k-Nearest Neighbors
大约 7 分钟
k-Nearest Neighbors
Classifying labels of unseen data
之前,我们了解到监督学习使用标签。让我们讨论一下,我们如何建立一个分类模型,或分类器,来预测未见过的数据的标签。
- Build a model
- Model learns from the labeled data we pass to it
- Pass unlabeled data to the model as input
- Model predicts the labels of the unseen data
Labeled data = training data
让我们建立我们的第一个模型! 我们将使用一种叫做k-Nearest Neighbors的算法,这种算法在分类问题上很流行。k-Nearest Neighbors或KNN的概念是通过查看k个,例如三个,最接近的标记数据点,并让它们投票决定未标记的观察应该有什么标签来预测任何数据点的标签。KNN使用多数投票,根据大多数最近的邻居的标签进行预测。
KNN
随机森林本质上是许多以不同方式过拟合的决策树的集合,我们可以对这些互不相同的树的结果取平均值来降低过拟合,这样既能减少过拟合又能保持树的预测能力。常用参数有 n_estimators 和 max_features。
- 预测一个数据点的标签的方法是
- 观察最接近的k个标记的数据点
- 采取多数票的方式
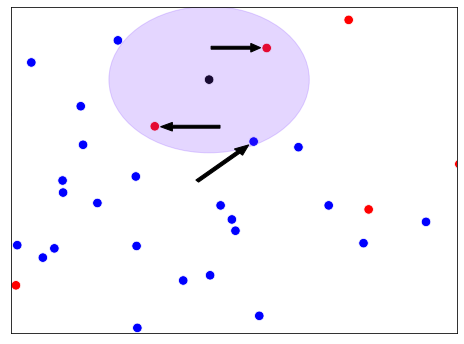
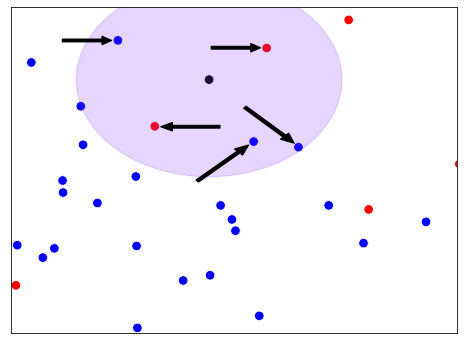
以这个散点图为例,我们如何对黑色的观察进行分类?如果k等于3,我们会把它归类为红色。这是因为在三个最接近的观测值中,有两个是红色的。如果k等于5,我们反而会把它归类为蓝色。
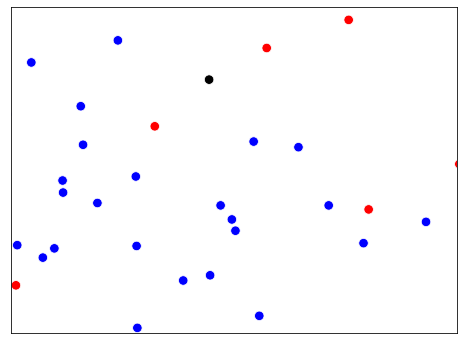
为了建立对KNN的直觉,让我们看一下这个散点图,它显示了一家电信公司的客户的晚间总费用和日间总费用。观察结果中,蓝色表示已经流失的客户,红色表示没有流失的客户。
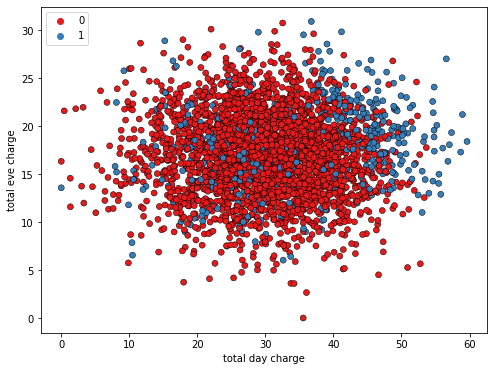
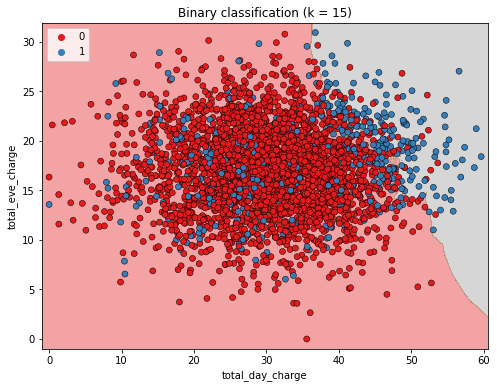
这里我们将KNN算法的结果可视化,其中邻居的数量被设置为15个。KNN创建了一个决策边界来预测客户是否会流失。在灰色背景区域的任何客户都被预测为会流失,而在红色背景区域的客户则被预测为不会流失。这个边界将被用来对未见过的数据进行预测。
Use sklearn to fit a classifier
from sklearn.neighbors import KNeighborsClassifier
X = churn_df[["total_day_charge", "total_eve_charge"]].values
y = churn_df["churn"].values
print(X.shape, y.shape)
(3333, 2), (3333,)
knn = KNeighborsClassifier(n_neighbors=15)
knn.fit(X, y)
Predicting on unlabeled data
X_new = np.array([[56.8, 17.5],[24.4, 24.1],[50.1, 10.9]])
predictions = knn.predict(X_new)
print('Predictions: {}'.format(predictions))
Predictions: [1 0 0]