Correlation
Correlation
当人们随便说 "相关 "时,他们可能指两个变量之间的任何关系。在统计学中,它通常是指皮尔逊相关系数,这是一个介于-1和1之间的数字,可以量化变量之间的线性关系的强度。
相关关系只对线性关系有效(可以换元)。如果关系是非线性的,相关通常会低估它有多强。
还有一个原因是要小心相关关系;它并不意味着人们所认为的那样。具体来说,相关关系没有说到斜率。如果我们说两个变量是相关的,这意味着我们可以用一个变量来预测另一个。但这可能不是我们所关心的。
# Select columns
columns = ["AGE", "INCOME2", "_VEGESU1"]
subset = brfss[columns]
# Compute the correlation matrix
print(subset.corr())
AGE INCOME2 _VEGESU1
AGE 1.000 -0.015 -0.01
INCOME2 -0.015 1.000 0.12
_VEGESU1 -0.010 0.120 1.00
Linear Correlation
Coefficient
- 量化两个变量之间的线性关系
- 数字在-1和1之间
- 幅度与关系的强度相对应
- 标志(+或-)对应于关系的方向
Visualizing relationships
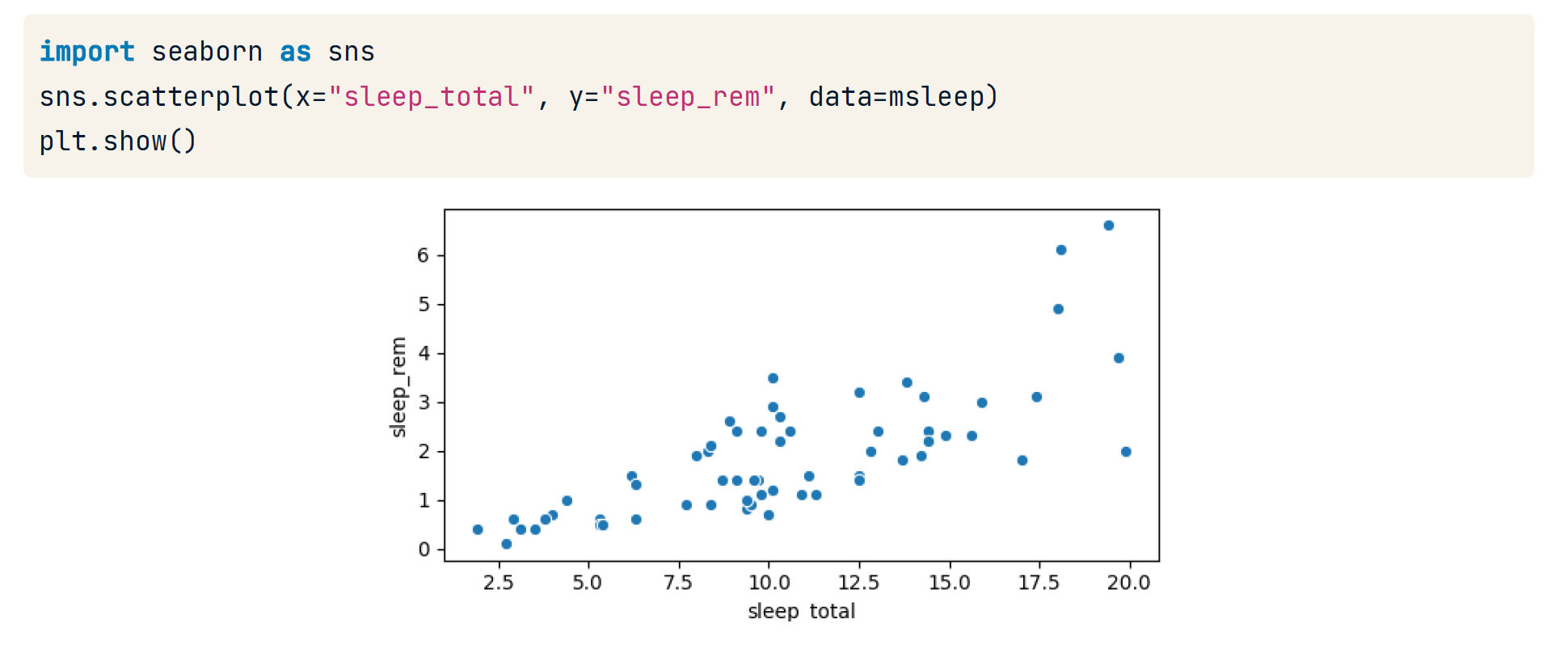
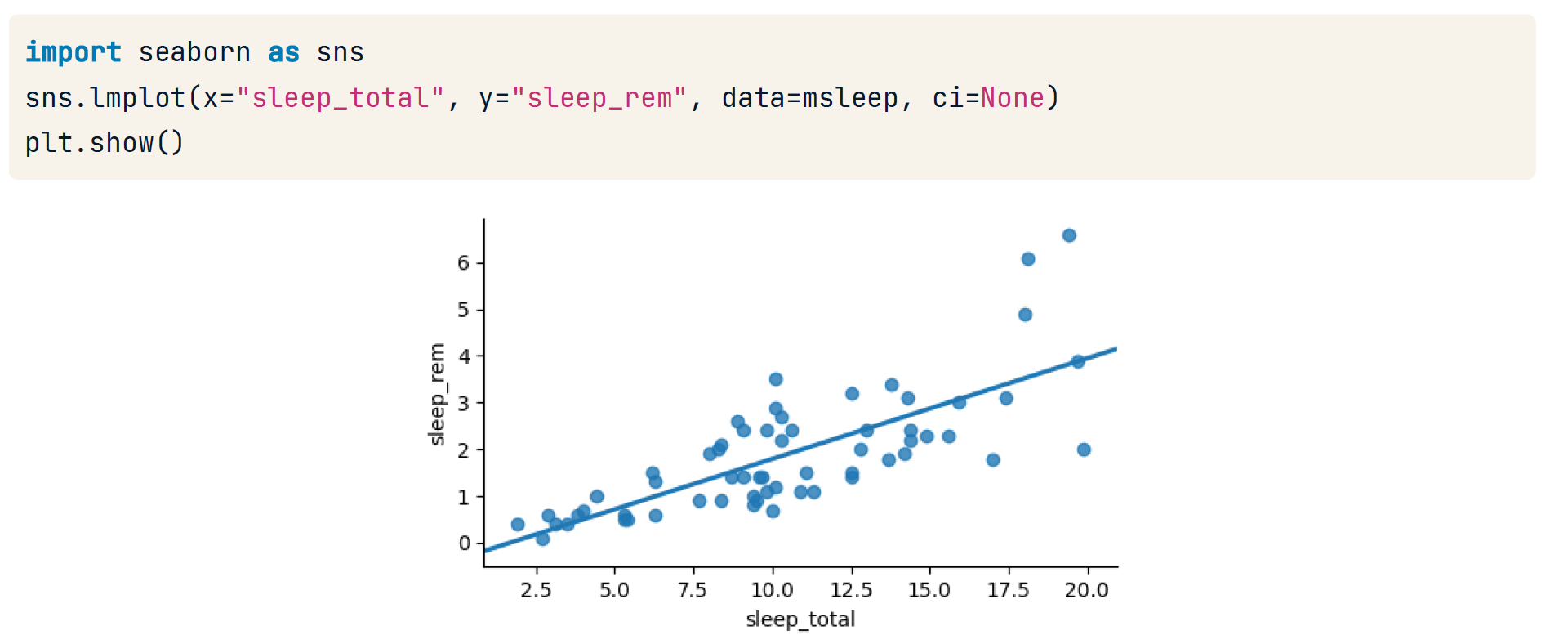
Computing Linear correlation
msleep['sleep_total'].corr(msleep['sleep_rem'])
0.751755
Way to calculate Linear correlation

还有很多其他的方式计算相关性。
Non-linear relationships
- Log transformation ( log(x) )
- Square root transformation ( sqrt(x) )
- Reciprocal transformation ( 1 / x )
- Combinations of these, e.g.:
- log(x) and log(y)
- sqrt(x) and 1 / y
Confounding
Correlation does not imply causation「相关并不意味着因果关系」
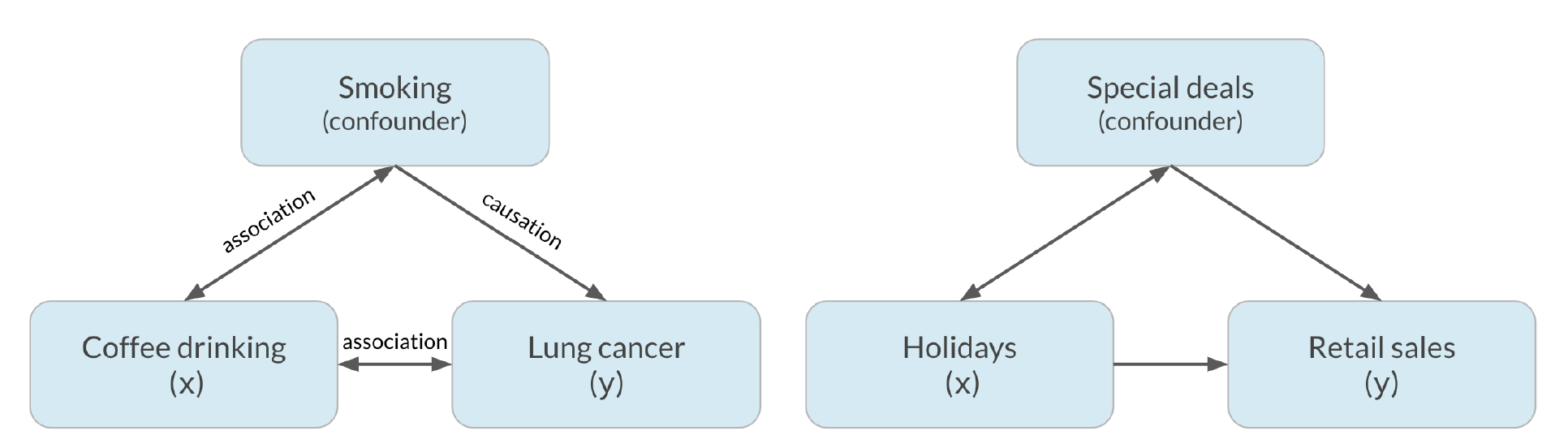
案例
一项研究正在调查居民区与肺活量之间的关系。研究人员测量了来自位于高速公路附近的A社区的30人的肺活量,以及来自不在高速公路附近的B社区的30人。两组人都有类似的吸烟习惯和类似的性别分类。
以下哪项可能是本研究中的 Confounding「混淆因素」?
- Lung capacity
- Neighborhood
- Air pollution ✔️
- Smoking status
- Gender
Design of experiments
Treatment & Response
通常情况下,数据是作为一项旨在回答特定问题的研究的结果而产生的。然而,根据数据产生的方式和研究的设计,需要对数据进行不同的分析和解释。
实验通常旨在回答一个问题,其形式是:"treatment对response的影响是什么?".在这种情况下,
- treatment指的是解释变量或自变量,
- 而response指的是响应变量或因变量。
例如,一个广告对购买产品的数量有什么影响?在这种情况下,treatment方法是广告,而response是购买产品的数量。
生词
subject nc. 受试者
Controlled experiments
在受控实验中,参与者被随机分配到实验组或对照组,其中实验组接受实验,对照组不接受实验。这方面的一个很好的例子是A/B测试。在我们的例子中,实验组将看到一个广告,而对照组则不会。
除了这个差异,这两组应该是可比的,这样我们就可以确定看到广告是否会导致人们购买更多。
如果两组没有可比性,这可能会导致混杂,或偏见。如果实验组参与者的平均年龄是25岁,而对照组参与者的平均年龄是50岁,如果年轻人更有可能购买更多的东西,年龄可能是一个潜在的混淆因素,这将使实验偏向于实验。
Gold standard of experiments
黄金标准 或 理想的实验 将通过使用某些工具消除尽可能多的偏见。
帮助消除受控实验中偏见的 第一个工具是 使用随机对照试验。 在随机对照试验中,参与者被随机分配到实验组或对照组,他们的分配不是基于任何其他因素,而是基于机会。像这样的随机分配有助于确保各组具有可比性。
第二种方式是使用安慰剂,即类似于实验的东西,但没有效果。这样一来,参与者不知道他们是在实验组还是对照组。这确保了实验的效果是由于实验本身,而不是由于得到实验的想法。这在测试药物有效性的临床试验中很常见。对照组仍然会被给予药丸,但这是一种对结果影响最小的糖丸。 在双盲实验中,实施实验 或 进行实验 的人也不知道他们是在实施实际的实验还是安慰剂。
这可以防止结果以及结果分析中的偏差。这些不同的工具都归结为同一个原则:如果有更少的机会让偏见潜入你的实验,你就能更可靠地得出结论,实验是否影响了结果。
较少的偏见机会 = 更可靠的因果关系结论
Observational studies
我们要讨论的另一种研究是观察性研究。
在观察性研究中,参与者不是被随机分配到各组。相反,参与者自己分配,通常是基于预先存在的特征。这对于回答那些不利于受控实验的问题很有用。
如果你想研究吸烟对癌症的影响,你不能强迫人们开始吸烟。同样,如果你想研究过去的购买行为如何影响某人是否会购买某种产品,你不能强迫人们有某些过去的购买行为。因为分配不是随机的,没有办法保证各组在各方面都有可比性,所以观察性研究不能确定因果关系,只能确定关联。
实验的效果可能会受到一些因素的干扰,这些因素使某些人进入对照组,而某些人进入实验组。然而,有一些方法可以控制混杂因素,这可以帮助加强关联结论的可靠性。

Longitudinal vs. cross-sectional studies
最后要区分的是纵向研究和横断面研究。
在纵向研究中,相同的参与者在一段时间内被跟踪,以检查实验对结果的影响。
在横断面研究中,数据是从一个单一的时间快照中收集的。
如果你想研究年龄对身高的影响,横断面研究会测量不同年龄的人的身高并进行比较。然而,结果会受到出生年份和生活方式的干扰,因为有可能每一代人都在变高。
在纵向研究中,同样的人将在他们生命中的不同时间点记录他们的身高,因此混淆因素被消除了。重要的是要注意,纵向研究更昂贵,而且需要更长的时间,而横断面研究更便宜,更快,更方便。