数据库自增主键与的探讨
大约 11 分钟
数据库自增主键与的探讨
为什么大厂严禁使用数据库的自增主键来生成ID号。
- 大表为什么不能使用自增主键?
- UUID是好的替代方案吗?
- Snowflake雪花算法是什么?
自增主键
自增主键(auto increment)是指在一个主键上设置auto increment,即自增序列。生成数据时,无需设置主键值,数据库会根据数字的顺序(1, 2, 3, 4...)依次自动生成主键。
自增主键的使用场景
- 创意型公司或学校毕业设计中使用自增主键没有问题。
- 在大厂(如京东、阿里、腾讯)中,自增主键往往禁止使用。
在分布式数据环境中的问题
资源浪费
- 假设有三个数据库(表分片),分别包含0到1亿、1亿到2亿、2亿到3亿的数据。
- 构建数据库集群时,如何评估每个数据库最多容纳一亿数据?如果数据库能承载1.5亿数据,是否还能扩展?
- 答案是否定的,因为范围分片是固定的,无法动态扩展。
尾部热点问题
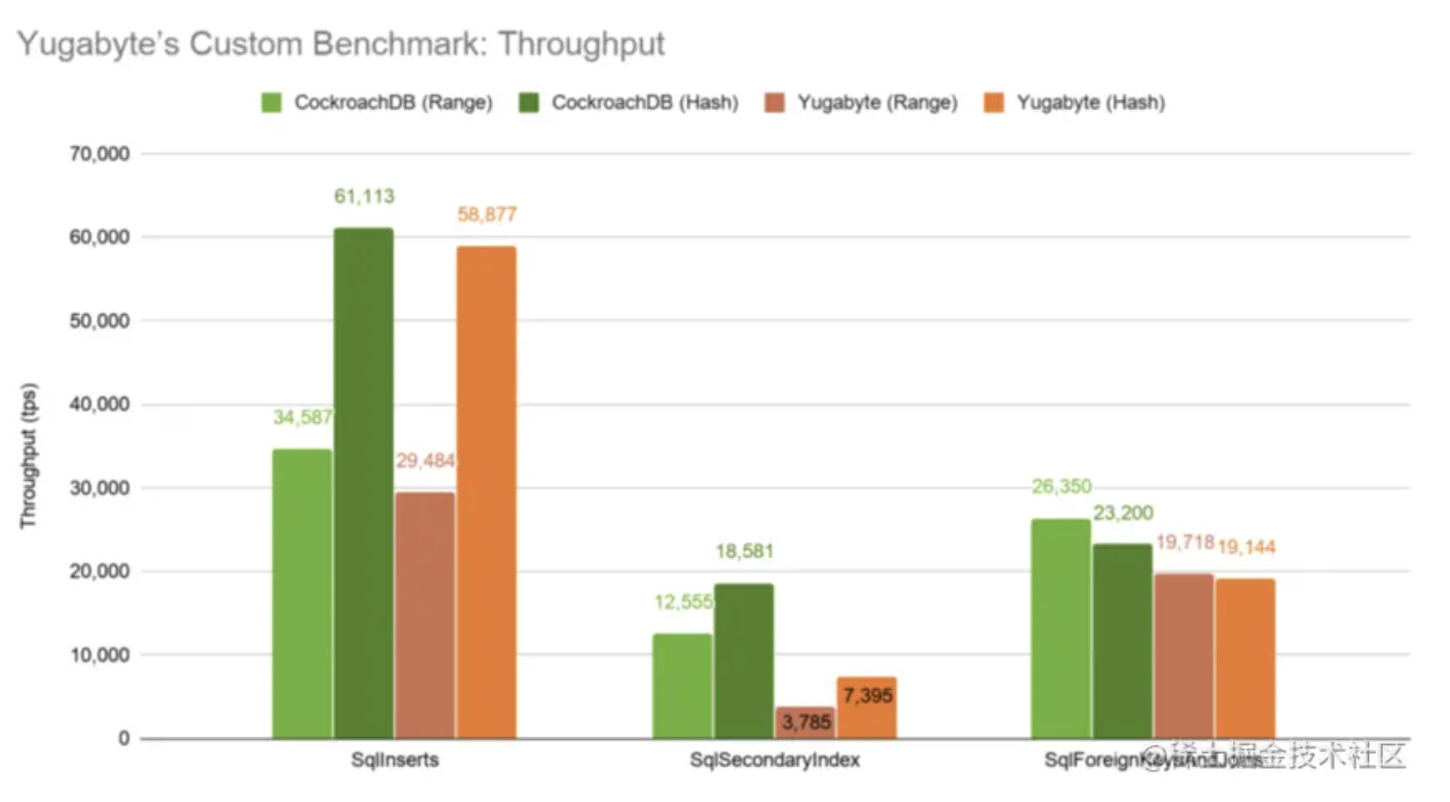
- 范围分片会产生尾部热点问题:数据堆积到2.5亿时,所有新数据都插入到分片三,导致分片三的数据库压力极大,而前两个分片几乎没有压力。
- 测试结果显示,范围分片的写入效率比哈希分片低1.5倍以上。
UUID 替代自增主键
使用 UUID 可以替代自增主键吗?不可以!
UUID的特点
- UUID 是根据当前计算机时间及各种特性生成的全球唯一的128位长字符串。
- 使用 UUID 是无序的,作为主键会涉及大量索引重排
UUID 作为主键的问题
- UUID 长度为128位,相比整形或长整形浪费空间。
- 无序的 UUID 会导致大量的索引重排。
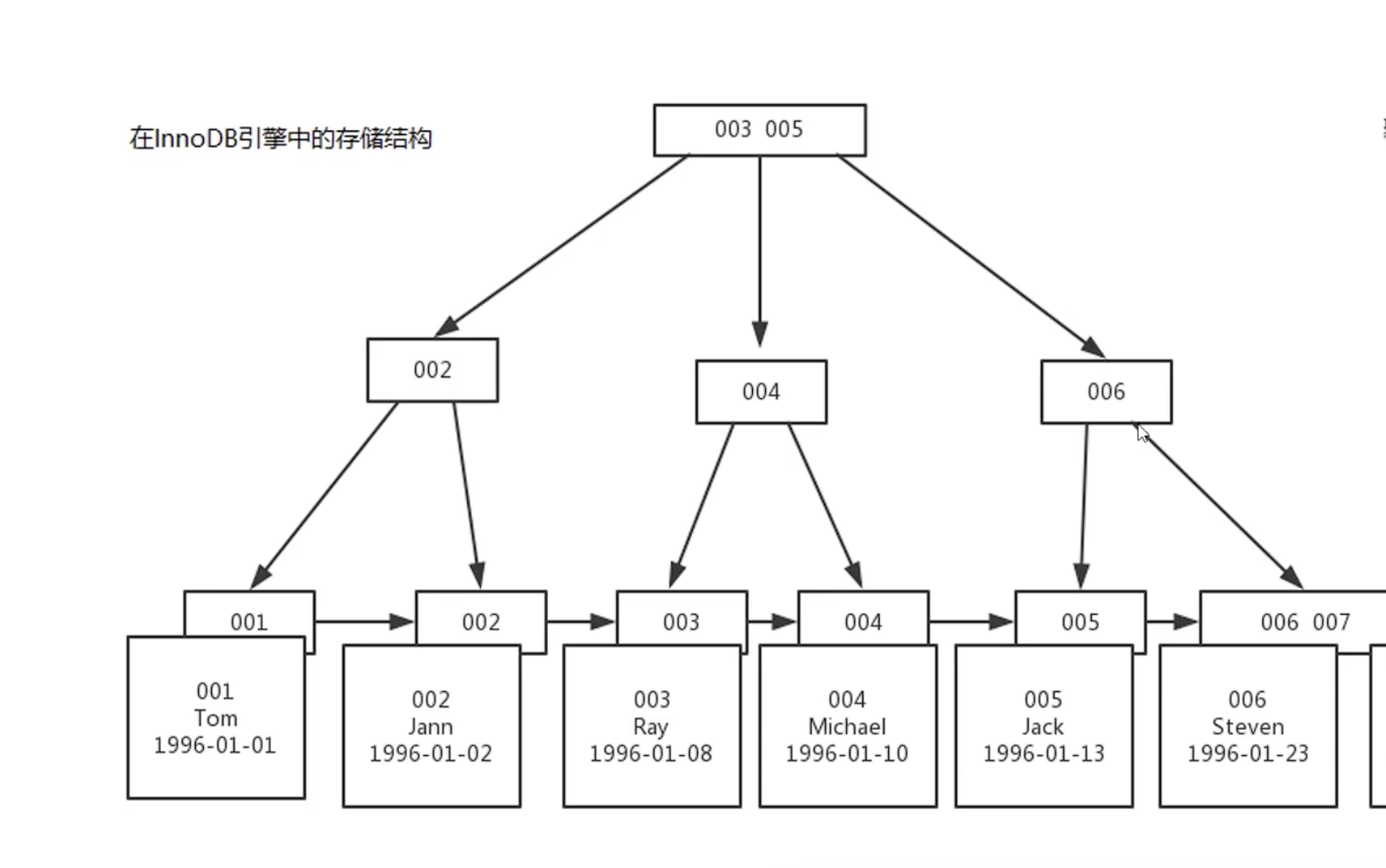
InnoDB引擎基于B+树结构有序紧密存储,中间插入数据必然会造成”页分裂“现象产生
索引重排
- MySQL的InnoDB引擎采用B+树存储数据,叶子节点按顺序排列。
- 顺序主键新增数据时,只需在B+树最后追加元素,影响范围小。
- 无序UUID新增数据时,需要在索引某个点上附加,导致后续节点重排,代价高。
结论: UUID不适合用作主键的替代品。
Snowflake 雪花算法
Snowflake是Twitter开发的分布式ID生成算法。
- 主要思路:以时间为依据,结合机器ID和序列生成定长数字,作为新主键。
- 生成的序列是有序的
Snowflake 算法的组成部分
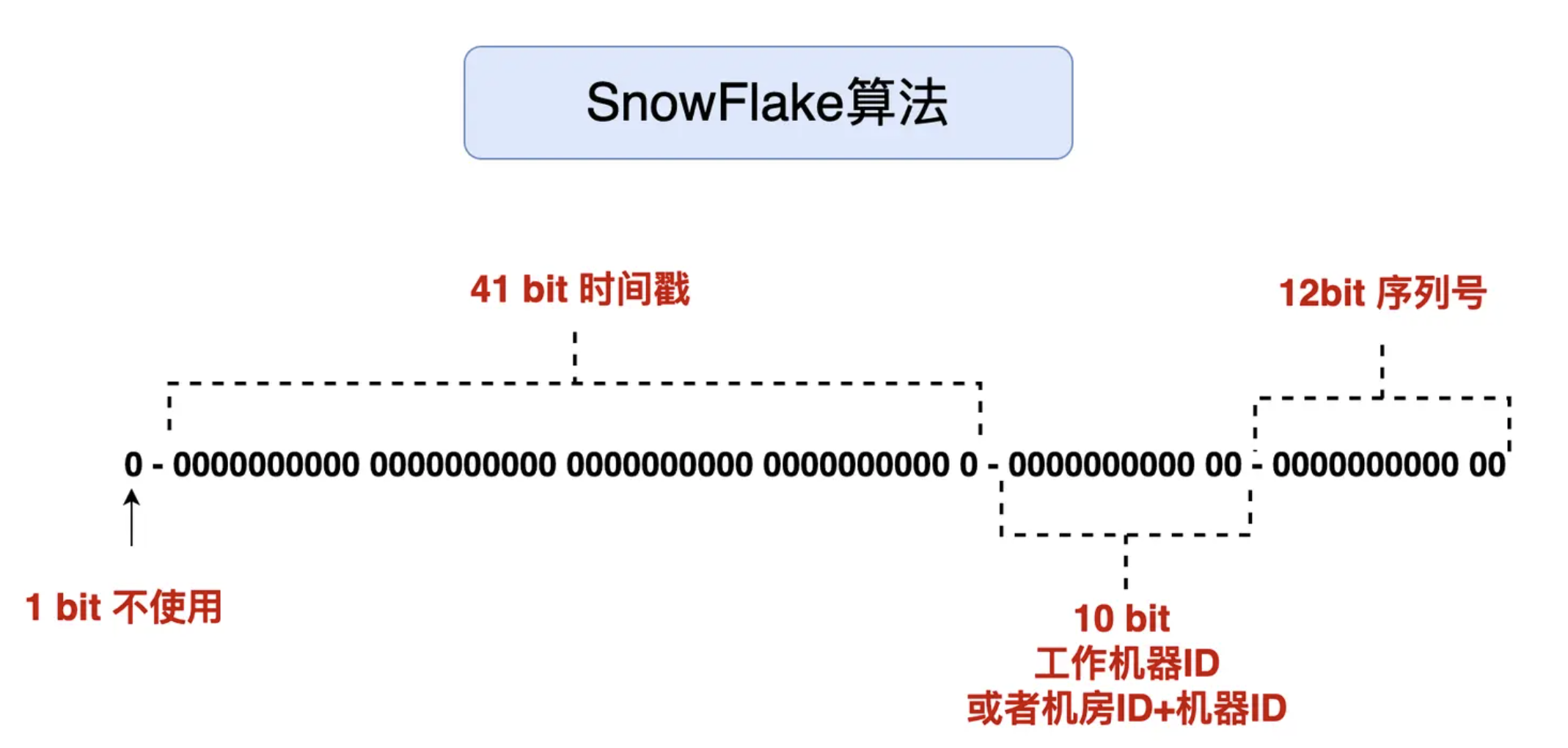
- 符号位:最高位,无实际用处,兼容长整形格式。
- 时间戳:41位,表示本地毫秒级时间。
- 机器ID:10位,表示数据库机器的特征,允许1024个数据库节点。
- 序列:12位,在一毫秒内某数据库节点能生成的ID数量,最多4096个。
Snowflake 算法的优点
- 保证有序性和分布式环境下的唯一性。
- 每毫秒可生成416万个ID,足够大多数应用。
使用注意事项
时间回拨问题:如果服务器时间回调几毫秒或前调几秒,可能会导致ID重复。
- 时间回拨通常由人为调时间或服务器时钟同步引起。
- 真实环境下,时间回拨几乎不会发生。
实践中的应用
- Java 中已有许多线程安全的实现,调用相关库即可生成 ID。
- 后续会讲解 Snowflake 在 Sharding-JDBC 中的应用。
总结
- 自增主键在分布式环境下有资源浪费和尾部热点问题。
- UUID不适合作为主键替代品,会导致索引重排。
- Snowflake 算法能生成有序且唯一的分布式ID,是较好的解决方案。
- 关注时间回拨问题,但在大多数场景下Snowflake是可靠的。