Joining Data with pandas
大约 6 分钟
Joining Data with pandas
作者:韩佳明
未经许可,禁止转载,已做版权存证
- Tables = DataFrames
- Merging = Joining
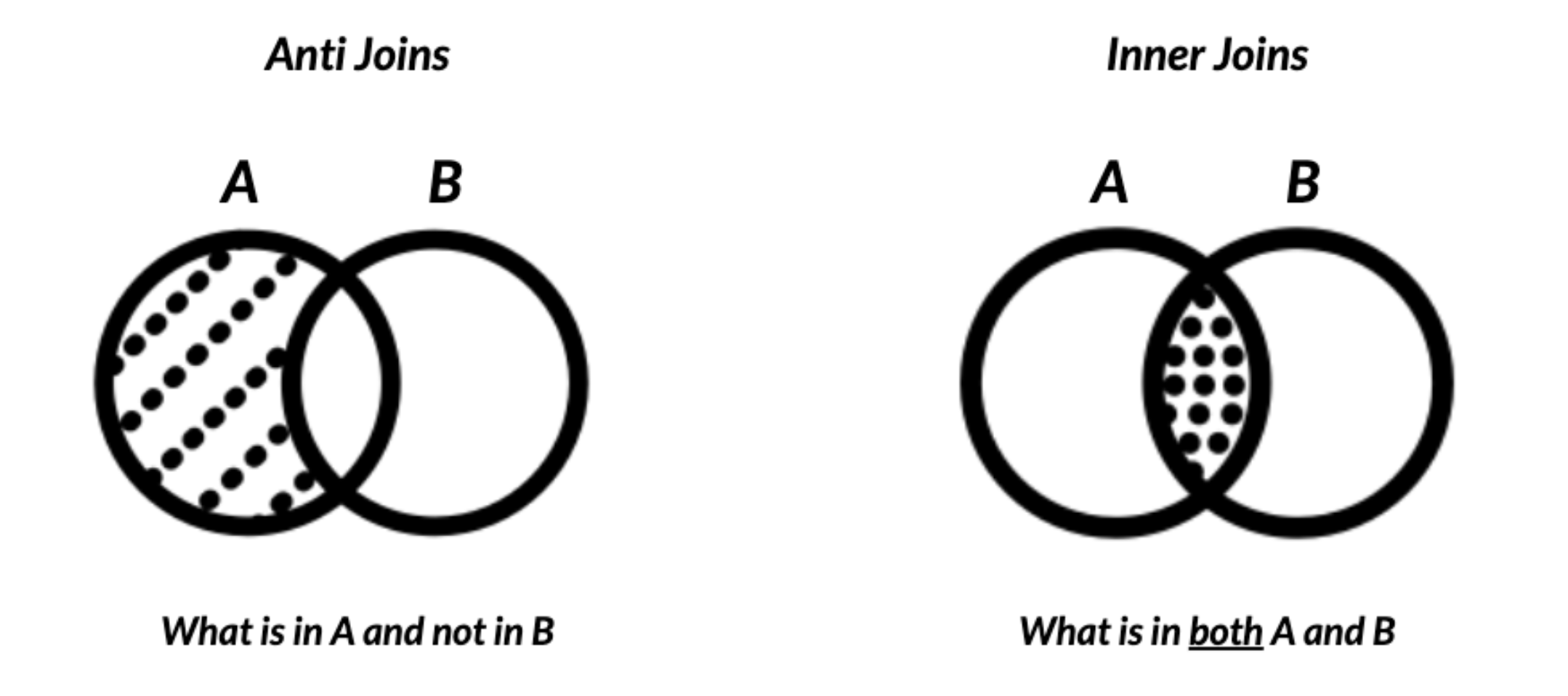
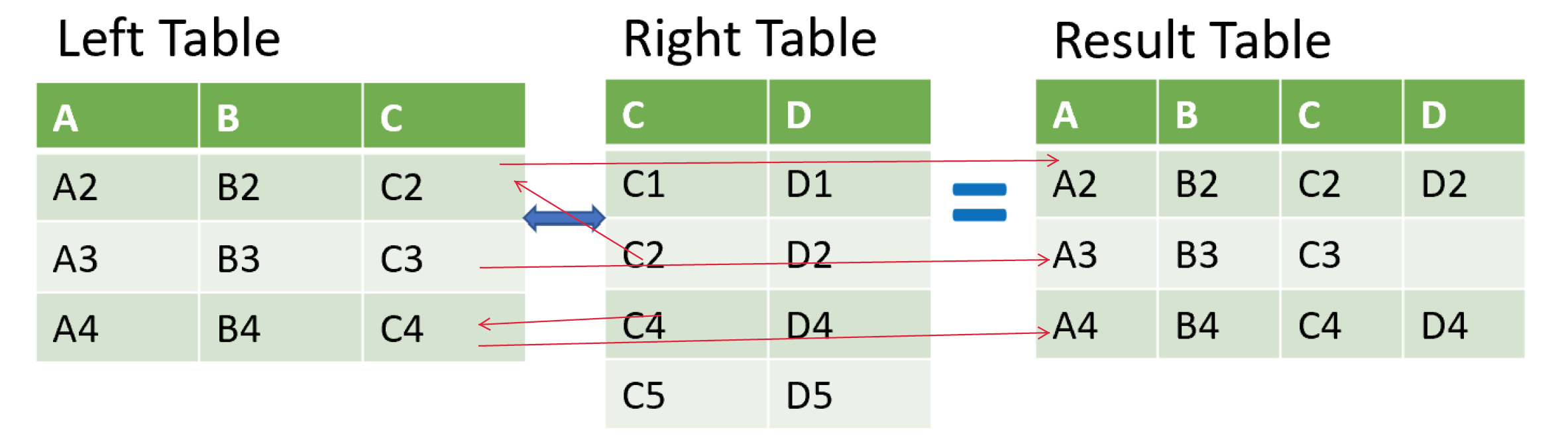
Inner join
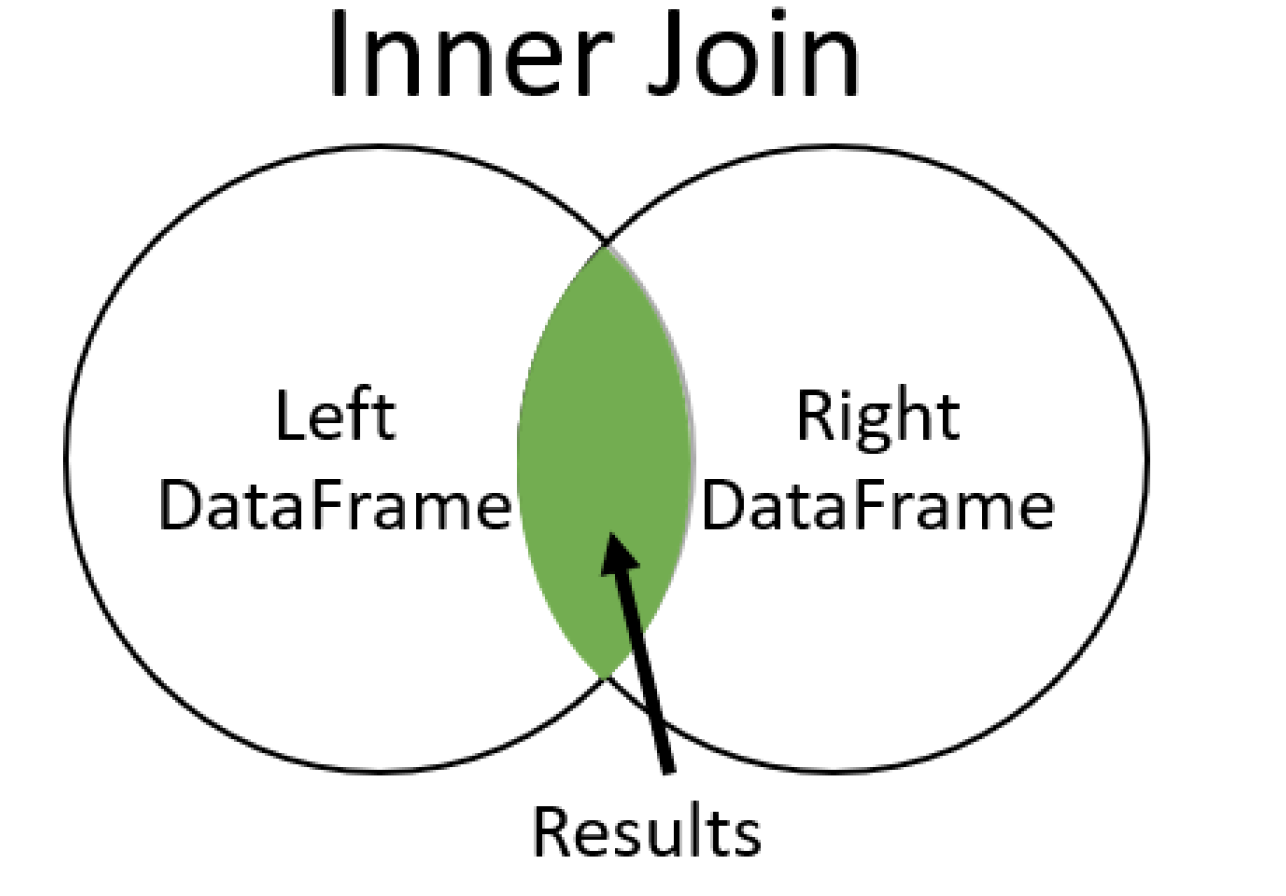
指定检查列,将数据(或pair)相同的行进行连接并保留。
wards_census = wards.merge(census, on=['ward'])
print(wards_census.head(4))
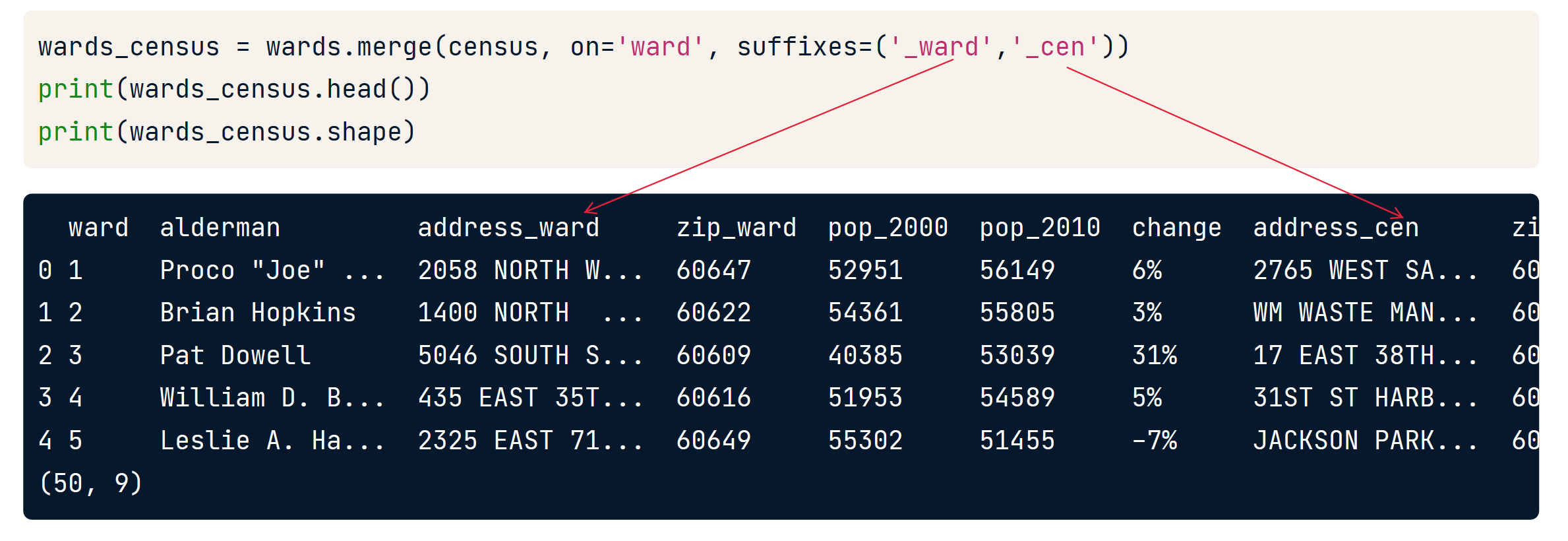
Suffixes
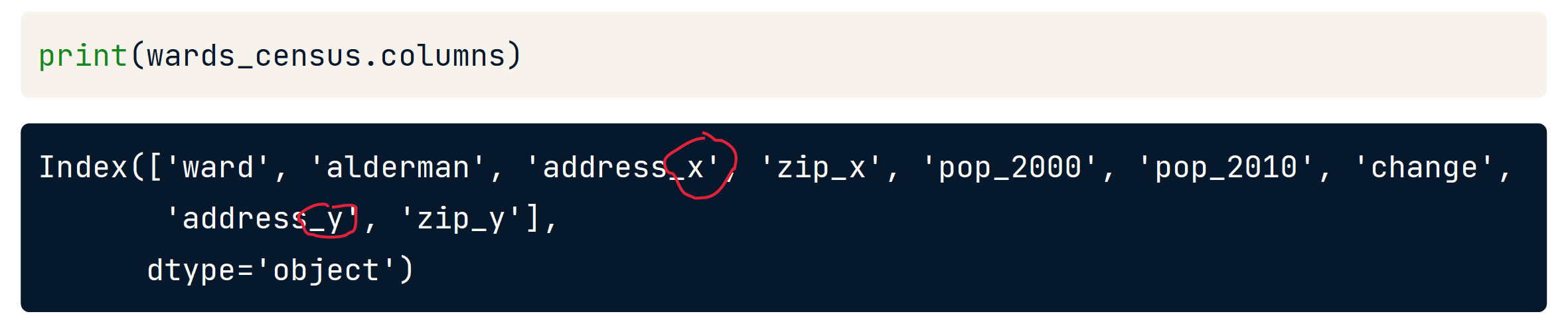
用于给相同的列名称加上自定义后缀以区分。
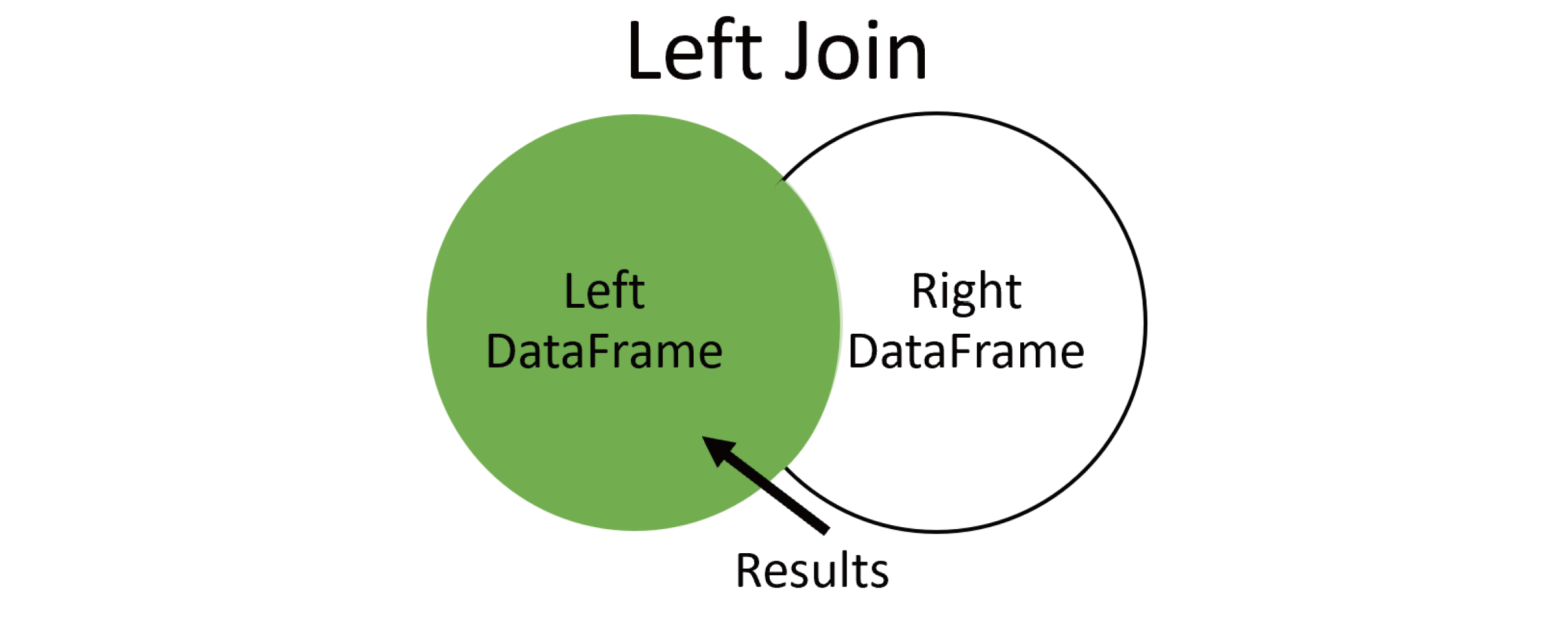
Left Join
左侧数据全部保留,将右侧数据连接到左侧。
wards_census = wards.merge(census,how = "left", on=['ward'])
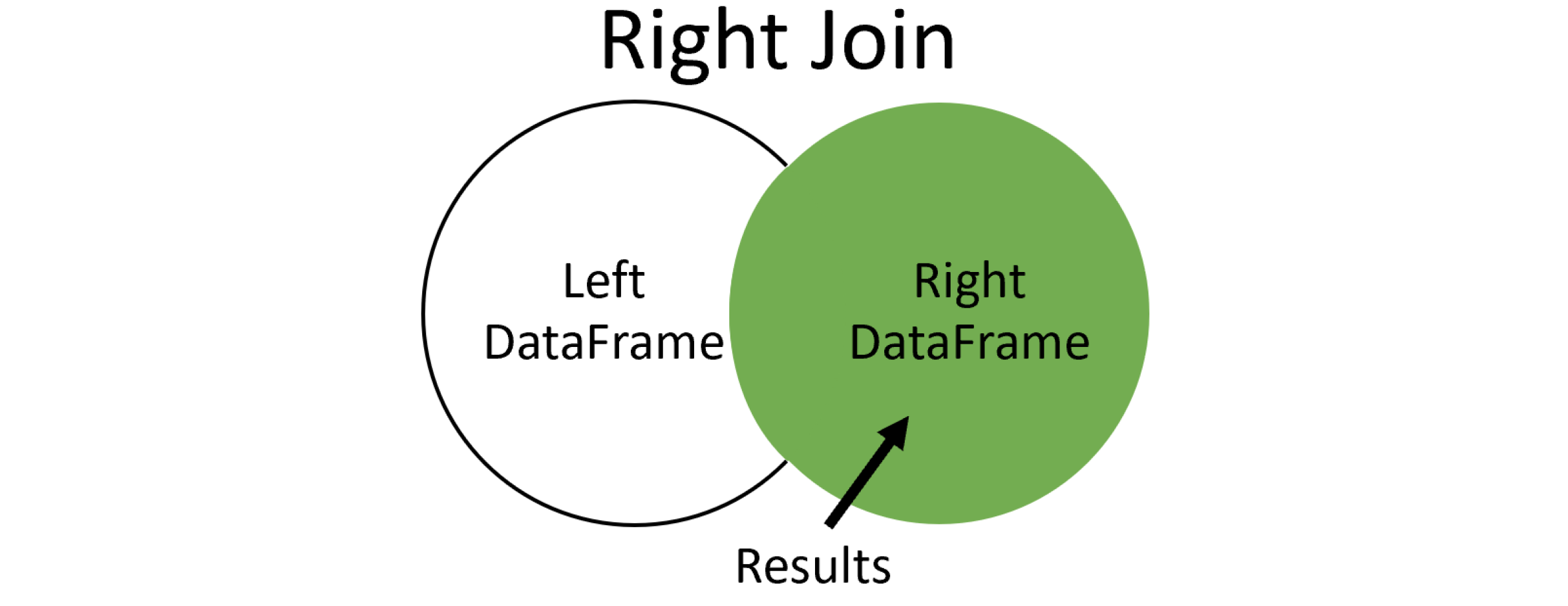
right join 则反之
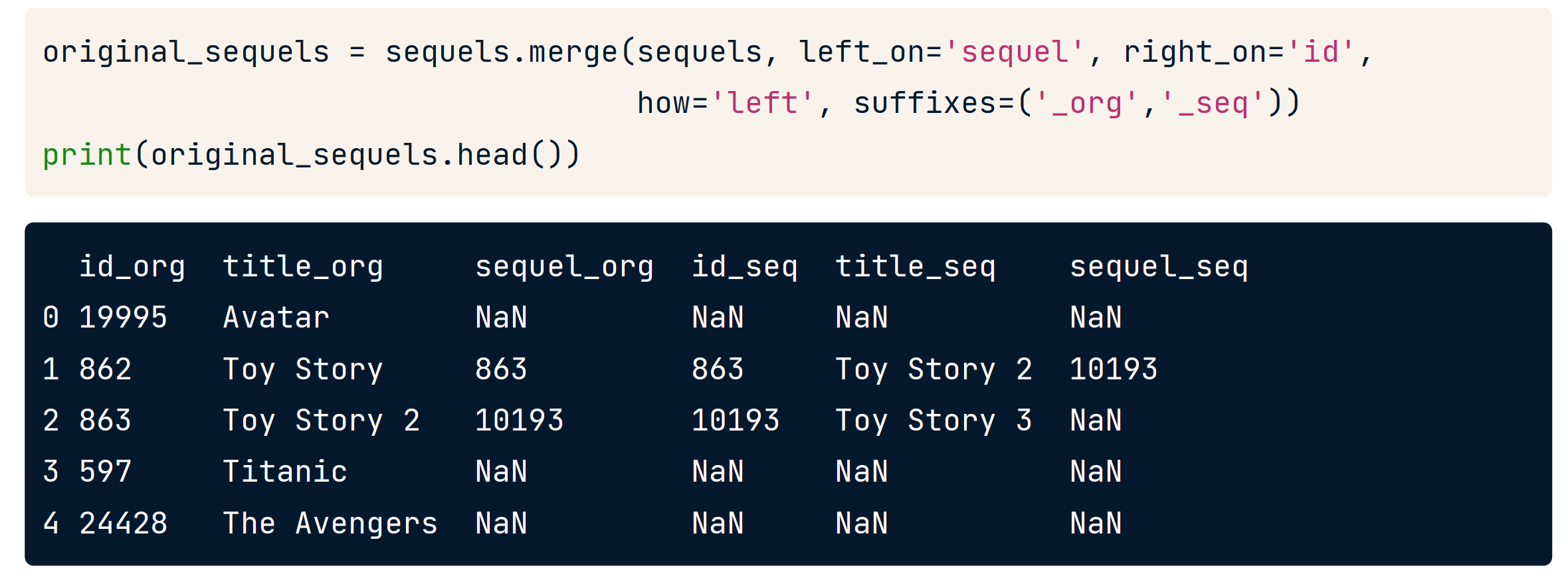
Merging a table to itself
Merging a table to itself with left join
Outer join
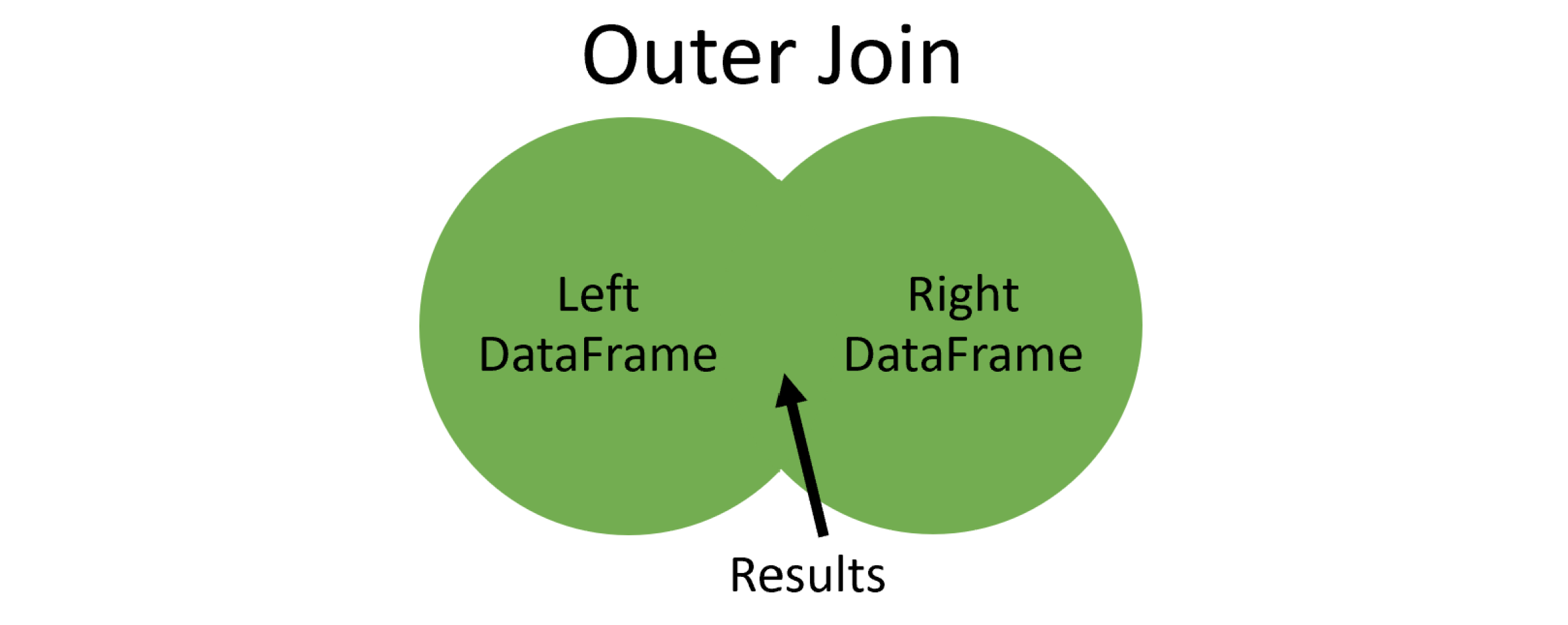
将左右进行连接,并保留没有被连接的行。
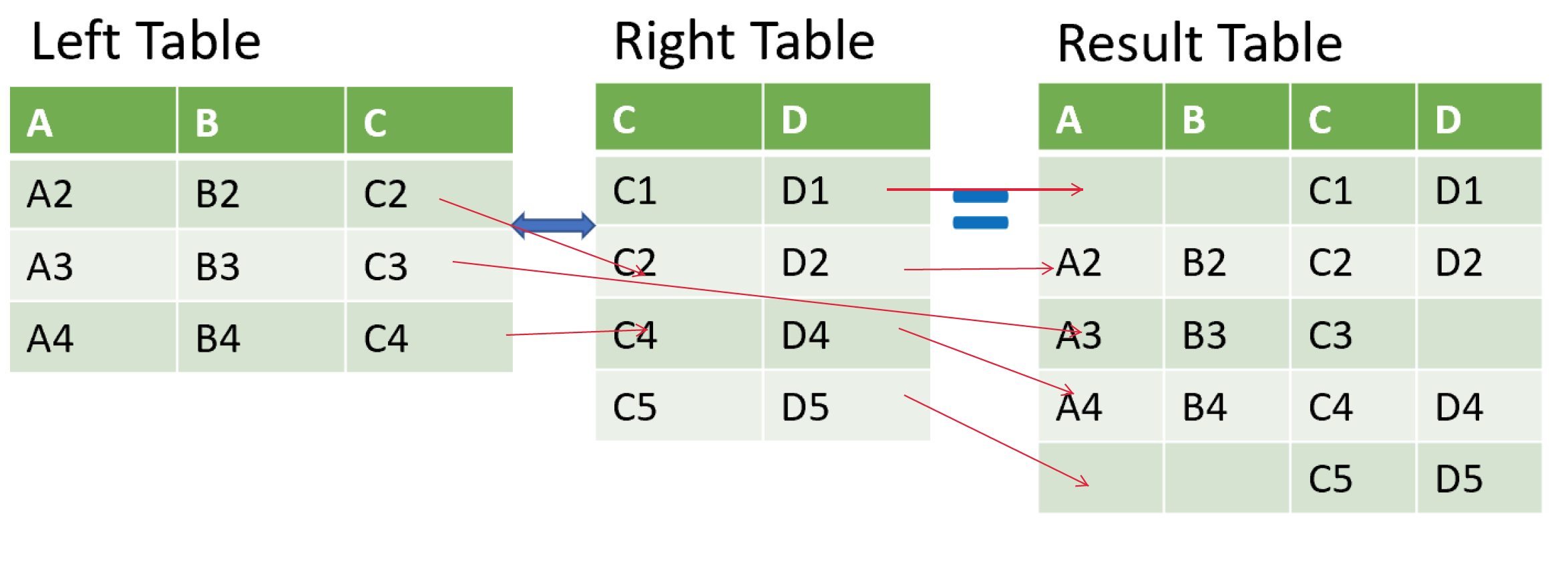
自定义检查列
original_sequels = sequels.merge(sequels, left_on='sequel', right_on='id', suffixes=('_org','_seq'))
merge_ordered()
对比

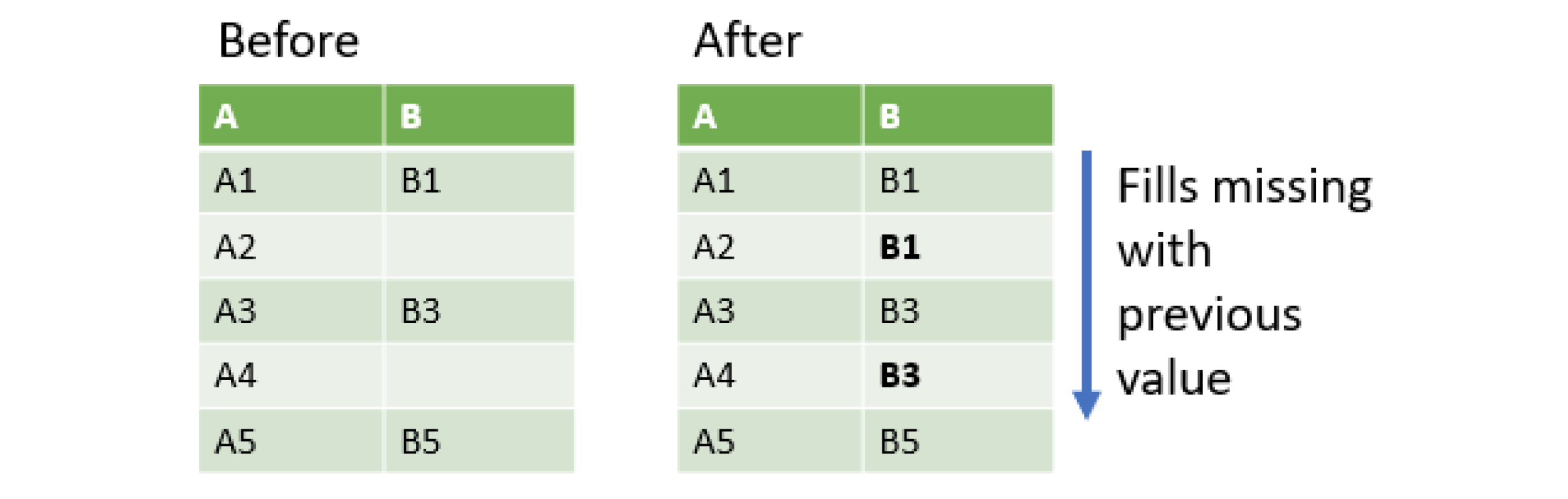
注意 默认的连接方法是outer join
pd.merge_ordered(appl, mcd, on='date', suffixes=('_aapl','_mcd'), fill_method='ffill') # 指定空数据是用前一个值
merge_asof()
- Similar to a merge_ordered() left join
- Similar features as merge_ordered()
- 非精准匹配
- merge 的 on 的 column 必须是已经排好序的
- direction 默认是 backward
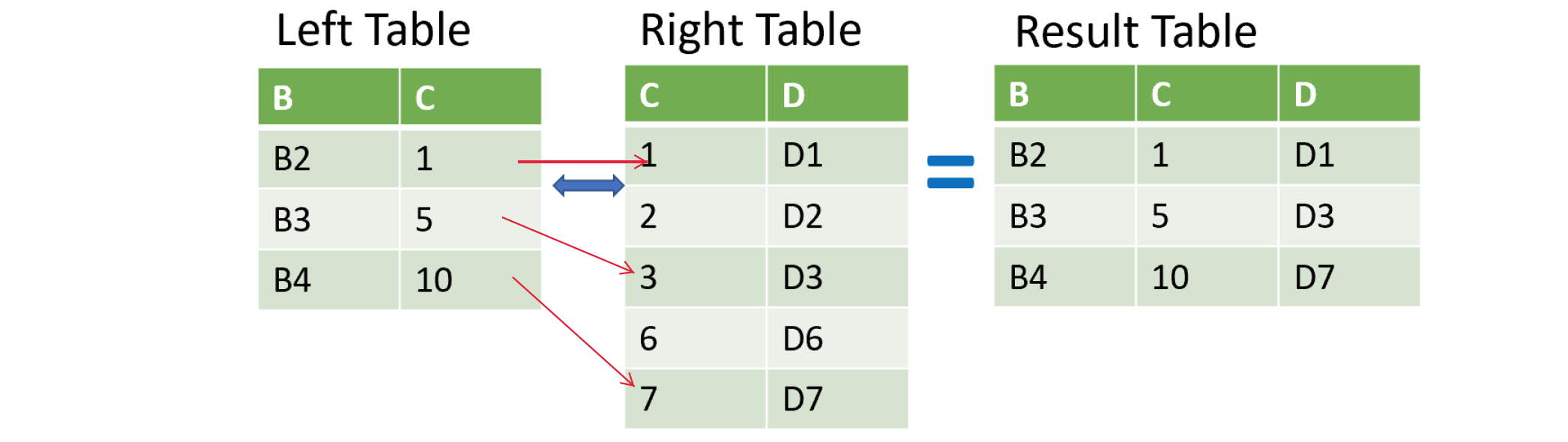
pd.merge_asof(visa, ibm, on=['date_time'],suffixes=('_visa','_ibm'),direction='forward')
# 匹配右边中不大于左边且最接近左边
变体应用
semi-join
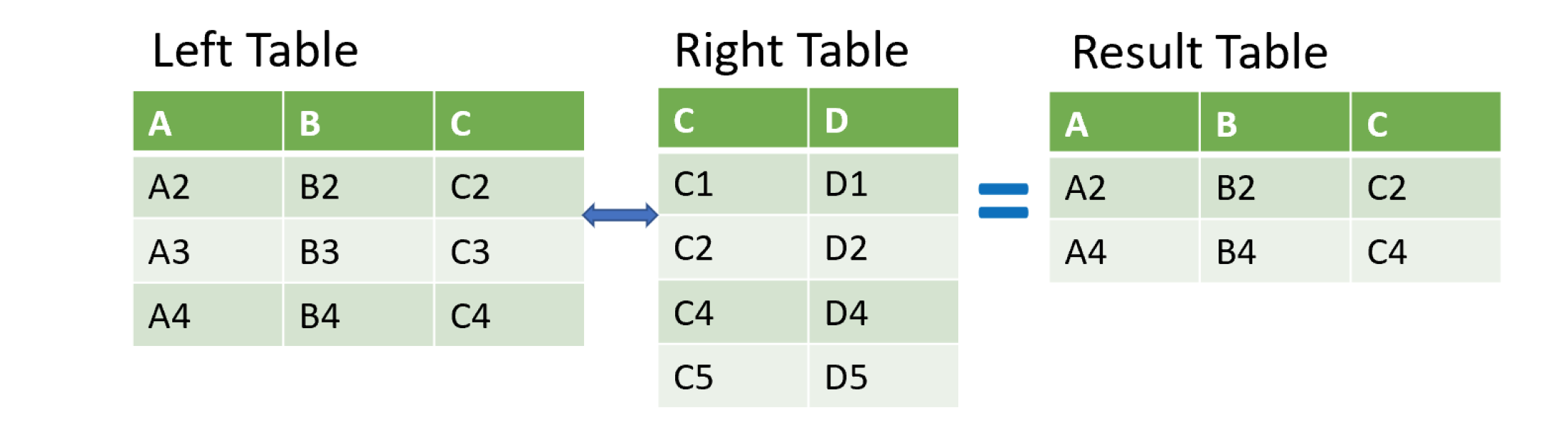
genres_tracks = genres.merge(top_tracks, on='gid')
top_genres = genres[genres['gid'].isin(genres_tracks['gid'])]
print(top_genres.head())
anti-join
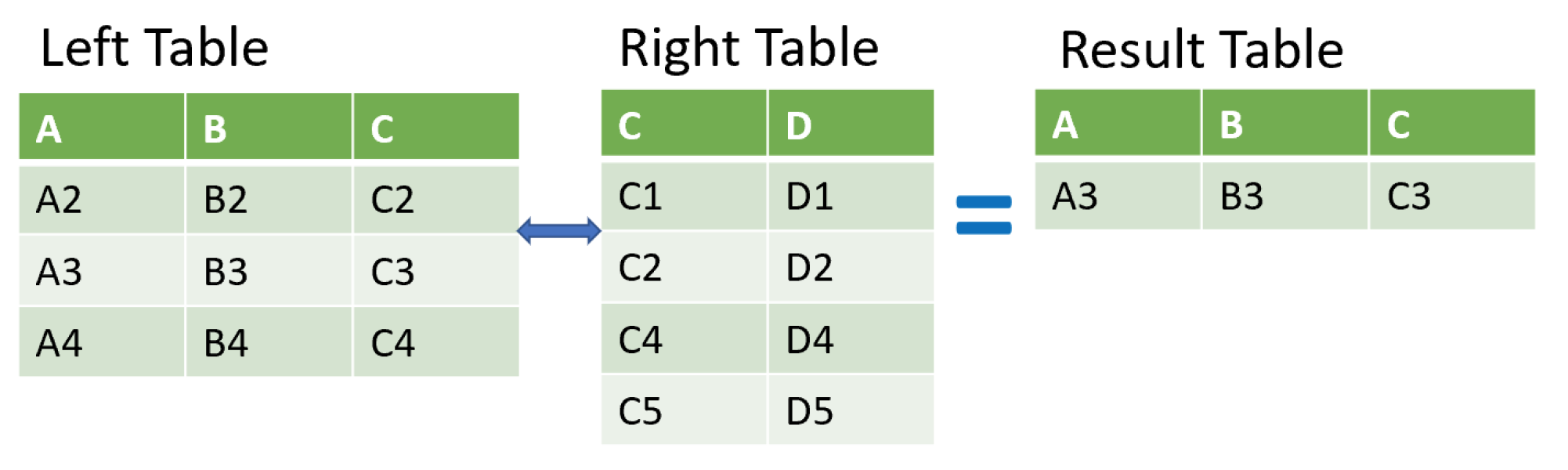
genres_tracks = genres.merge(top_tracks, on='gid', how='left', indicator=True)
gid_list = genres_tracks.loc[genres_tracks['_merge'] == 'left_only','gid']
non_top_genres = genres[genres['gid'].isin(gid_list)]
print(non_top_genres.head())
Concatenate vertically
垂直拼接
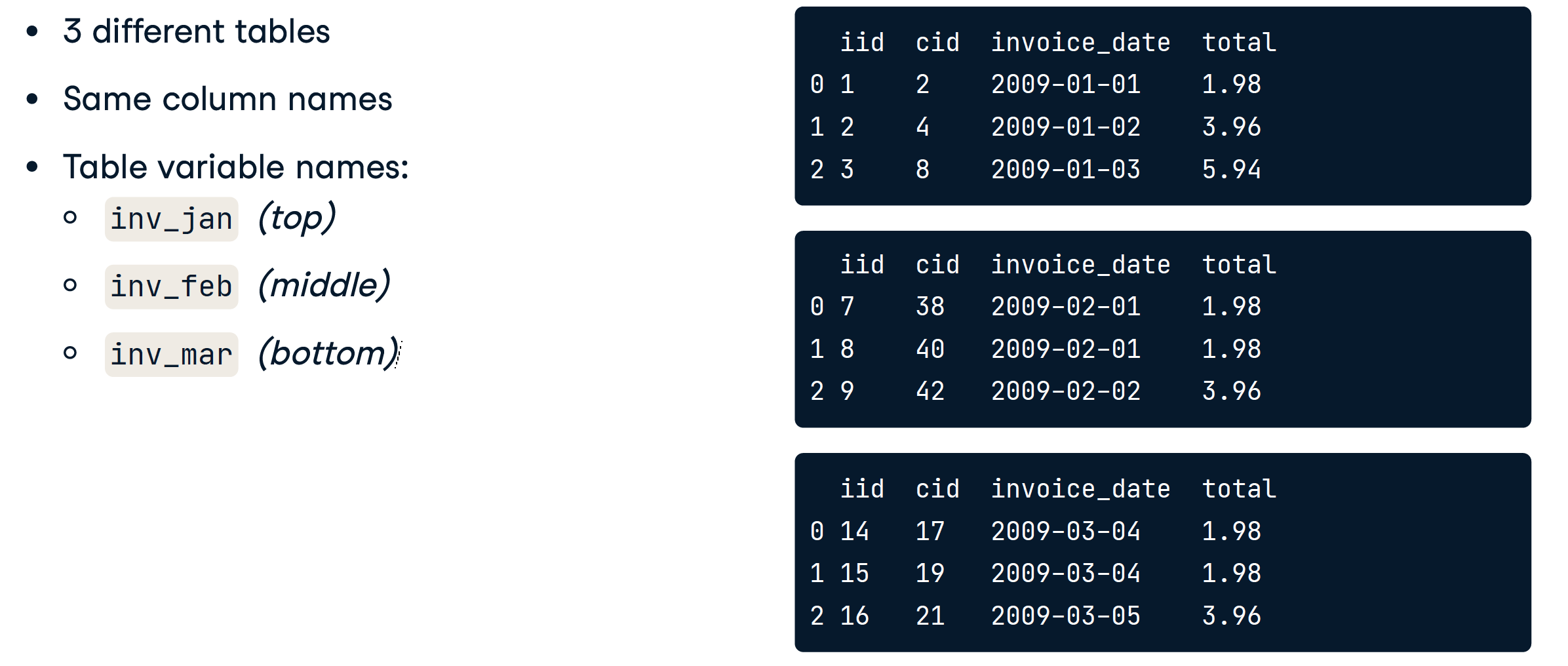
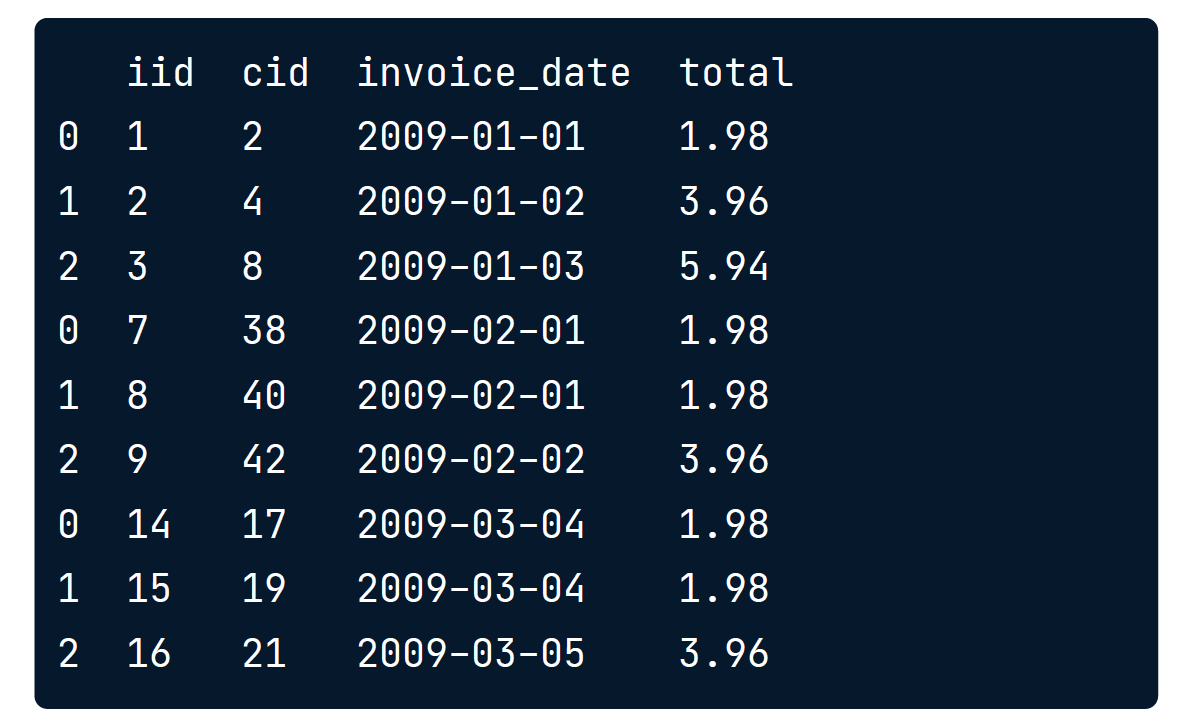
pd.concat([inv_jan, inv_feb, inv_mar], ignore_index=True)
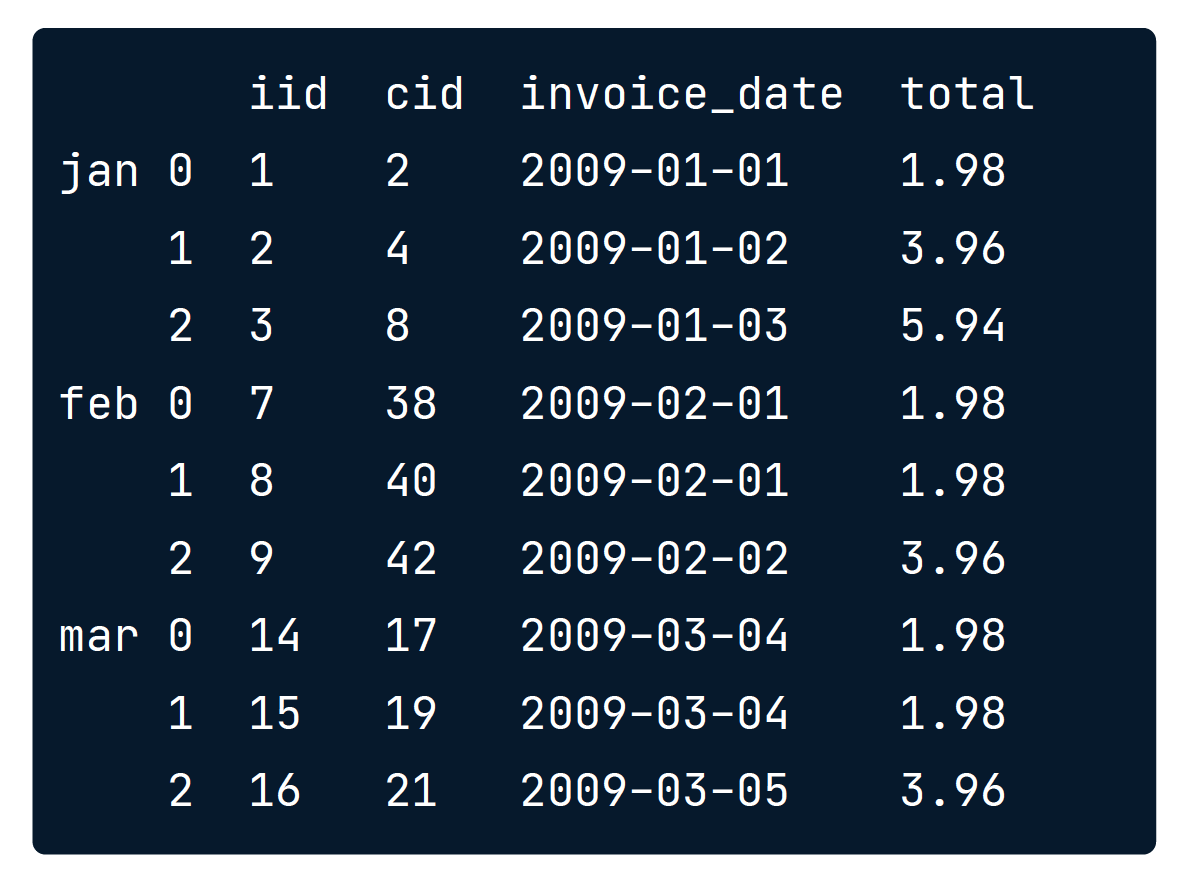
pd.concat([inv_jan, inv_feb, inv_mar],ignore_index=False,keys=['jan','feb','mar'])
sort
pd.concat([inv_jan, inv_feb], sort=True)
拼接保留列
指定参数 join,默认 仅拼接共同名称的列,
pd.concat([inv_jan, inv_feb], join='inner')
使用 append 代替concat
inv_jan.append([inv_feb, inv_mar],ignore_index=True,sort=True)
有条件的连接
适用于横向 join和垂直的拼接
为什么要有条件
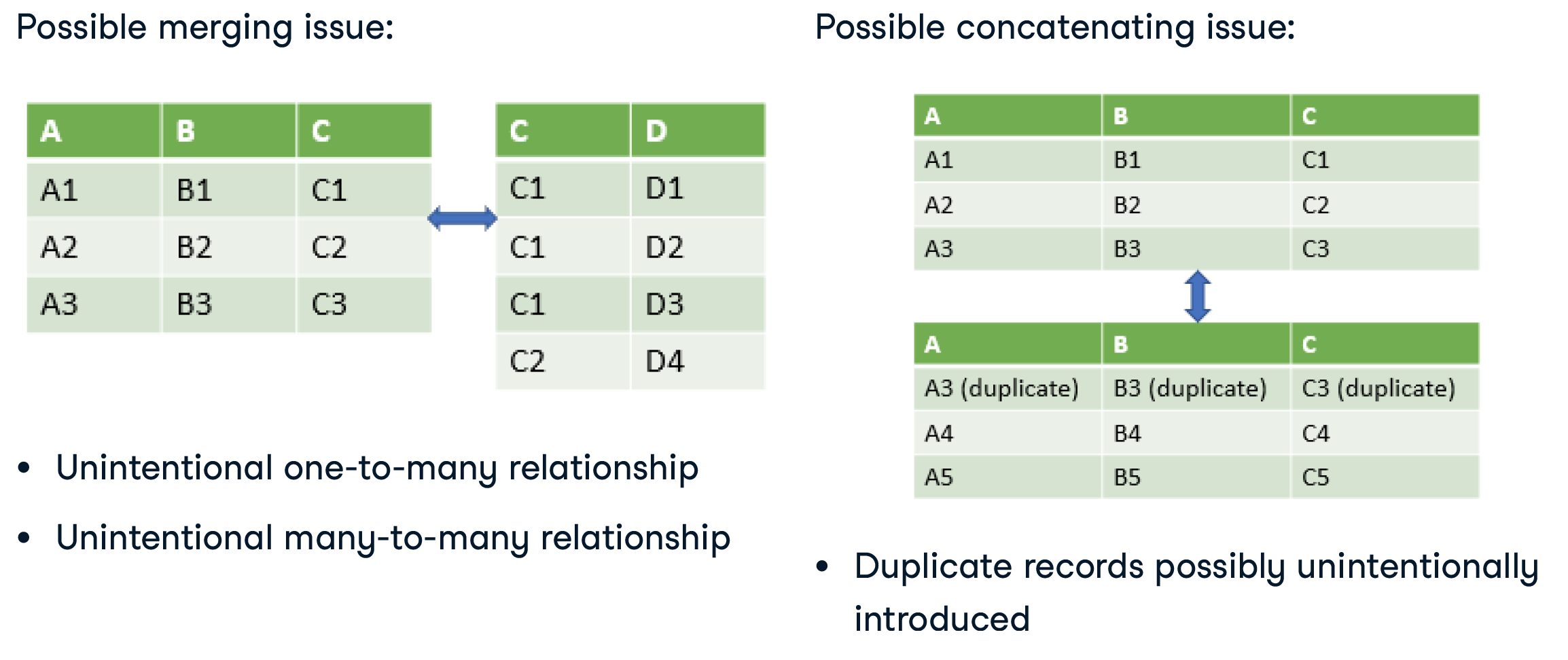
Why:
- Real world data is often NOT clean
What to do:
- Fix incorrect data
- Drop duplicate rows
条件参数
Checks if merge is of specied type
- 'one_to_one'
- 'one_to_many'
- 'many_to_one'
- 'many_to_many'
.merge(validate=None)
即连接前先检查是否符合条件,符合条件才会连接,不符合就不连接。