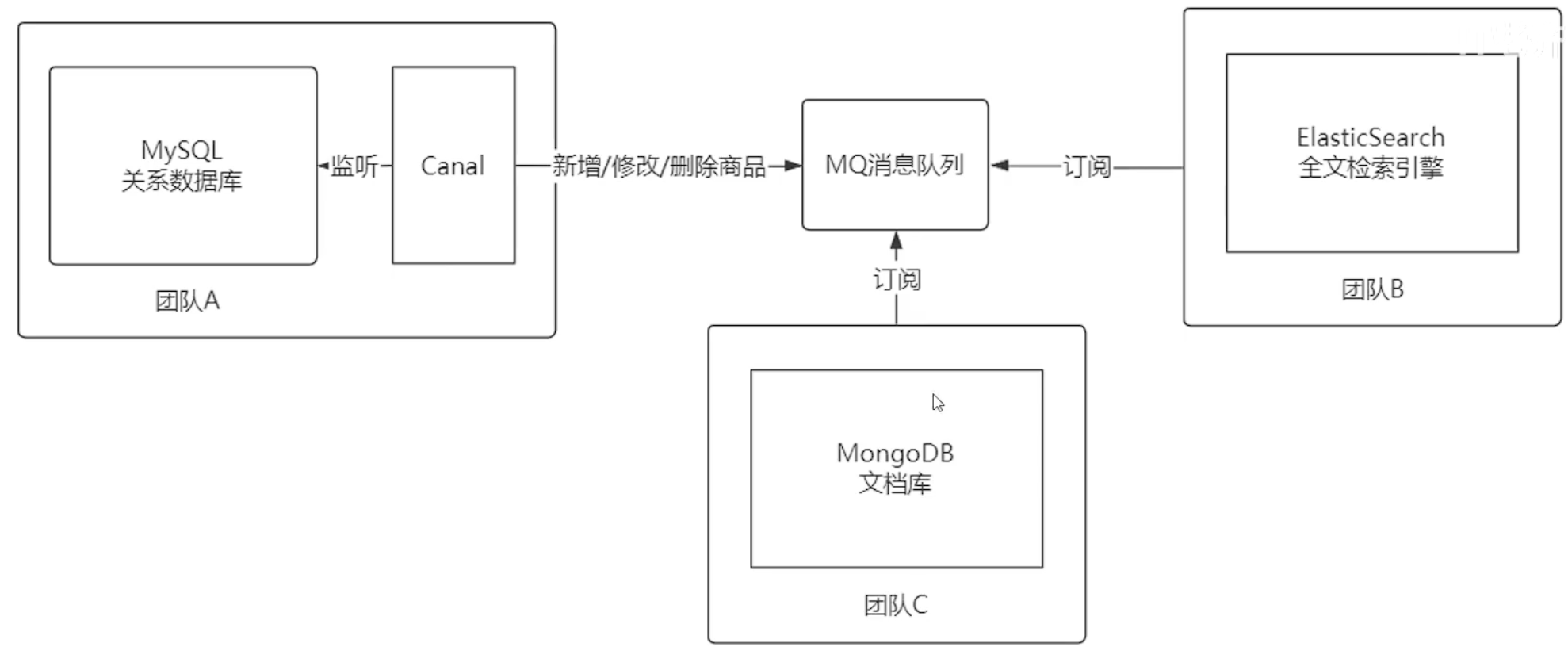
完整的异构数据迁移过程
- 数据变化监听:团队 A 在 MySQL 上配置 Canal 监听商品库的数据变化。
- 消息生成与发送:数据变化时,Canal 生成相应的消息(新增、修改、删除)并发送到 MQ。
- 消息订阅与处理:
- 团队 B 订阅 MQ 消息队列,接收消息后进行 Elasticsearch 数据同步。
- 新增团队(如团队 C)只需订阅相同的消息队列,无需与团队 A 直接对接。
通过 MQ 实现团队间解耦
- 团队 A 只需将数据变化放入 MQ,不再关心其他团队的 API 接口。
- 新增团队只需订阅消息队列,独立处理数据同步逻辑。
- 实现了真正的解耦,提高了开发效率和系统扩展性。
结论
异构数据迁移:
- 通过 Canal 和 MQ 的结合,实现了异构数据的准实时同步和团队间的解耦。
- 这种架构设计解决了传统方式中的强耦合和扩展困难问题,提高了系统的灵活性和可维护性。