Evaluating multiple models
大约 3 分钟
Evaluating multiple models
针对不同问题的不同模型
- Size of the dataset「数据集的大小」
- Fewer features = simpler model, faster training time
- Some models require large amounts of data to perform well
- Interpretability「解释性」
- 有些模型更容易解释,这对利益相关者来说可能很重要
- 线性回归具有很高的可解释性,因为我们可以理解系数
- Flexibility
- 通过减少对数据的假设,可以提高准确性
- KNN是一个更加灵活的模型,不假设任何线性关系
一切尽在指标中
- Regression model performance
- RMSE
- R-squared
- Classification model performance:
- Accuracy
- Confusion matrix
- Precision, recall, F1-score
- ROC AUC
训练几个模型并评估性能,开箱即用
A note on scaling
Models affected by scaling:
- KNN
- Linear Regression (plus Ridge, Lasso)
- Logistic Regression
- Articial Neural Network
Best to scale our data before evaluating models
案例
Evaluating classification models
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score, KFold, train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
# sklearn.metrics
X = music.drop("genre", axis=1).values
y = music["genre"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
models = {"Logistic Regression": LogisticRegression(), "KNN": KNeighborsClassifier(), "Decision Tree": DecisionTreeClassifier()}
results = []
for model in models.values():
kf = KFold(n_splits=6, random_state=42, shuffle=True)
cv_results = cross_val_score(model, X_train_scaled, y_train, cv=kf)
results.append(cv_results)
plt.boxplot(results, labels=models.keys())
plt.show()
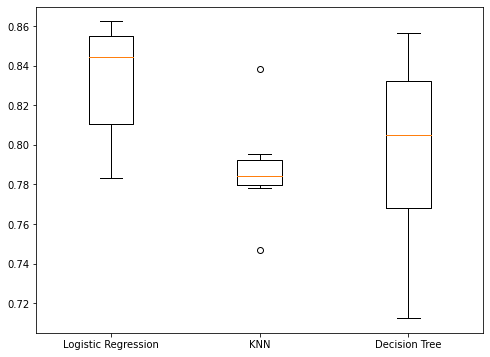
Test set performance
for name, model in models.items():
model.fit(X_train_scaled, y_train)
test_score = model.score(X_test_scaled, y_test)
print("{} Test Set Accuracy: {}".format(name, test_score))
