公共表设计与分布式数据库管理
大约 15 分钟
公共表设计与分布式数据库管理
在复杂的系统中,公共表是指被其他业务模块共享的基础数据表。这些表在系统中起到底层支撑的作用,常见的公共表包括用户表、行政区划、数据字典、组织结构和系统配置等。
尽管这些表不直接承担具体的业务职责,但它们对上层应用至关重要。然而,在分布式环境下,设计和管理这些公共表会遇到新的挑战。
早期设计与管理方式
单一大库管理
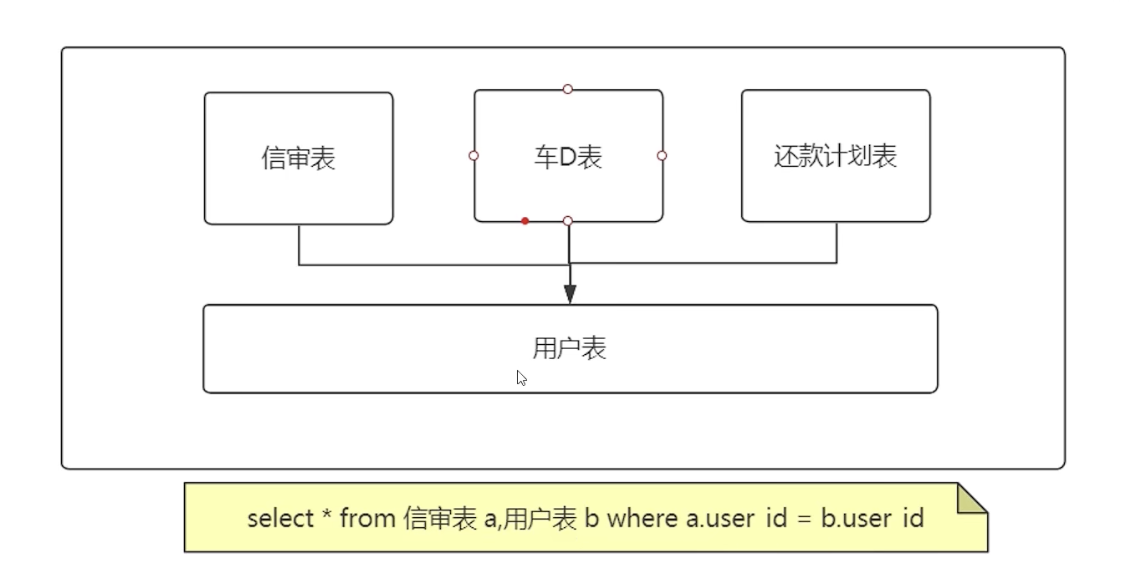
统一管理:在宜信项目初期,所有数据表都集中在一个大数据库中,无论哪个团队负责的数据表,都放置在统一的后端数据库中。
表的分类:
- 业务表:如信审表、车代表、还款计划表等,与具体业务相关。
- 公共表:如用户表、数据字典表、系统配置表等,用于支撑上层应用。
数据查询的简便性 -> 关联查询:在单一大库中,数据查询非常简单。例如,信审表关联用户表,只需要一个简单的SQL查询即可完成。
业务发展带来的挑战
数据量增长的影响
- 数据量激增:随着宜信用户量的增加(例如,用户表中有四千万数据),数据查询变得复杂。
- 性能问题:如果某个新的模块对用户表进行全表检索,可能会导致磁盘 IO 拉满,影响其他表的访问,导致系统高延迟。
风险放大
- SQL查询风险:一个程序员写的SQL如果不当,可能会导致整个系统出现性能问题。特别是在团队扩大后,难以保证所有程序员都能正确使用索引。
分布式数据库的设计思路
数据库切分
- 物理切分:根据组织职责或数据维度,进行数据库的物理层面切分,让每个团队拥有独立的资源。
- 结构调整:将公共表下沉为基础服务,业务表上升为业务服务,通过RPC或Restful API进行远程访问。
设计实现
- 项目组独立:随着业务的发展,信审、车贷和贷后等都成立了独立的项目组,并有独立的团队维护。
- 子库拆分:原有的大库设计被拆分成多个子库,每个子库都有自己的业务数据表,但底层依赖用户的原始数据。
用户服务的引入
- 用户服务:由专门的团队维护用户数据,通过Restful API对外提供接口,其他上层服务进行调用。
- 权限控制:只有用户服务团队有权直接访问用户表,其他团队通过API进行数据交互。
优化与解耦
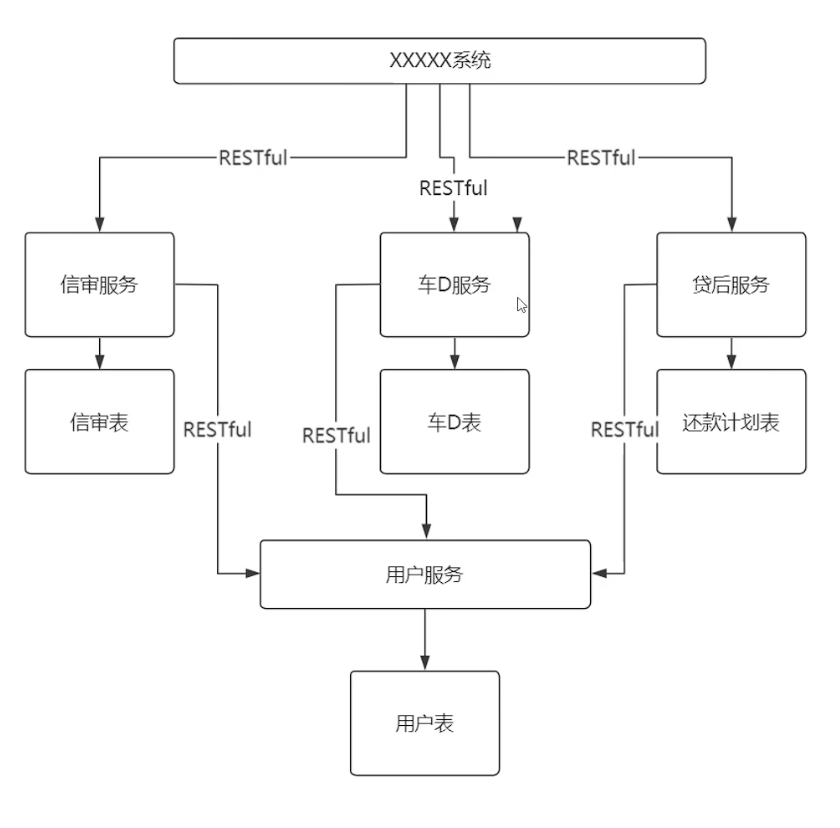
数据层面解耦
- 独立服务器资源:每个团队拥有独立的服务器资源,用户表的高延迟不会影响其他数据库。
- API接口封装:用户服务对外暴露标准化的API接口,例如按ID号查询用户数据,底层可以针对这些特定查询场景进行优化。
团队之间解耦
- 责任明确:每个团队负责自己的模块,数据查询慢的问题可以追溯到具体的服务层面,并有具体人员负责解决。
- 减少扯皮:通过明确的职责分工,减少团队之间的扯皮情况。
架构设计的复杂性
开发的繁琐性
- 远程通信复杂度:原本简单的关联查询变成了通过 Restful API 进行远程通信,增加了开发复杂度。
- 新手工程师的挑战:对于刚毕业的应届生,复杂的远程调用可能超出其能力范围。
数据层面解耦,有独立的服务器资源支撑团队之间解耦,谁的模块谁负责
- 开发起来真的麻烦
- 如何屏蔽底层复杂度是架构设计的难点
架构设计的解决方案
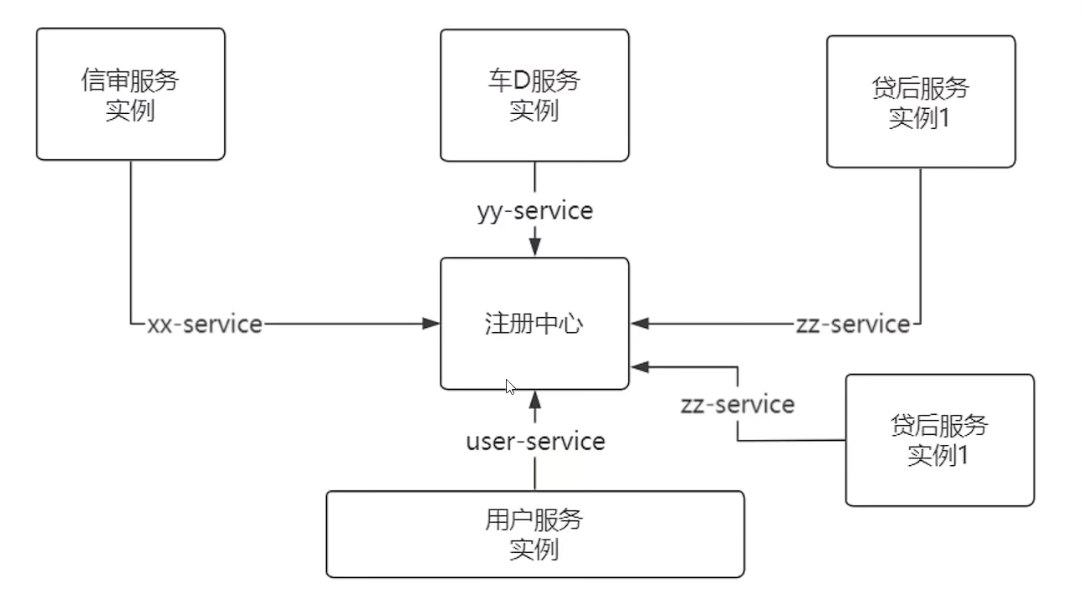
- 微服务注册中心:设计类似微服务的注册中心,对每个启动的服务实例进行登记。
- 服务实例管理:注册中心管理所有服务实例的IP地址和相关信息,统一管理服务实例。
实例与实现
案例分析
- Bucket表与用户服务:在底层数据库有一张 Bucket 表,其中有个字段long user ID。根据业务需要,需要从用户服务中获取用户的其他数据,这时会产生网络远程通信。
- 自定义注解:通过自定义注解指明服务名称(如user service),查询注册中心获取服务实例的IP地址和端口号,然后拼接出完整的URL,发起远程请求。
- 数据注入:远程服务返回数据后,自动注入到当前对象的user参数中,简化程序员的开发工作。
代码示例

- 注解配置:在方法上增加自定义注解,指明服务名称和URI,自动实现远程通信。
- 数据交互:程序员无需关心底层的传输细节,只需专注于业务开发。
总结
通过以上设计,宜信在项目开发中解决了数据量增长带来的挑战,实现了数据层面和团队之间的有效解耦,提升了系统的稳定性和可维护性。
同时,通过架构设计屏蔽了底层远程调用的复杂度,简化了程序员的开发工作。这些经验和方法对其他类似项目具有很好的借鉴意义。