Understand Pandas
大约 10 分钟
Understand Pandas
Pandas 数据结构
- Pandas 主要是 DataFrame & Series
- Numpy 主要是 ndarray
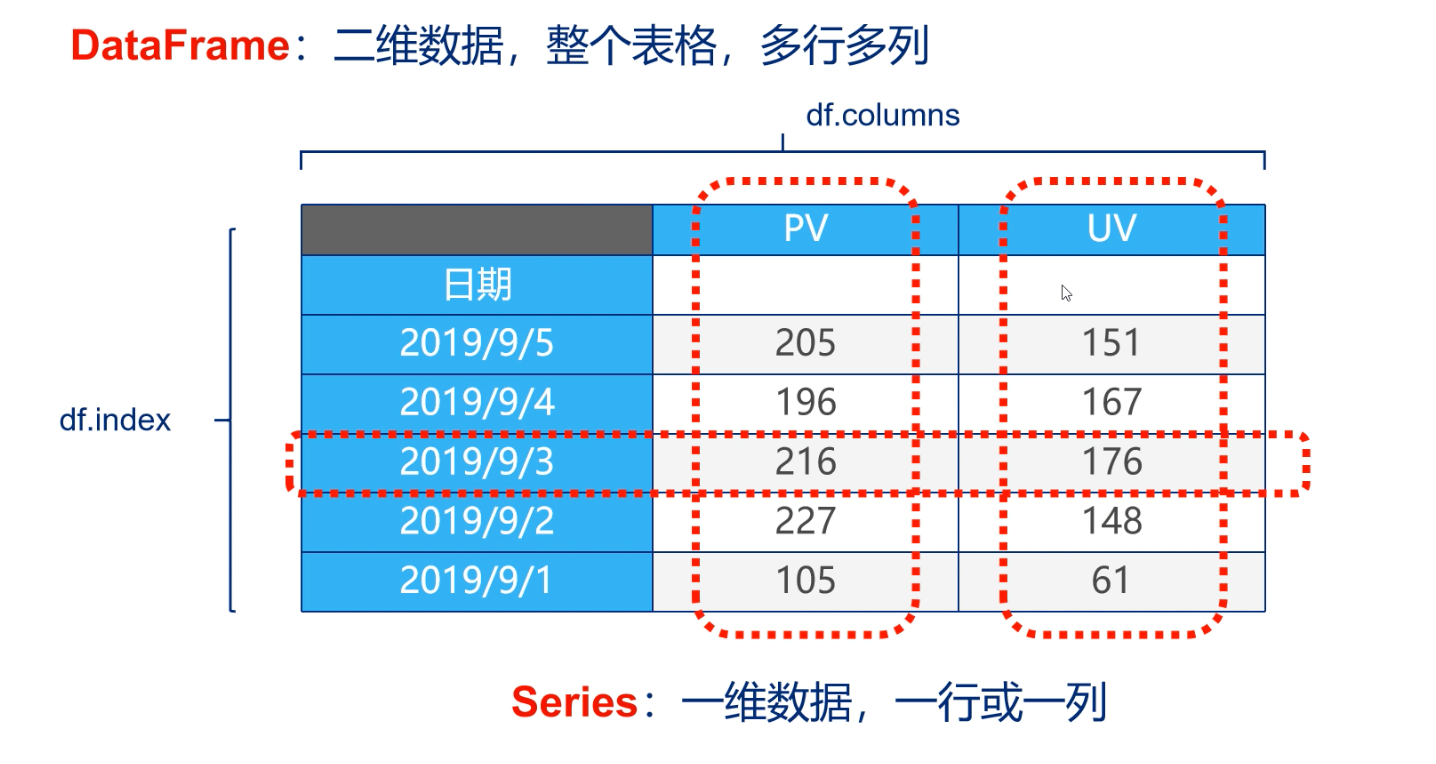
当然DataFrame可能有多维数据
仅有数据列表即可产生最简单的Series
创建Series
s1 = pd.Series([1,'a',5.2,7])
s1
0 1
1 a
2 5.2
3 7
dtype: object
创建一个具有标签索引的Series
s2 = pd.Series([1, 'a', 5.2, 7], index=['d','b','a','c'])
使用Python字典创建Series
sdata={'Ohio':35000,'Texas':72000,'Oregon':16000,'Utah':5000}
s3=pd.Series(sdata)
创建DataFrame
# Create a empty dataframe
df = pd.DataFrame()
SettingWithCopyWarning
核心要诀: pandas的dataframel的修改写操作,只允许在源dataframe上进行,一步到位
复现
# 只选出3月份的数据用于分析
# 返回一列布尔值
condition = df["ymd"].str.startswith("2018-03")
# 设置温差
# 这一步发生警告
df[condition]["wen_cha"] = df["bWendu"]-df["yWendu"]
原因是链式操作,其实是两个步骤,先get后set,get得到的dataframe可能是view也可能是copy,pandas发出警告
总之,pandas不允许先筛选子dataframe,再进行修改写入
解决方案
使用loc
Pandas 元素方法
Pandas 的元素操作一般都是一整行或者一整列,即pd.Series。因此需要使用pd元素定义的方法处理。当然也可以用apply。
Series.str字符串方法列表参考文档: https://pandas.pydata.org/pandas-docs/stable/reference/series.html#string-handling
其实和Python 中的String的用法很相似。
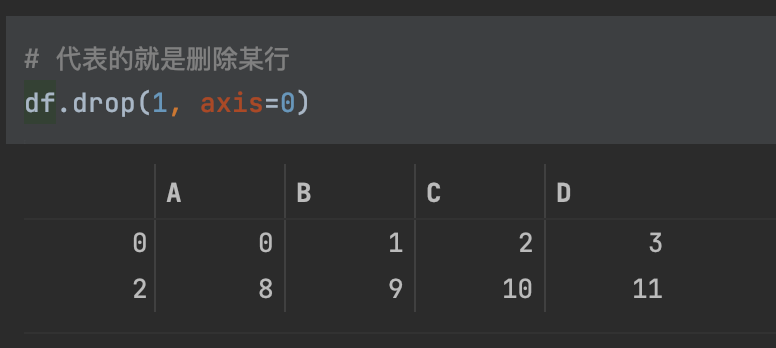
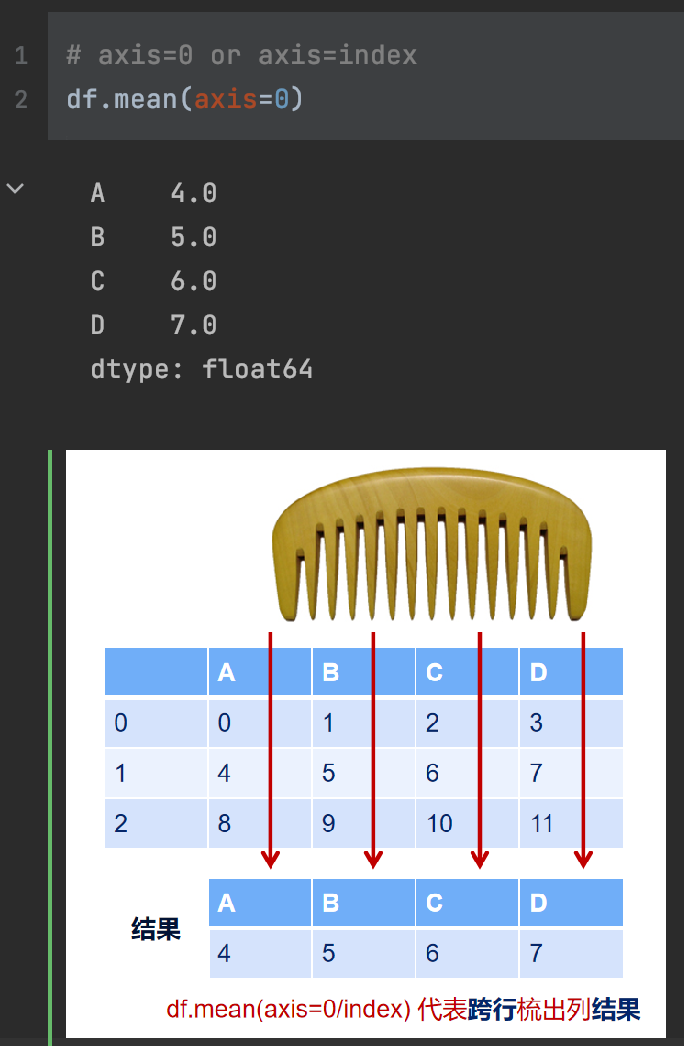
Axis 参数
- axis=0 或者"index":
- 如果是单行操作,就指的是某一行
- 如果是聚合操作,指的是跨行cross rows
- axis=1 或者"columns":
- 如果是单列操作,就指的是某一列
- 如果是聚合操作,指的是跨列cross columns
按哪个axis,就是这个axis要动起来(类似被for遍历),其它的axis保持不变化

index 作用
index的用途总结
- 更方便的数据查询;
- 使用index可以获得性能提升;
- 自动的数据对齐功能;
- 更多更强大的数据结构支持;
使用index会提升查询性能
- 如果index是唯一的,Pandas会使用哈希表优化,查询性能为O(1);
- 如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
- 如果index是完全随机的,那么每次查询都要扫描全表,查询性能为O(N);
使用index更多更强大的数据结构支持
很多强大的索引数据结构
- CategoricalIndex,基于分类数据的Index,提升性能;
- MultiIndex,多维索引,用于groupby多维聚合后结果等;
- DatetimeIndex,时间类型索引,强大的日期和时间的方法支持
分层索引
为什么要学习分层索引MultiIndex?
- 分层索引:在一个轴向上拥有多个索引层级,可以表达更高维度数据的形式;
- 可以更方便的进行数据筛选,如果有序则性能更好;
- groupby等操作的结果,如果是多KEY,结果是分层索引,需要会使用
- 一般不需要自己创建分层索引(MultiIndex有构造函数但一般不用)
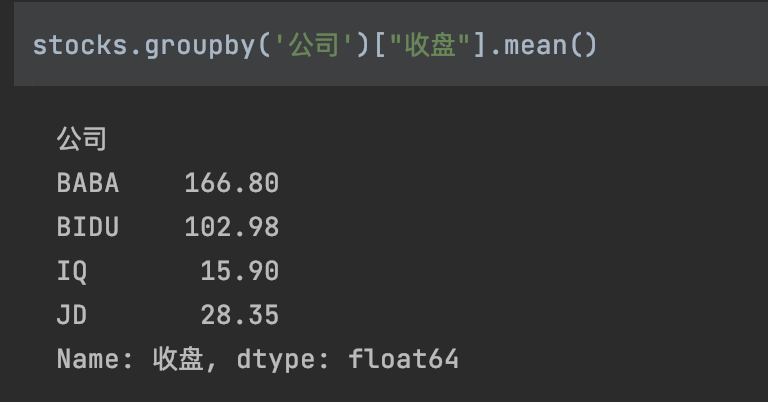
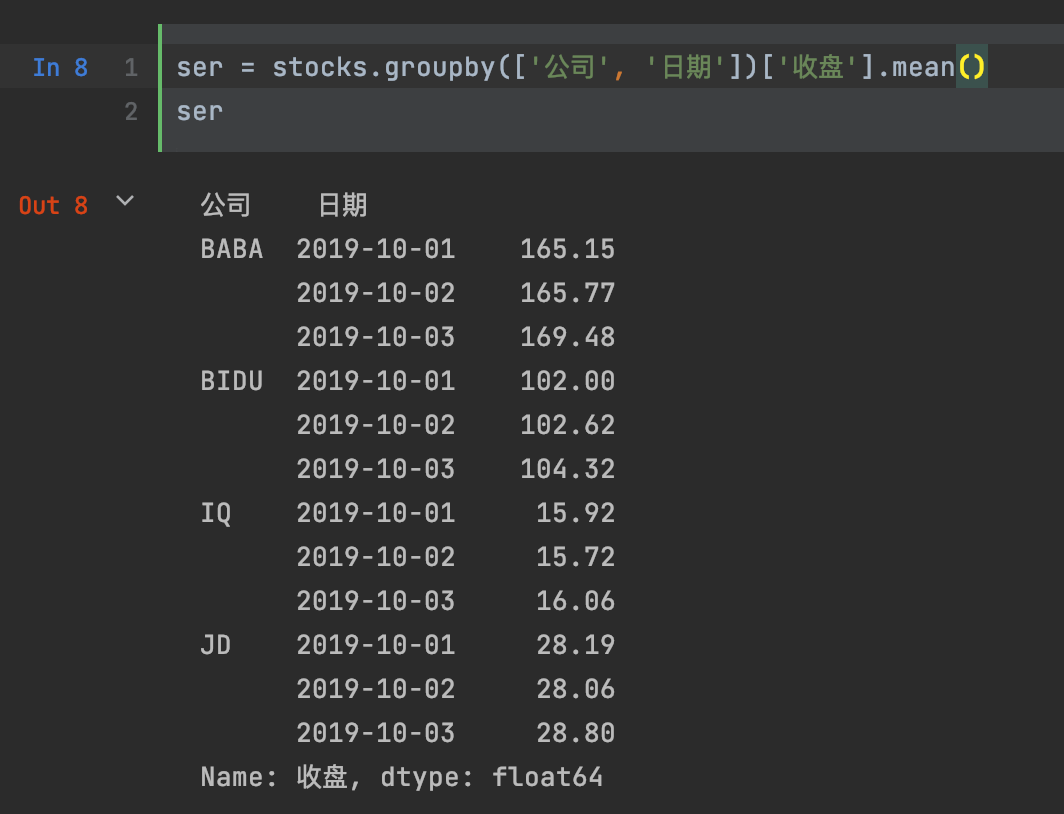
>>> ser.index
MultiIndex([('BABA', '2019-10-01'),
('BABA', '2019-10-02'),
('BABA', '2019-10-03'),
('BIDU', '2019-10-01'),
('BIDU', '2019-10-02'),
('BIDU', '2019-10-03'),
( 'IQ', '2019-10-01'),
( 'IQ', '2019-10-02'),
( 'IQ', '2019-10-03'),
( 'JD', '2019-10-01'),
( 'JD', '2019-10-02'),
( 'JD', '2019-10-03')],
names=['公司', '日期'])
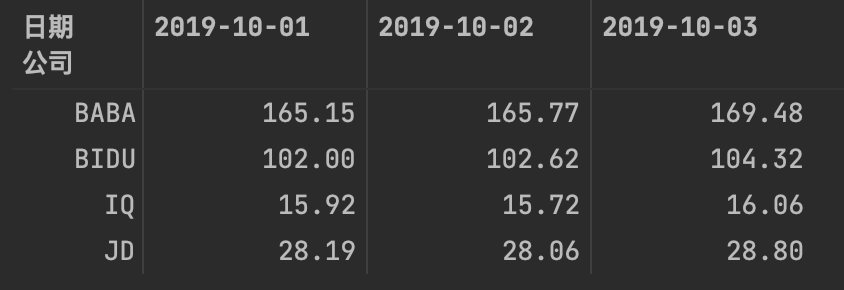
# unstack把二级索引变成列
ser.unstack()
# 多层索引,可以用元组的形式筛选
ser.loc[('BIDU', '2019-10-02')]
DataFrame有多层索引MultiIndex怎样筛选数据?
在选择数据时:
- 元组(key1,key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
- 列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU