Prediction
大约 6 分钟
Prediction
有时理解模型的最佳方法是查看其预测而不是其参数。
我们使用预测可以
- Data on explanatory values to predict: 将预测出的 属性值数据(y) 和 原本的真实数据 进行对比,以直观判断预测是否准确
- Extrapolating means making predictions outside the range of observed data: 用于新的数据的预测
实质上就是带入x 求y的值
使用回归进行新数据预测
对于之前smf.olt得到的results,将一个新的dataframe带入其中
# realinc ~ educ + educ2 + age + age2
# 创建新的df
df = pd.DataFrame()
# 打算预测学龄为12岁的各年龄段的人的收入
df['age'] = np.linspace(18, 85)
df['age2'] = df['age']**2
df['educ'] = 12
df['educ2'] = df['educ']**2
# 预测求解y,得到 pred12,一个新的series,包括每一行的 income
pred12 = results.predict(df)
# 可视化预测数据
plt.plot(df['age'], pred12, label='High school')
# 可视化原始数据
plt.plot(mean_income_by_age, 'o', alpha=0.5)
# 由于原始数据和预测数据的x轴是一致的,有对比的意义,因此可放到一张图上
plt.show()
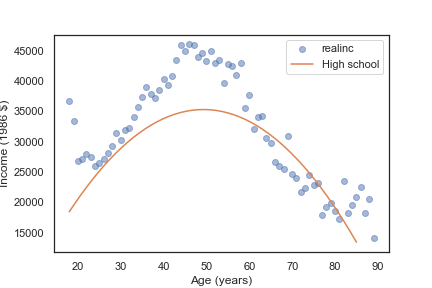
接着,我们也预测 学龄为14岁 和 学龄为16岁的各年龄段的人的收入
df['educ'] = 14
df['educ2'] = df['educ']**2
pred14 = results.predict(df)
plt.plot(df['age'], pred14, label='Associate')
df['educ'] = 16
df['educ2'] = df['educ']**2
pred16 = results.predict(df)
plt.plot(df['age'], pred16, label='Bachelor'
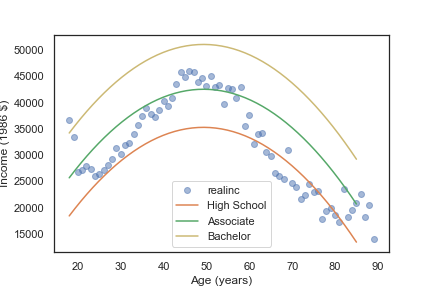
使用回归进行原始数据预测
尽管是对旧的数据进行预测,我们依旧不可直接使用原数据,因为源数据太大,会导致过度采样。
因此我们不妨和上面一样,新建一个df,参照着原始数据。
# Run a regression model with educ, educ2, age, and age2
results = smf.ols('realinc ~ educ + educ2 + age + age2', data=gss).fit()
# Make the DataFrame
df = pd.DataFrame()
df['educ'] = np.linspace(0, 20)
df['age'] = np.linspace(18, 85)
df['educ2'] = df['educ']**2
df['age2'] = df['age']**2
# Generate and plot the predictions
pred = results.predict(df)
print(pred.head())
# Plot mean income in each age group
plt.clf()
# 对于原始数据,通常只取每个年龄段的income的平均值,防止过度取样
grouped = gss.groupby('educ')
mean_income_by_educ = grouped['realinc'].mean()
plt.plot(mean_income_by_educ, 'o', alpha=0.5)
# Plot the predictions
pred = results.predict(df)
plt.plot(df['educ'], pred, label='Age 30')
# Label axes
plt.xlabel('Education (years)')
plt.ylabel('Income (1986 $)')
plt.legend()
plt.show()
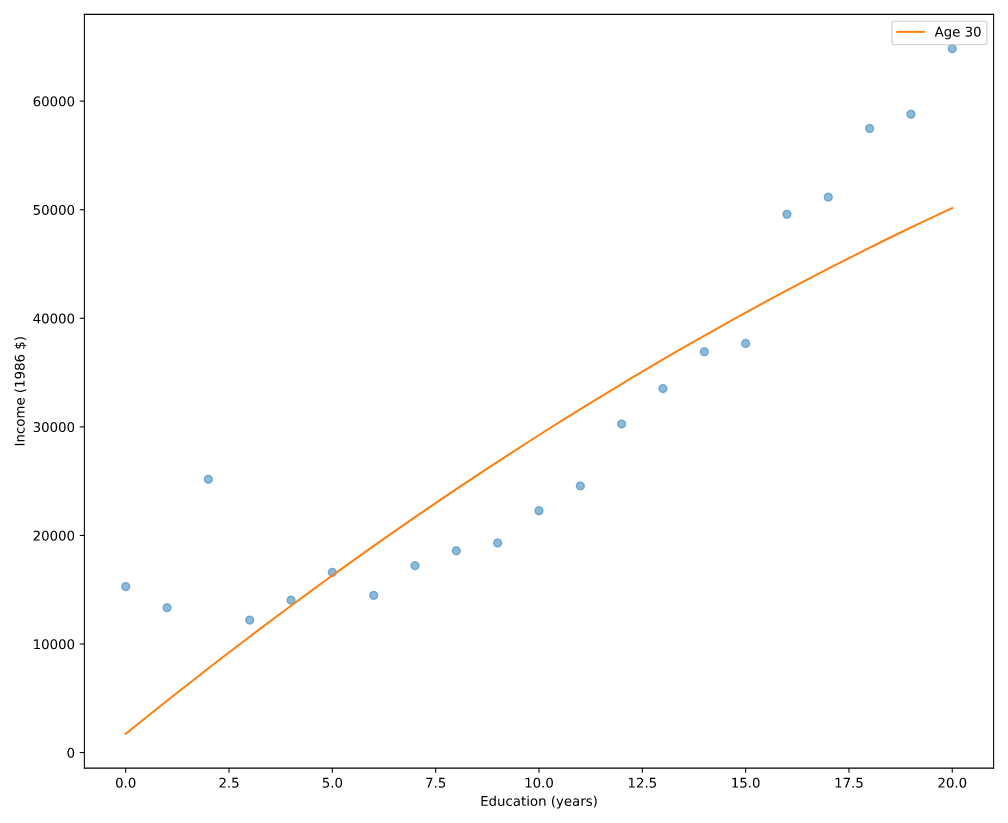
总的来说,还可以。
predict(df)
df 不必是一列,因为在ols中指定了列名,保持自变量的列名一致也是可以的。