Summary Statistics
Summary Statistics
What is statistics
- The field of statistics: 收集和分析数据的实践和研究
- A summary statistic: 关于某些数据的事实或摘要
What can statistics do?
- 人们购买产品的可能性有多大?如果人们能够使用不同的支付系统,他们是否更有可能购买该产品?
- 如果可以使用不同的支付系统,人们是否更有可能购买?
- 你的酒店将有多少人入住?你怎样才能优化入住率?
- 需要生产多少种尺寸的牛仔裤才能满足95%的人的需要?
- 每种尺寸的产品应该生产相同数量的产品吗?
- A/B测试。哪一个广告在吸引人们购买产品方面更有效?
What can't statistics do?
为什么《权力的游戏》如此受欢迎?
相反...
有更多暴力场面的系列被更多人观看吗?
但是...
即使如此,这也不能告诉我们更多的暴力场面是否会导致更多的浏览量
Types of statistics
数据的种类


分类数据可以用数字来表示

- 点图可用于
- x = 可定量的值, y = 可定量的值
- 线图可用于
- x = 离散数值,y = 可定量的值
- x = 有序的分类值,y = 可定量的值
- Hist可用于
- x = 离散数值, y = 个数
- x = 有序的分类值, y = 个数
- Bar可用于
- x = 分类数值, y = 可定量的值
Measures of center
一般,衡量数据可以用
- 图表:hist等
- 平均数:hist
- 中位数 (median)
- 众数 (mode)
- ......
# 求平均数
import numpy as np
np.mean(msleep['sleep_total'])
# 也可以使用 msleep['sleep_total'].mean()
# 求中位数
np.median(msleep['sleep_total'])
# 求众数
import statistics
# 可以查看每种的个数
msleep['vore'].value_counts()
# 显示众数是什么
statistics.mode(msleep['vore'])
应该用什么来衡量中心?
如果是类似中心对称的,建议使用平均数
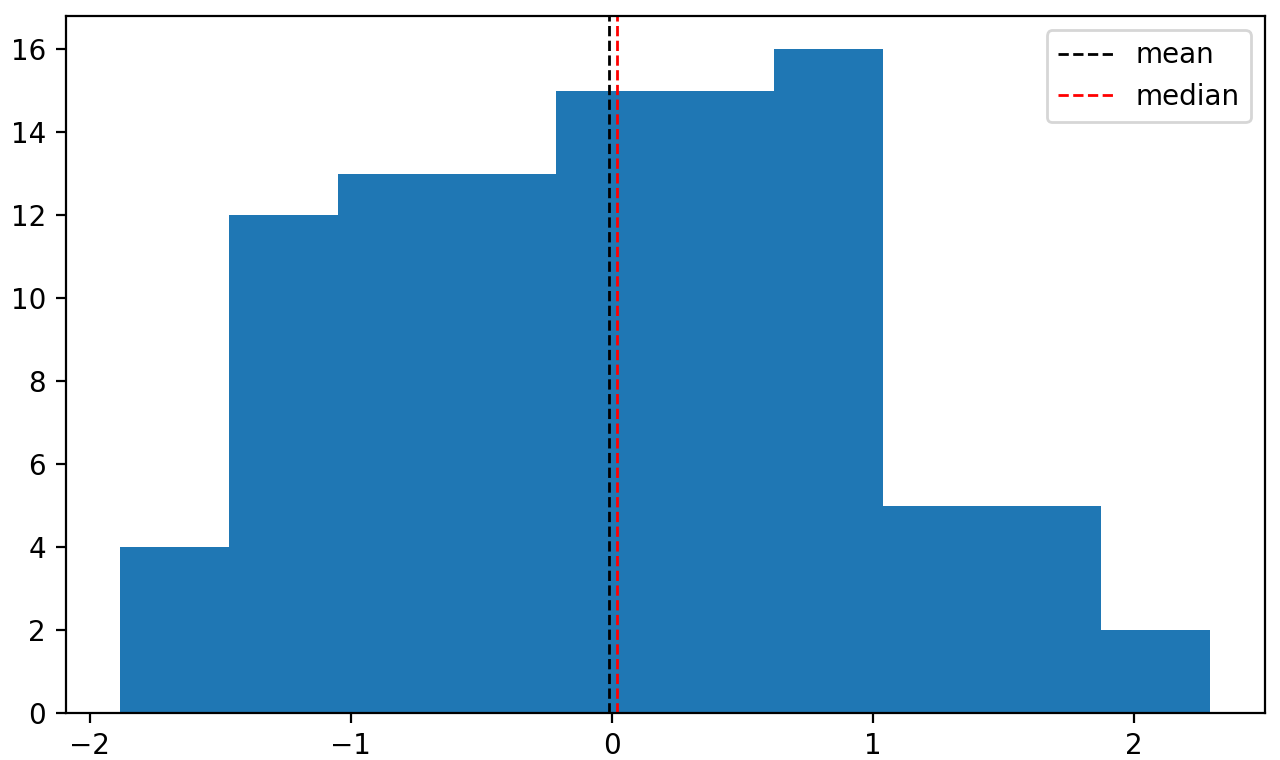
如果是左或者右偏移,建议使用中位数
Remember that left-skewed means the data has a tail on the left side and is piled up higher on the right.
Measures of spread
用于表示数据的集中程度。
Variance
计算样本方差
计算样本方差,除数应当使用 n-1而不是n,为了无偏。
为什么分母是n-1而不是n?
无偏估计可以这么理解。因为均值你已经用了n个数的平均来做估计。在求方差时,只有 (n-1)个数 和 均值信息 是不相关的。而你的第n个数已经可以由前(n-1)个数和均值 来唯一确定,实际上没有信息量。所以在计算方差时,只除以(n-1)。
完整的解释:↓
先把问题完整地描述下。
如果已知随机变量 的期望为
,那么可以如下计算方差
:
上面的式子需要知道 的具体分布是什么(在现实应用中往往不知道准确分布),计算起来也比较复杂。
所以实践中常常采样之后,用下面这个 来近似
:
其实现实中,往往连 的期望
也不清楚,只知道样本的均值:
那么可以这么来计算 :
那这里就有两个问题了:
- 为什么可以用
来近似
?
- 为什么使用
替代
之后,分母是
?
我们来仔细分析下细节,就可以弄清楚这两个问题。
1 为什么可以用 来近似
?
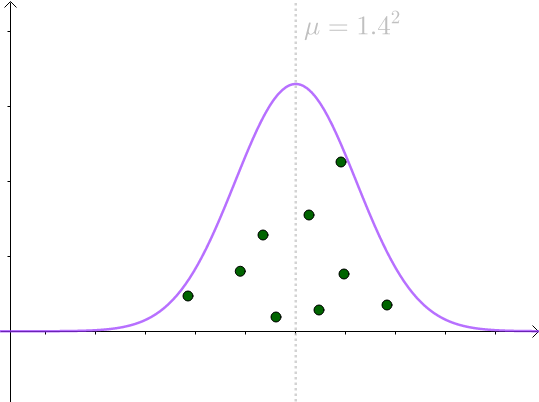
举个例子,假设 服从这么一个正太分布:
即, ,图形如下:
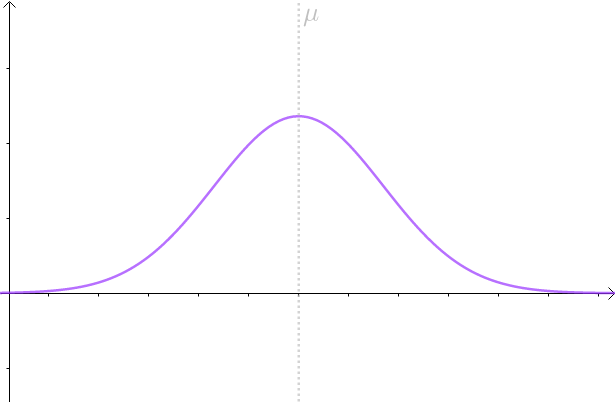
当然,现实中往往并不清楚 服从的分布是什么,具体参数又是什么?所以用虚线来表明我们并不是真正知道
的分布:
很幸运的,我们知道 ,因此对
采样,并通过:
来估计 。某次采样计算出来的
:
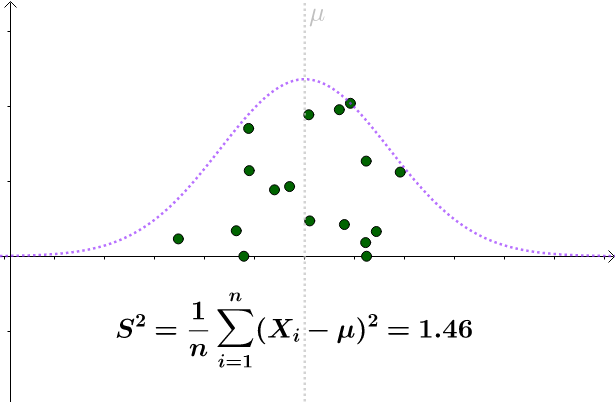
看起来比 要小。采样具有随机性,我们多采样几次,
会围绕
上下波动
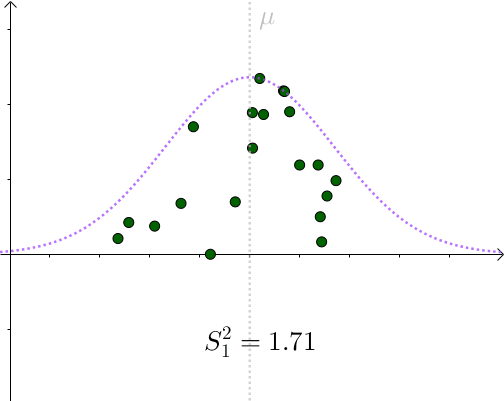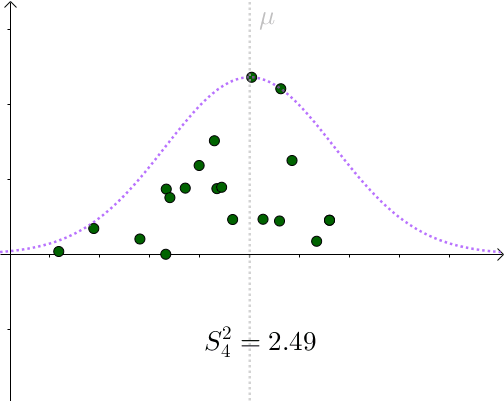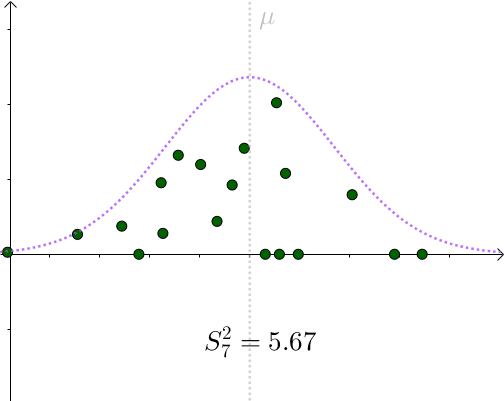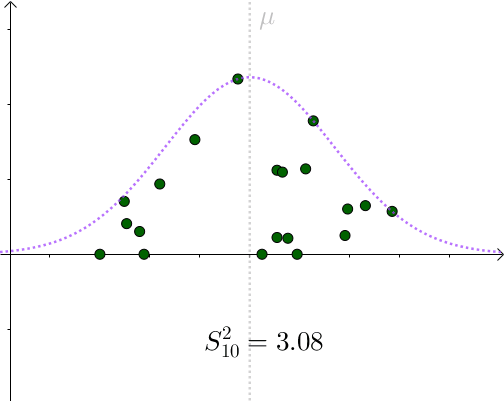
所以用 作为
的一个估计量,算是可以接受的选择。
很容易算出:
因此,根据中心极限定理, 的采样均值会服从
的正态分布:
2 为什么使用 替代
之后,分母是
?
更多的情况,我们不知道 是多少的,只能计算出
。不同的采样对应不同的
:
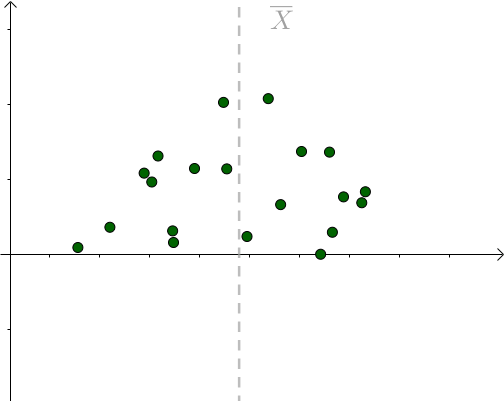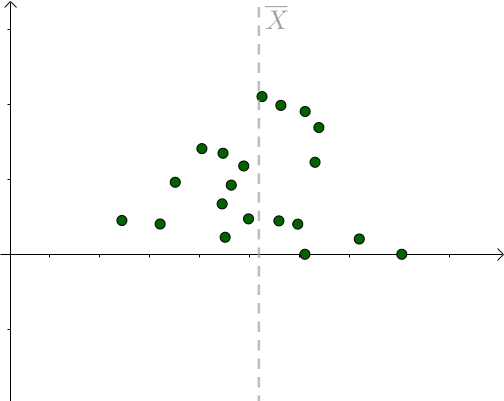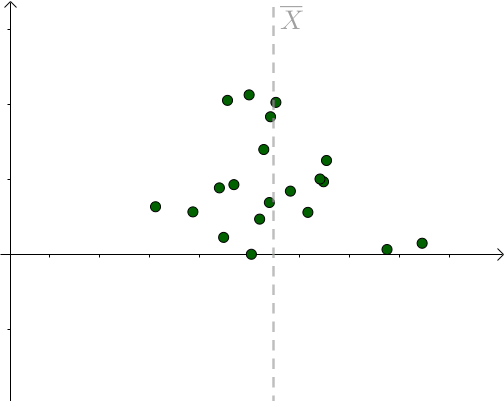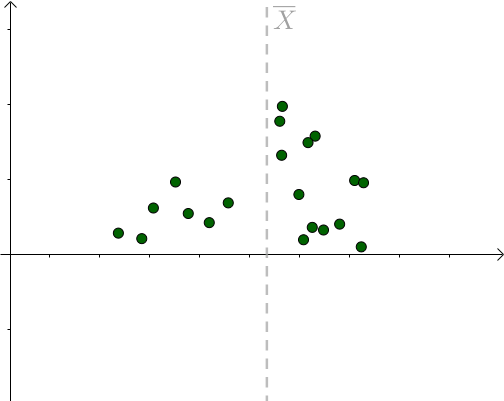
对于某次采样而言,当 时,下式取得最小值:
只要 偏离
,该值就会增大。
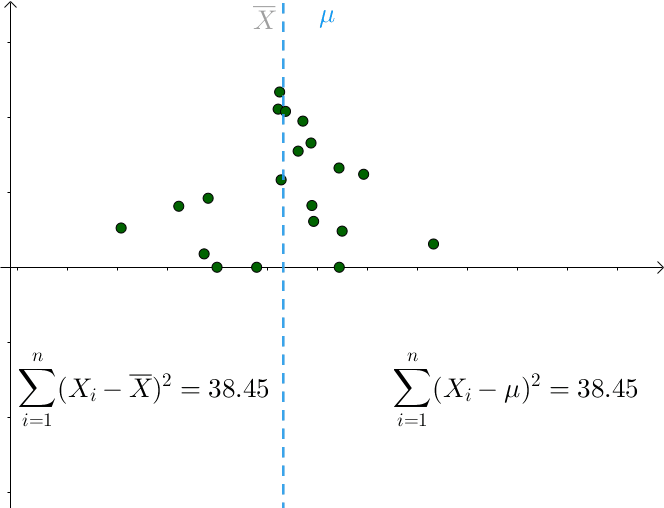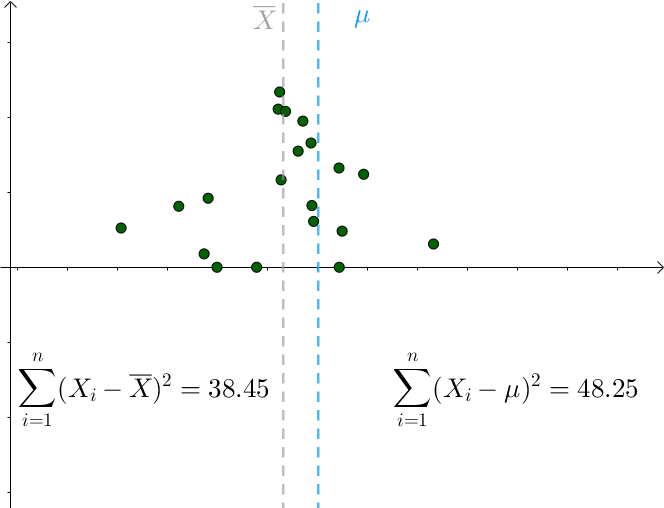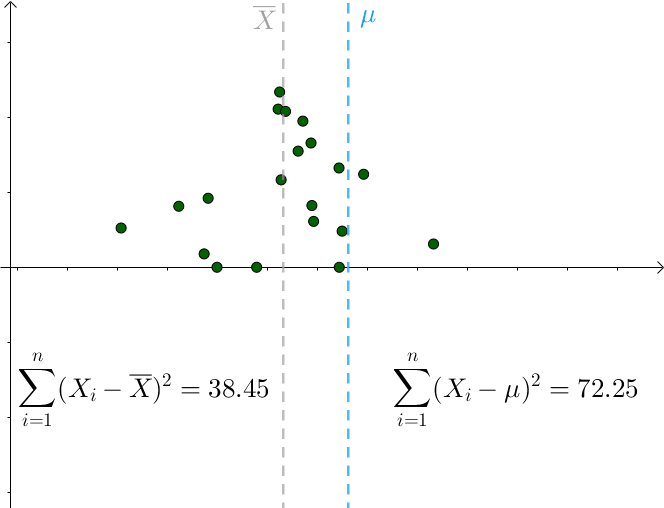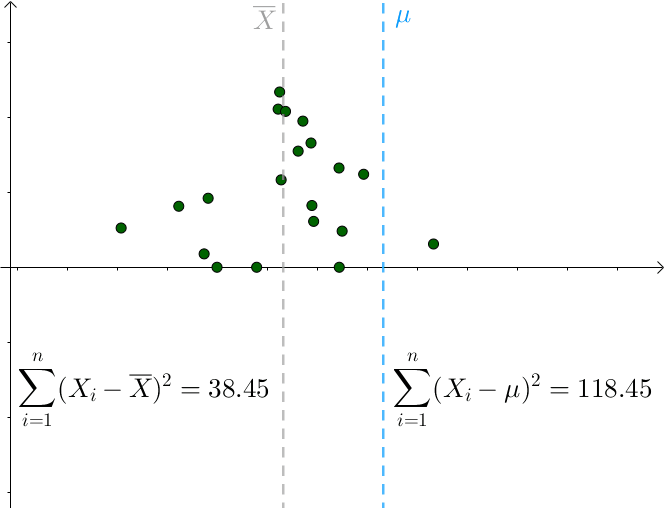
所以可知:
可推出:
进而推出:
如果用下面这个式子来估计:
那么 采样均值会服从一个偏离
的正态分布:
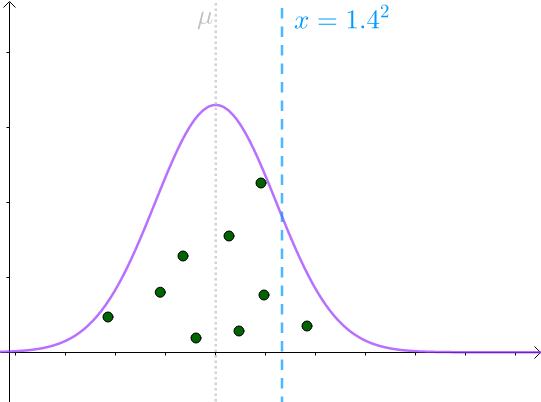
可见,此分布倾向于低估 。
具体小了多少,我们可以来算下:
其中:
所以我们接着算下去:
其中(证明见Prove that ):
所以:
也就是说,低估了 ,进行一下调整:
因此使用下面这个式子进行估计,得到的就是无偏估计:
我们计算样本的方差是为了估计数据整体的方差,这是可行的,依据中心极限原理
什么是中心极限原理?
「Central Limit Theorem」
中心极限定理指的是给定一个任意分布的总体。我每次从这些总体中随机抽取 n 个抽样,一共抽 m 次。 然后把这 m 组抽样分别求出平均值。 这些平均值的分布接近正态分布。
举个例子
现在我们要统计全国的人的体重,看看我国平均体重是多少。当然,我们把全国所有人的体重都调查一遍是不现实的。所以我们打算一共调查1000组,每组50个人。 然后,我们求出第一组的体重平均值、第二组的体重平均值,一直到最后一组的体重平均值。中心极限定理说:这些平均值是呈现正态分布的。并且,随着组数的增加,效果会越好。 最后,当我们再把1000组算出来的平均值加起来取个平均值,这个平均值会接近全国平均体重。
其中要注意的几点:
- 总体本身的分布不要求正态分布
上面的例子中,人的体重是正态分布的。但如果我们的例子是掷一个骰子(平均分布),最后每组的平均值也会组成一个正态分布。(神奇!) - 样本每组要足够大,但也不需要太大
取样本的时候,一般认为,每组大于等于30个,即可让中心极限定理发挥作用。
话不多说,我们现在来一步步看到中心极限定理是如何起作用的。
下面用实际数据来展示CLT
假设我们现在观测一个人掷骰子。这个骰子是公平的,也就是说掷出1~6的概率都是相同的:1/6。他掷了一万次。我们用python来模拟投掷的结果:
import numpy as np
random_data = np.random.randint(1, 7, 10000)
print random_data.mean() # 打印平均值
print random_data.std() # 打印标准差
生成出来的平均值:3.4927(每次重新生成都会略有不同)
生成出来的标准差:1.7079
平均值接近3.5很好理解。 因为每次掷出来的结果是1、2、3、4、5、6。 每个结果的概率是1/6。所以加权平均值就是3.5。
我们把生成的数据用直方图画出来直观地感受一下:
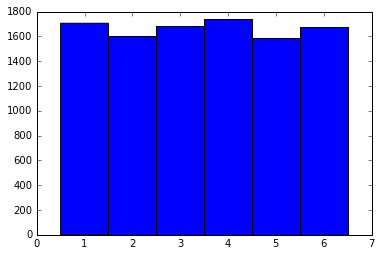
可以看到1~6分布都比较平均,不错。
我们接下来随便先拿一组抽样,手动算一下。例如我们先从生成的数据中随机抽取10个数字:
sample1 = []
for i in range(0, 10):
sample1.append(random_data[int(np.random.random() * len(random_data))])
print sample1 # 打印出来
这10个数字的结果是: [3, 4, 3, 6, 1, 6, 6, 3, 4, 4]
平均值:4.0
标准差:1.54
可以看到,我们只抽10个的时候,样本的平均值(4.0)会距离总体的平均值(3.5)有所偏差。
有时候我们运气不好,抽出来的数字可能偏差很大,比如抽出来10个数字都是6。那平均值就是6了。
我们让中心极限定理发挥作用。现在我们抽取1000组,每组50个。
我们把每组的平均值都算出来。
samples = []
samples_mean = []
samples_std = []
for i in range(0, 1000):
sample = []
for j in range(0, 50):
sample.append(random_data[int(np.random.random() * len(random_data))])
sample_np = np.array(sample)
samples_mean.append(sample_np.mean())
samples_std.append(sample_np.std())
samples.append(sample_np)
samples_mean_np = np.array(samples_mean)
samples_std_np = np.array(samples_std)
print samples_mean_np
这一共1000个平均值大概是这样的:[3.44, 3.42, 3.22, 3.2, 2.94 … 4.08, 3.74]
然后,我们把这1000个平均值用直方图画出来:
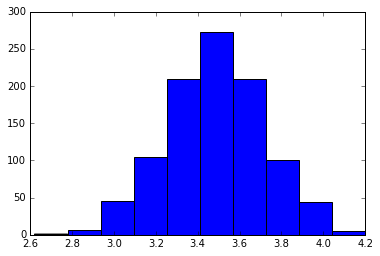
完美地形成了正态分布。
结果打印如下:
平均值:3.48494
标准差:0.23506
在实际生活当中,我们不能知道我们想要研究的对象的平均值,标准差之类的统计参数。中心极限定理在理论上保证了我们可以用只抽样一部分的方法,达到推测研究对象统计参数的目的。
在上文的例子中,掷骰子这一行为的理论平均值3.5是我们通过数学定理计算出来的。而我们在实际模拟中,计算出来的样本平均值的平均值(3.48494)确实已经和理论值非常接近了。
如何计算期望值?
期望值(EV)是统计学的一个概念,用于判定一个行为可能产生的有利或不利结果。在数值统计、赌博或其他概率情景,还有股票市场投资,或拥有多种结果的许多其他情景中,知道如何计算期望值是非常实用的。要计算期望值,你必须确定情景中可能发生的各种结果,以及各种结果发生的概率或可能性。
- 确定所有可能的结果
计算多种可能性的期望值(EV),可以帮助你确定可能性最大的最终结果。首先,你必须确定可能出现的具体结果。你应该一一罗列或制作表格,以更加明确地了解各种结果。
例如,假设你有一副共52张的标准扑克牌,你想知道自己随机选一张牌最后可能得到的期望值。你必须列出所有可能的结果,即:四种不同的花色中各有一张A、2、3、4、5、6、7、8、9、10、J、Q、K。
- 为每种可能的结果赋值
有些期望值的计算会基于货币,如股票投资。有些可能基于显而易见的数值,如骰子游戏。而某些情况下,你可能需要为部分或所有可能的结果赋值。实验室实验可能就属于这类情况。例如,进行某项实验时,你可能会将阳性化学反应赋值为+1,将阴性化学反应赋值为-1,将无反应发生赋值为0。
以扑克牌为例,通常A=1,所有花牌等于10,而其他牌等于各自的牌面数字。本示例会采用这些赋值。
- 确定每种可能结果的概率
概率指的是每个特定值或结果出现的可能性。在某些情况下,概率可能会受到一些外力的影响,例如股票市场。在这类示例中,要计算概率,你必须取得一些额外信息。而在摇骰子或掷硬币等随机概率问题中,概率等于给定结果的数量除以可能结果的总数。
- 例如,如果公平抛掷硬币,掷得“正面”的概率是1/2,因为硬币有一个正面,然后除以总共两种可能的结果(正面或反面),所得为1/2。
- 而以扑克牌为例,一副牌有52张,所以抽得每张牌的概率为1/52。但是需要注意的是,每副牌有四种不同的花色,而且有多张牌被赋予了相同的值,例如10这个值。制作一份如下的概率表可能会有所帮助:
- 1 = 4/52
- 2 = 4/52
- 3 = 4/52
- 4 = 4/52
- 5 = 4/52
- 6 = 4/52
- 7 = 4/52
- 8 = 4/52
- 9 = 4/52
- 10 = 16/52
- 检查所有概率的总和,看是否等于1。由于你罗列的结果代表了所有可能性,因此概率的总和应该等于1。
- 将每个值乘以其各自的概率
每种可能的结果代表你所计算的问题或实验的总期望值的一部分。要求得每种结果的部分值,应使用结果的值乘以其概率。
以扑克牌为例,使用你刚刚制作的概率表。将每张牌的值乘以其各自的概率。计算如下:
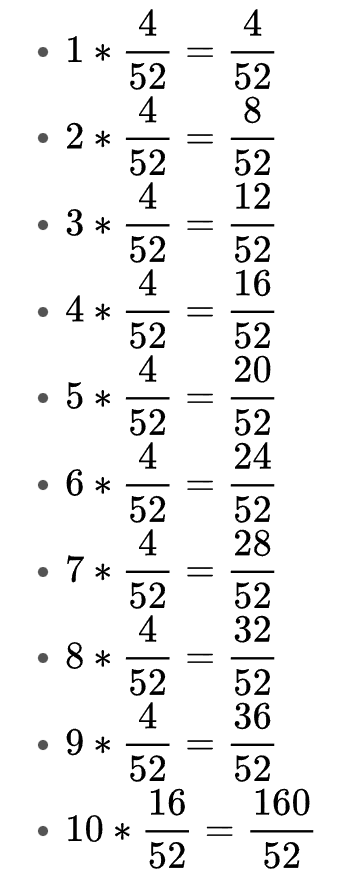
- 将乘积加总求和
一组结果的期望值(EV)等于各结果值与其概率的乘积之和。使用你为此创建的任意图表,将乘积加总,结果即为此问题的期望值。
- 以扑克牌为例,期望值等于十个单独乘积之和。结果为:
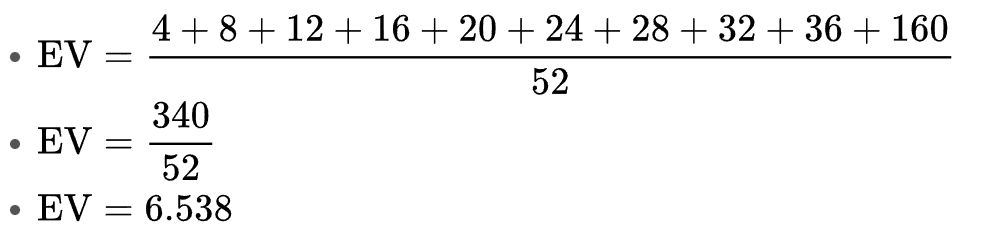
- 理解结果
期望值最适合用在会多次重复进行的测试或实验。例如,如果某个赌局每天有成千上万的赌徒参与,并且日复一日地进行,那么就能很好地应用期望值来描述预期结果。但是,期望值无法准确预测一次特定测试的某个特定结果。
- 例如,从一副标准扑克牌中抽牌时,某次抽牌抽到2的可能性与抽到6或7或8或其他数字牌的可能性是相同的。
- 多次抽牌时,理论上的期望值是6.538。显然,扑克牌里没有“6.538”这张牌。但如果正在赌博,那么你抽到大于6的牌的可能性会更高。
# Without ddof=1 , population variance is calculated instead of sample variance
# ddof = 1 代表 除数 = n -1
np.var(msleep['sleep_total'], ddof=1)
19.805677
计算样本标准差
np.std(msleep['sleep_total'], ddof=1)
# 或者 np.sqrt(np.var(msleep['sleep_total'], ddof=1))
4.450357
平均绝对偏差
对同一物理量进行多次测量时,各次测量值及其绝对误差不会相同,我们将各次测量的绝对误差取绝对值后再求平均值,并称其为平均绝对误差,即:
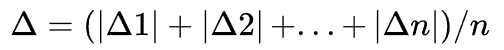
dists = msleep['sleep_total'] - mean(msleep["sleep_total"])
np.mean(np.abs(dists))
3.566701
- 标准偏差将距离平方化,对长距离的惩罚大于短距离。
- 平均绝对偏差对每个距离的惩罚是一样的。
- 一个不比另一个差,但方差比平均差更常见。
Quantiles
Quantiles「分位数」
计算分位数
0.5 quantile = median
np.quantile(msleep['sleep_total'], 0.5)
<<< 10.1
np.quantile(msleep['sleep_total'], [0, 0.25, 0.5, 0.75, 1])
<<< array([ 1.9 , 7.85, 10.1 , 13.75, 19.9 ])
Boxplots use quartiles
import matplotlib.pyplot as plt
plt.boxplot(msleep['sleep_total'])
plt.show()
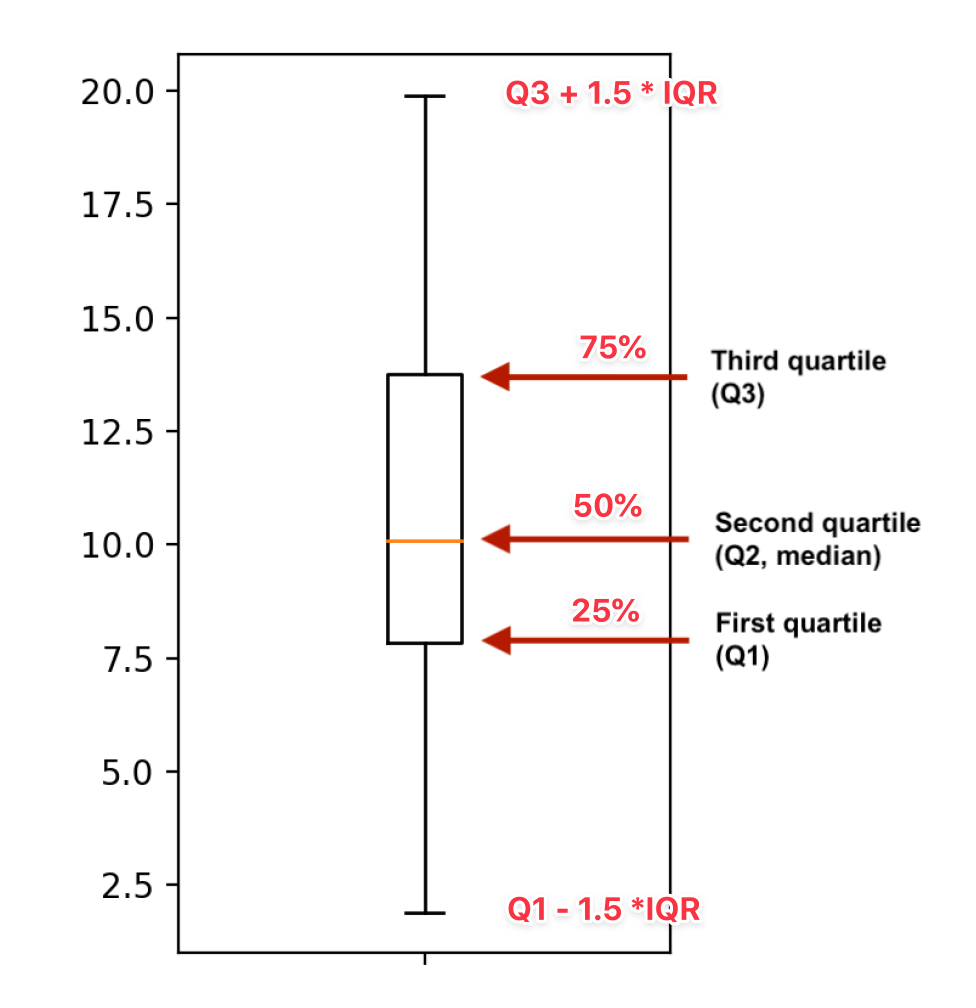
Outliers
离群点「Outliers」:与其他数据有很大差别的数据点。

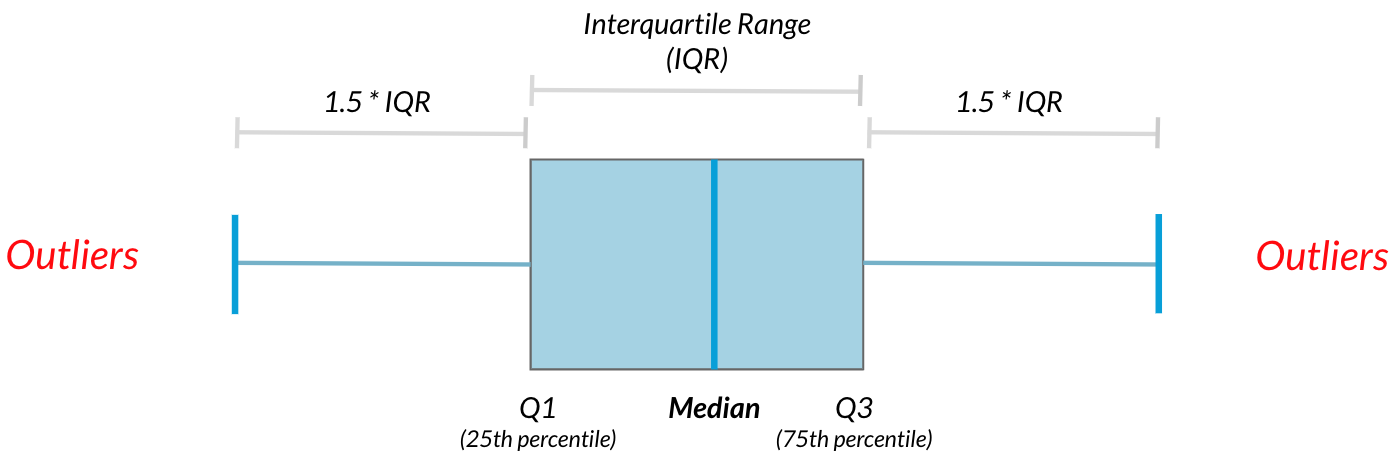
# finding outliers
from scipy.stats import iqr
iqr = iqr(msleep['bodywt'])
lower_threshold = np.quantile(msleep['bodywt'], 0.25) - 1.5 * iqr
upper_threshold = np.quantile(msleep['bodywt'], 0.75) + 1.5 * iqr
msleep[(msleep['bodywt'] < lower_threshold) | (msleep['bodywt'] > upper_threshold)]

df.describe()
msleep['bodywt'].describe()
count 83.000000
mean 166.136349
std 786.839732
min 0.005000
25% 0.174000
50% 1.670000
75% 41.750000
max 6654.000000
Name: bodywt, dtype: float64