Spark RDD
Spark RDD
Resilient Distributed Datasets (RDD)
Spark RDD 在逻辑上被划分为多个节点,以便在集群的不同节点上并行计算。
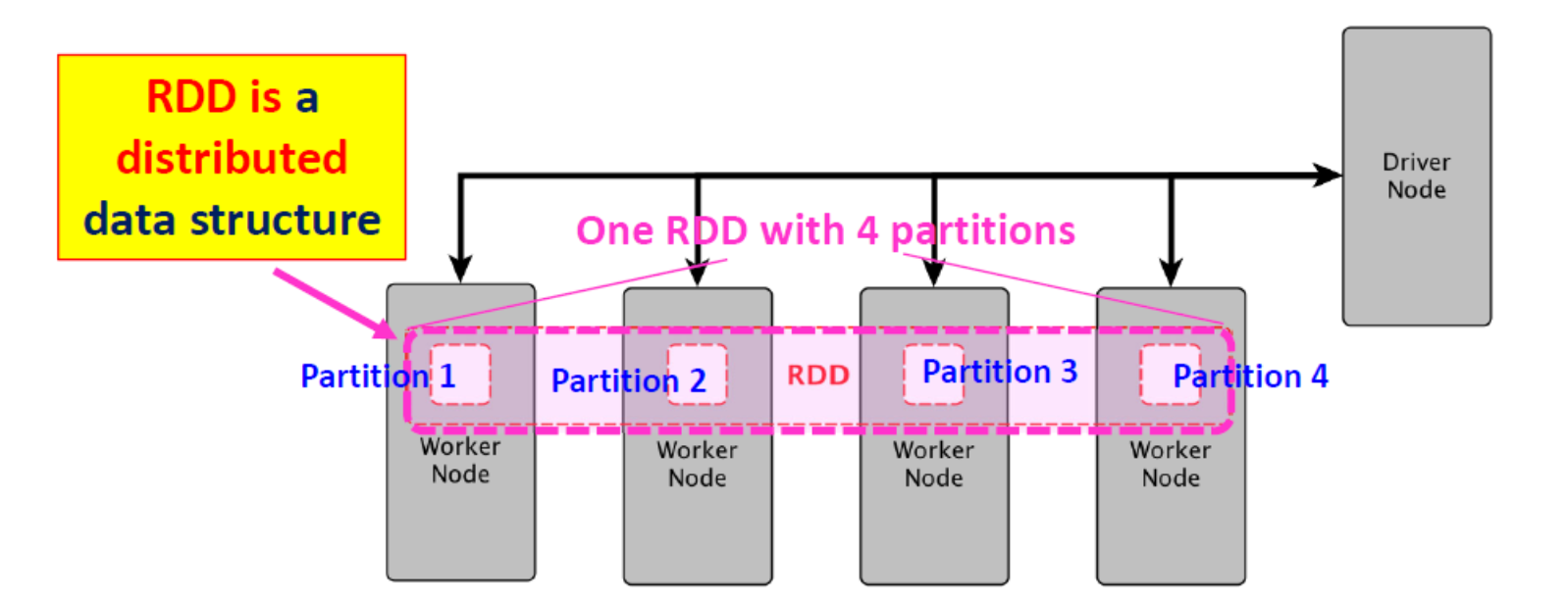
RDD: a distributed data structure !
- RDDs are divided into smaller chunks called partitions「分区」
- The maximum size of a partition 2GB
- Partitions of an RDD are distributed across all the nodes in the cluster.
- Two types of operations that you can perform on an RDD: Transformations and Actions
- RDD 是 "不可变「immutable」 "的(即创建后不可修改)-> 当您可以通过转换修改 RDD 时,转换会返回一个新的 RDD,而原始 RDD 保持不变
RDD Internal
Five main properties:
- An RDD contains list of partitions!
- function to compute (e.g.,map,flatmap,..)
- list of [parent RDD,type (wide/narrow)]
- 可选的分区方案(如 HashPartitioner、RangePartitioner)
- Optionally, a computation placement hint
- 用于计算每个分区的首选位置列表(例如 HDFS 文件的块位置)
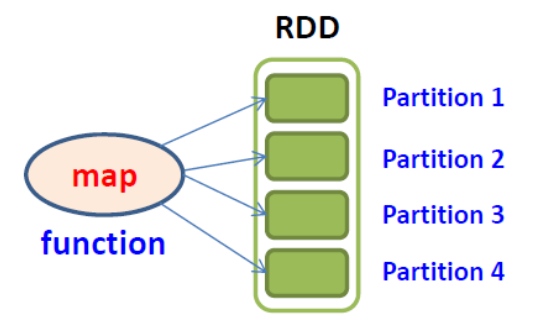
Transformations and Actions
RDD keeps a pointer to it's parent RDD(s)
- Transformations:在 RDD 上应用某些函数并创建一个新的 RDD。它不会修改您应用该函数的 RDD。
- Action 用于将结果保存到某个位置(如 HDFS、S3)或通过驱动程序显示结果。
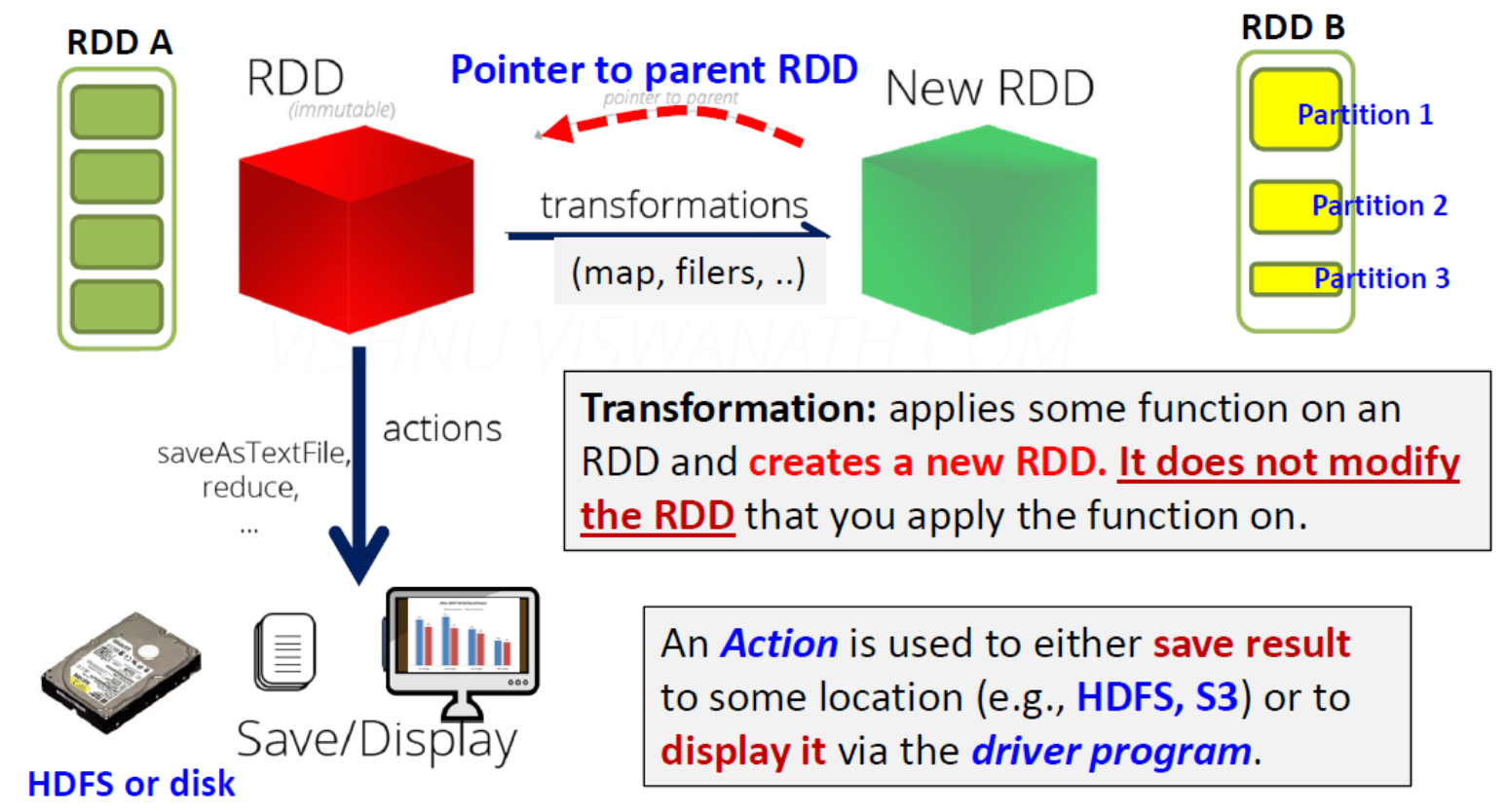
- Transformations: 每种转换都接收(一个或多个)RDD,并通过对内容应用某些函数(如 map、filter、flatMap、union、groupBy、reduceByKey、sortByKey、join)输出转换后的 RDD(另一个 RDD
- Actions: 在数据集上运行计算后,将值返回给驱动程序「driver program」(reduce、collect、count、take、countByKey)、saveAsTextFile、saveAsObjectFile,...
“Spark 中的所有转换都是惰性的”:仅当 Action 需要将结果返回给驱动程序时才计算 RDD(更多内容待讨论)
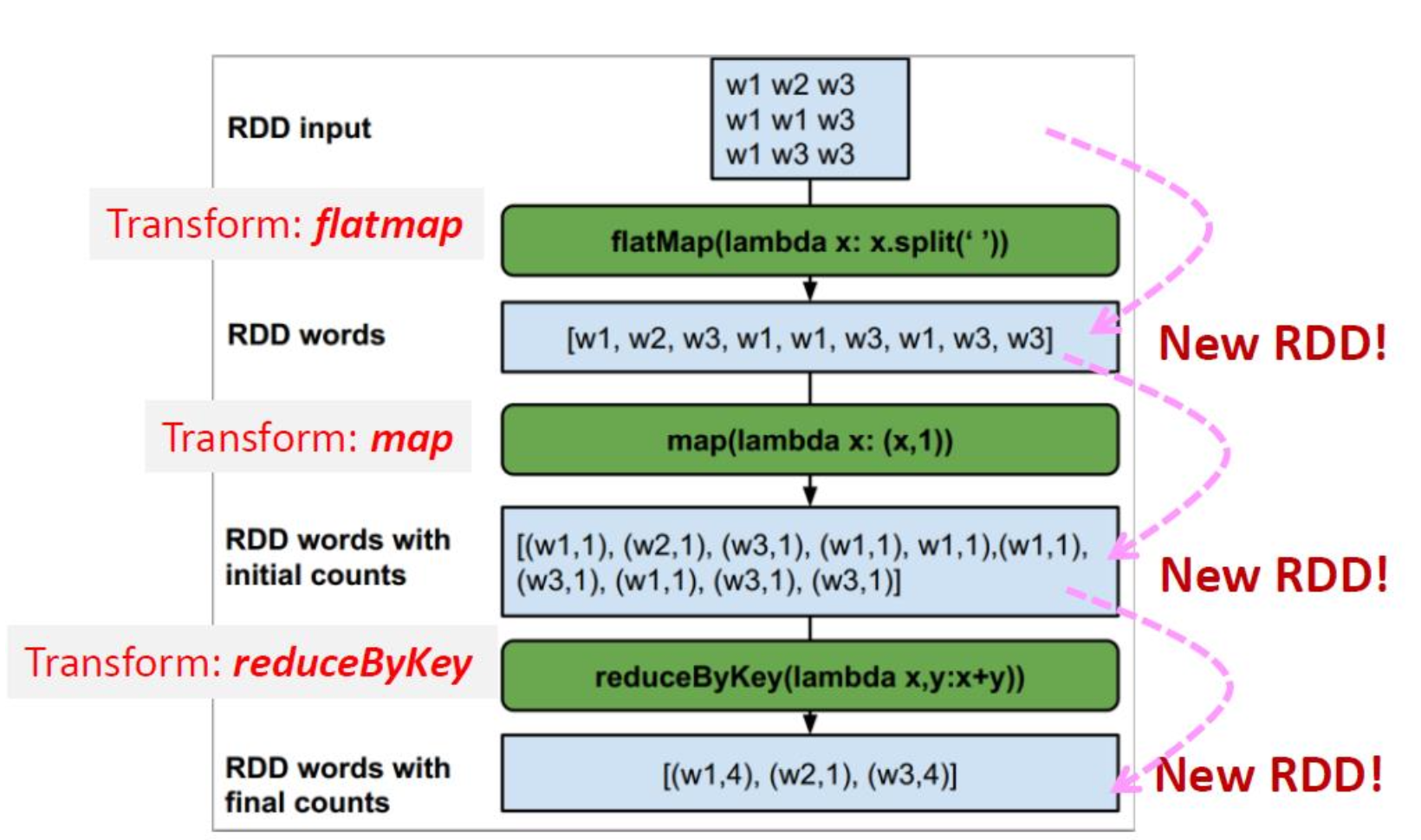
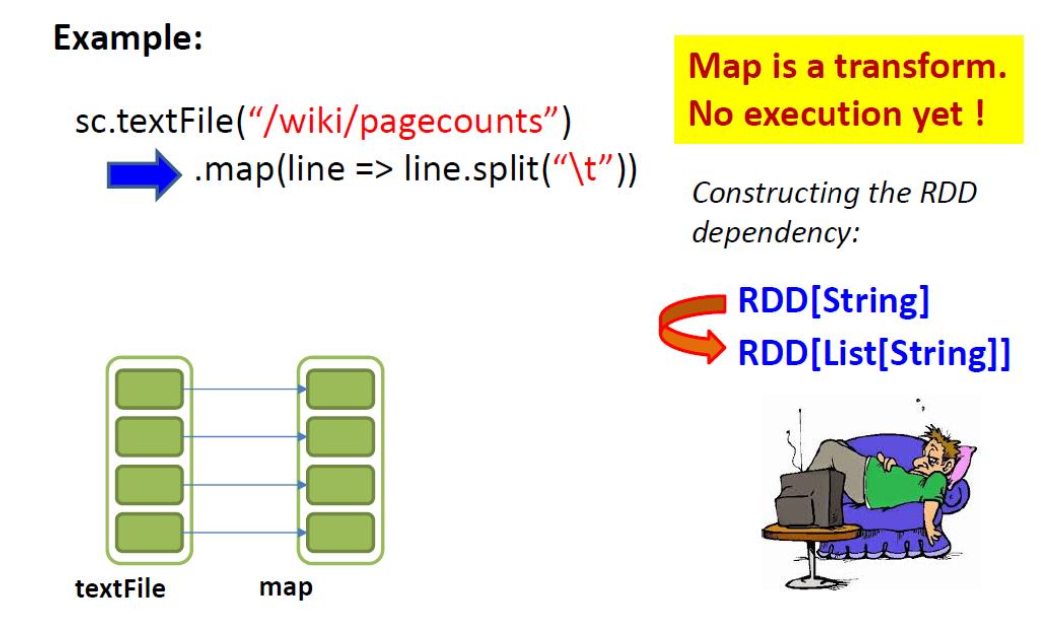
Example: “Transformation returns you a new RDD”
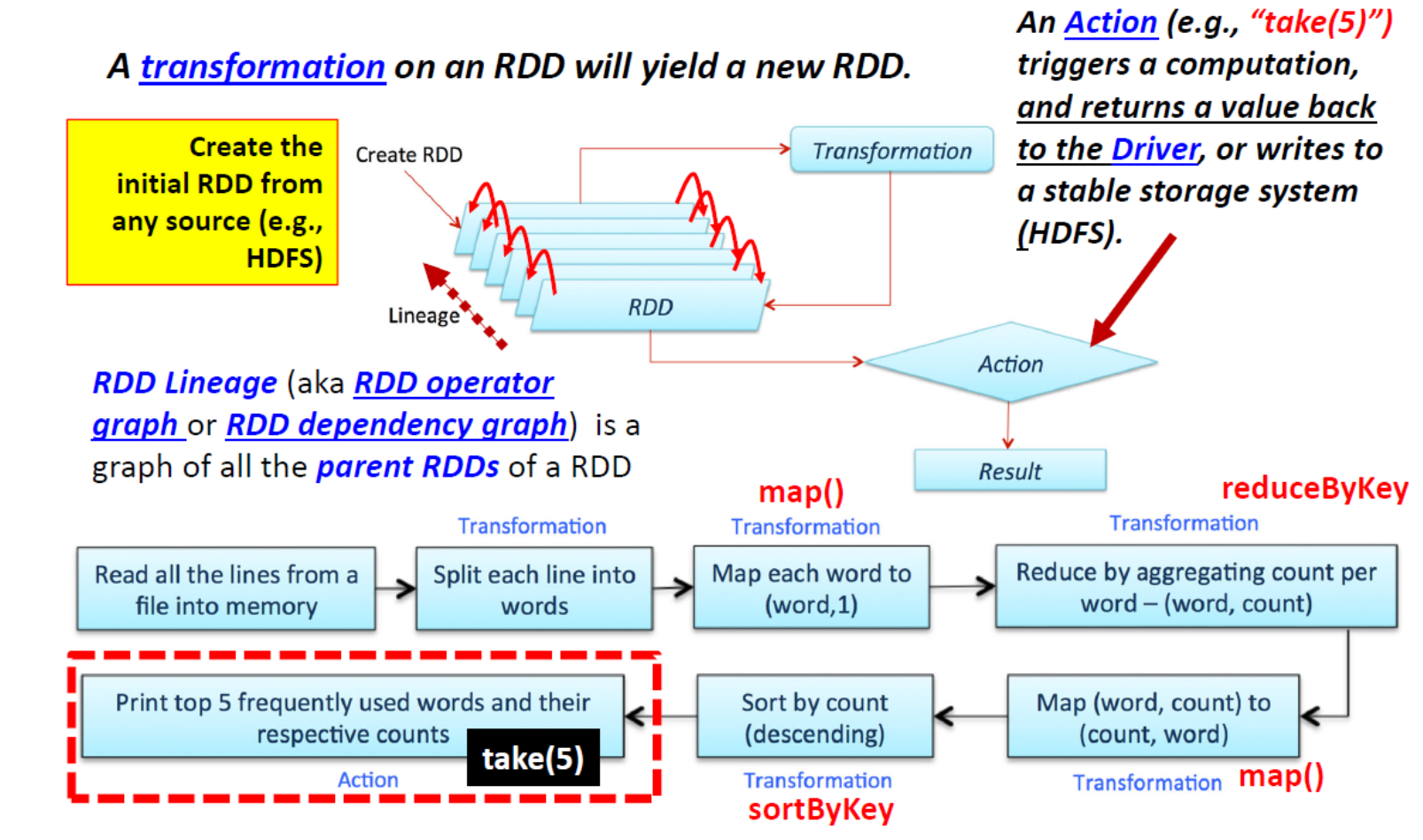
RDD Creation
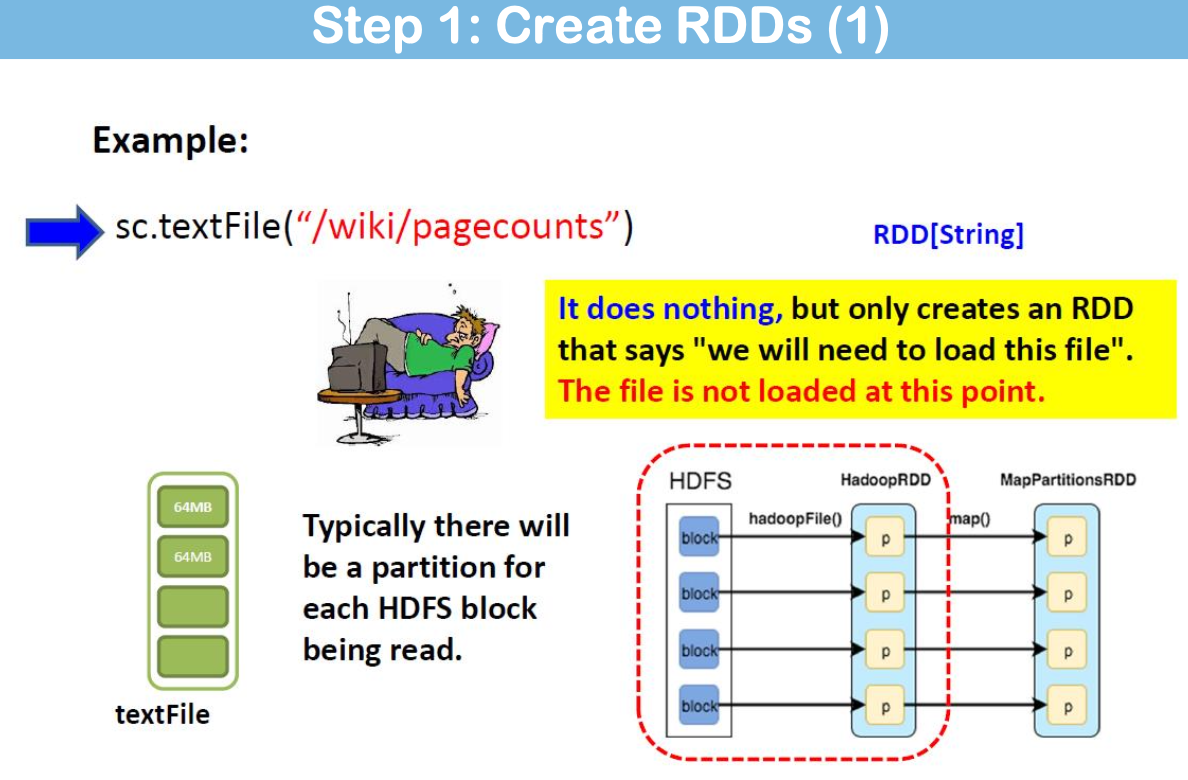
Spark 支持文本文件、序列文件和其他任何 Hadoop 输入格式。
默认情况下,Spark 会为 HDFS 中的每个文件块创建一个分区(例如,默认为 64MB/128MB)。

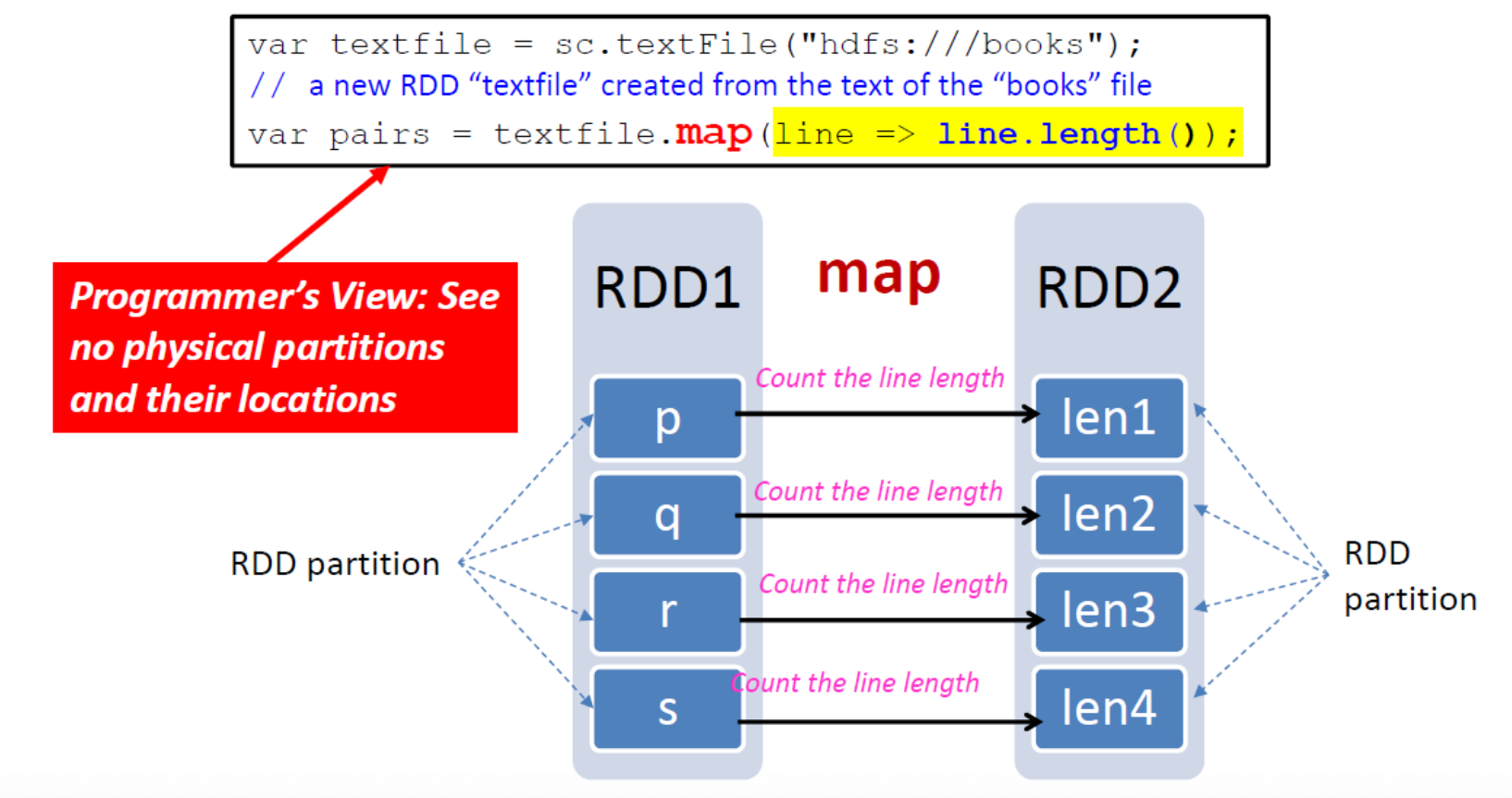
map(func)
在每条记录上执行一个函数(类似于 Hadoop 中的 Map)
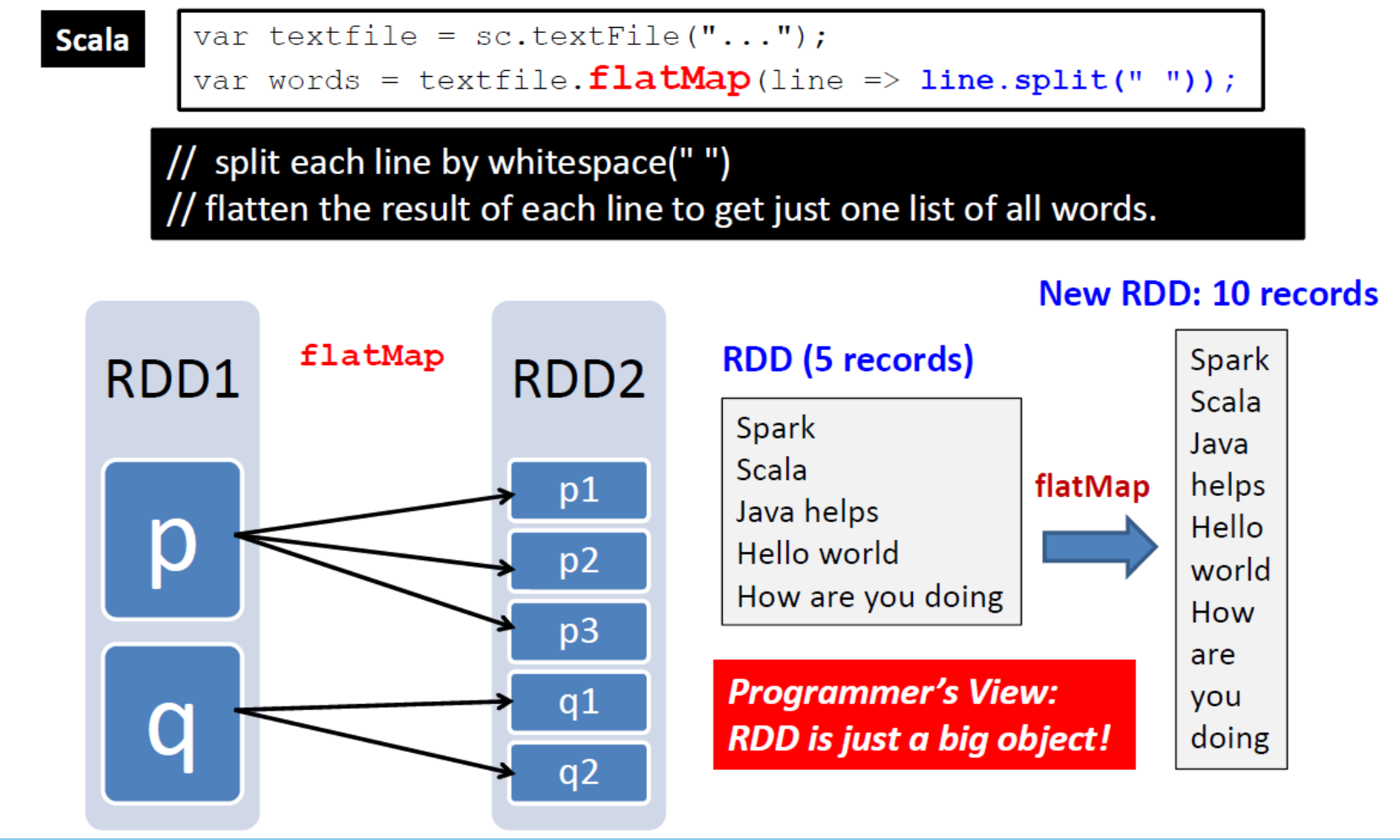
flatMap(func)
Examples Transformation
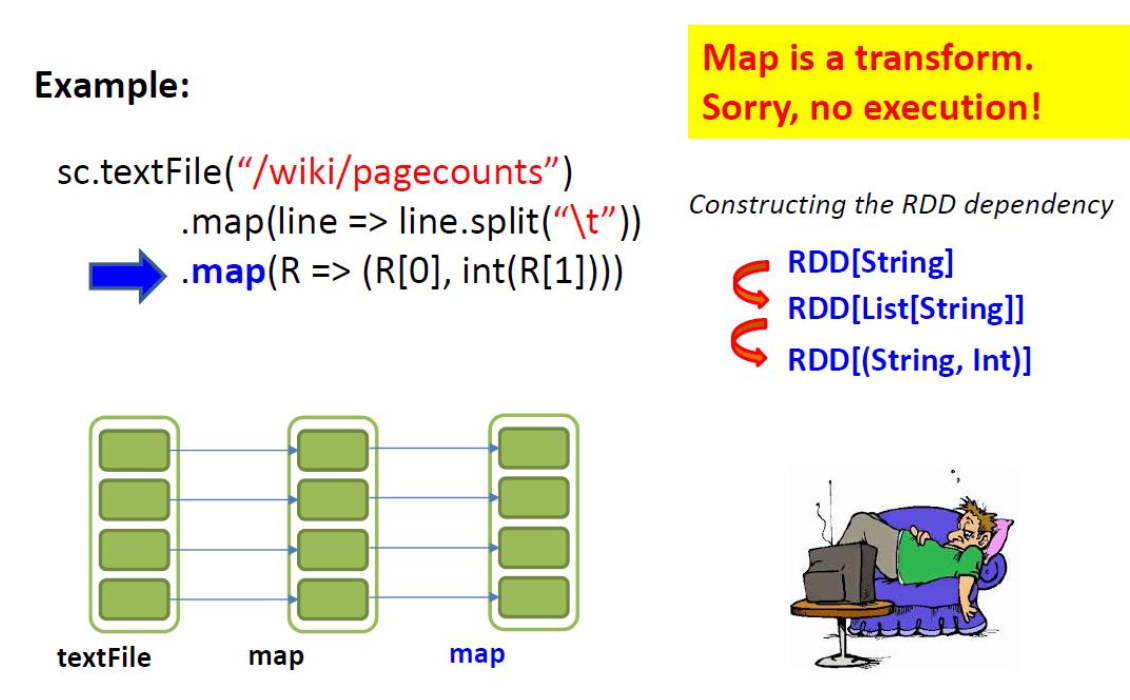
- map(func):返回一个新的分布式数据集,该数据集是通过函数 func 传递源的每个元素而形成的。
- filter(function):返回一个新的数据集,该数据集是通过选择源中函数返回 true 的那些元素而形成的。
- flatMap(func):与 map 类似,但每个输入项可以映射到 0 个或多个输出项。
- union(otherDataset):返回一个新数据集,其中包含源数据集和参数
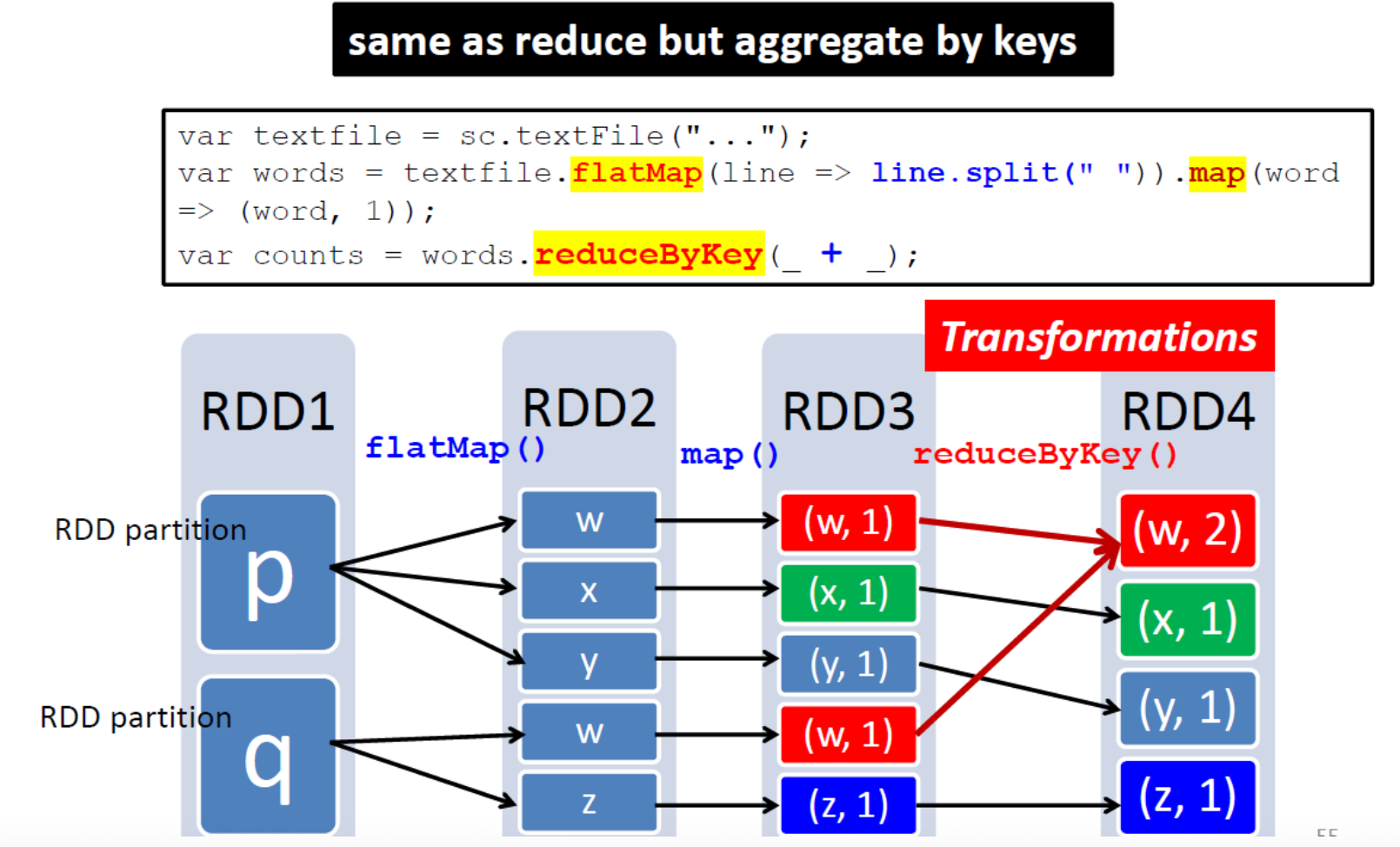
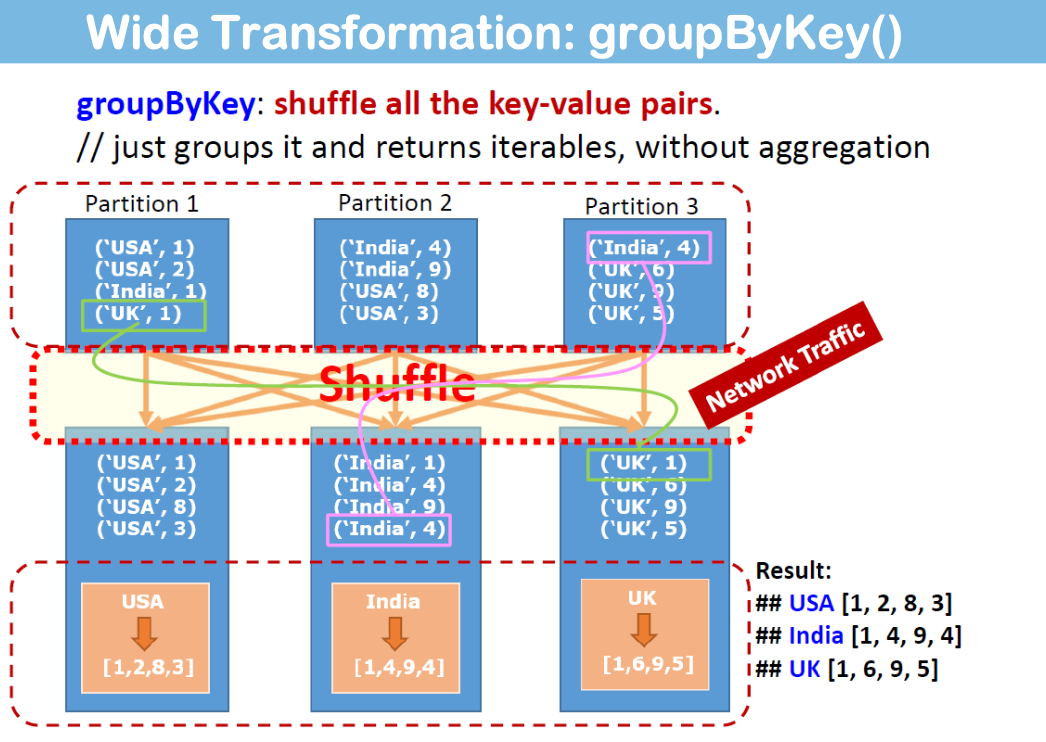
- groupByKey([numTasks]):当在(K,V)对数据集上调用时,返回一个(K,Iterable
<V>)对数据集。 - join (otherDataset,[numTasks]):当在 (K,V) 和 (K,W) 类型的数据集上调用时,返回一个 (K,
(V,W)) 成对的数据集,其中包含每个键的所有元素对。
reduce(func)
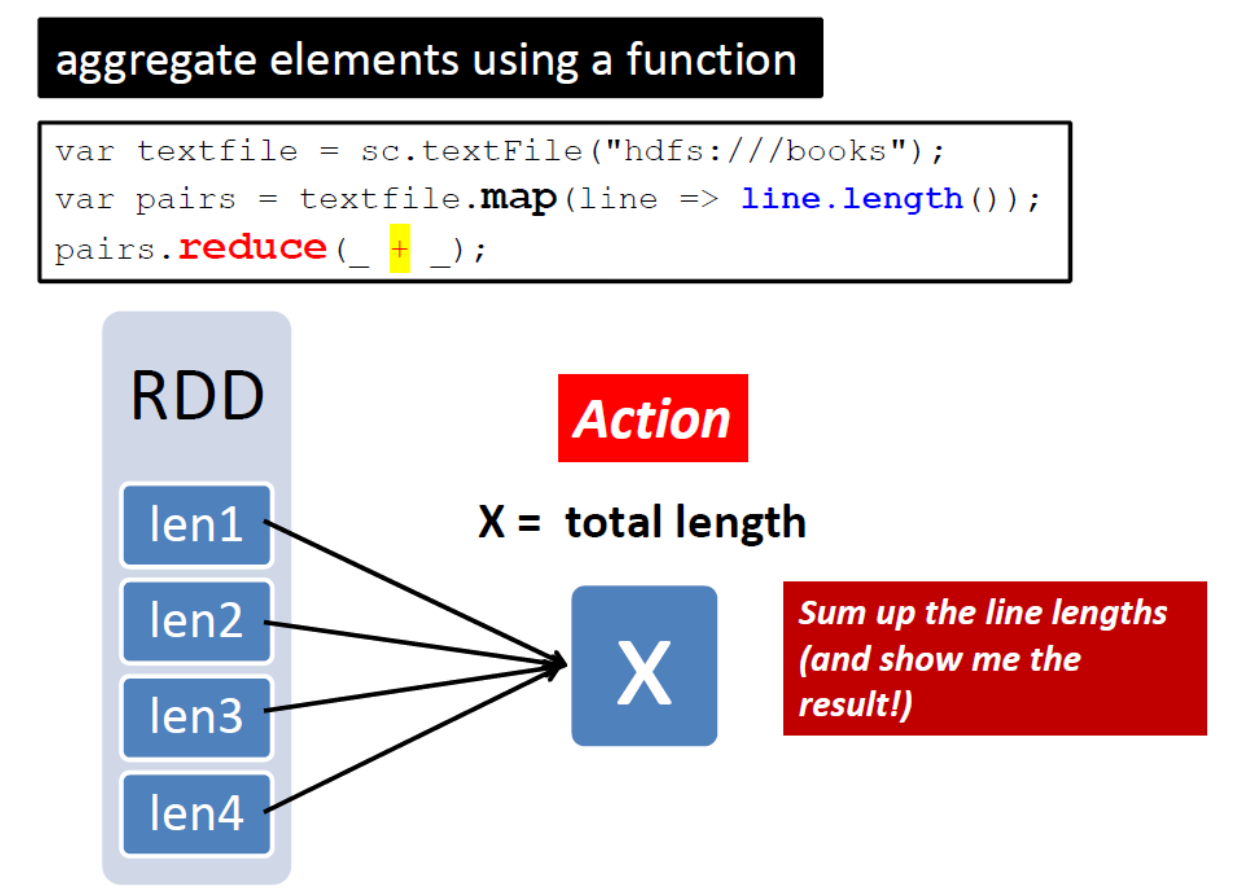
Examples of Actions
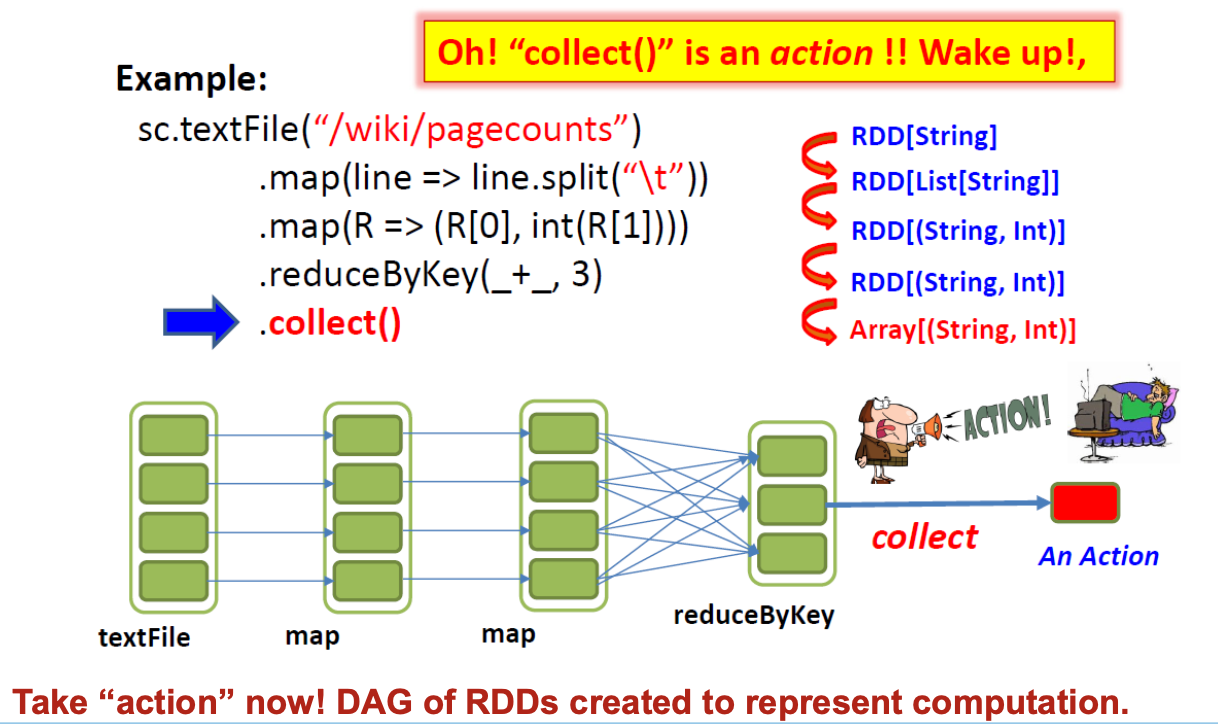
collect()
collect():以数组形式向驱动程序返回数据集的所有元素。
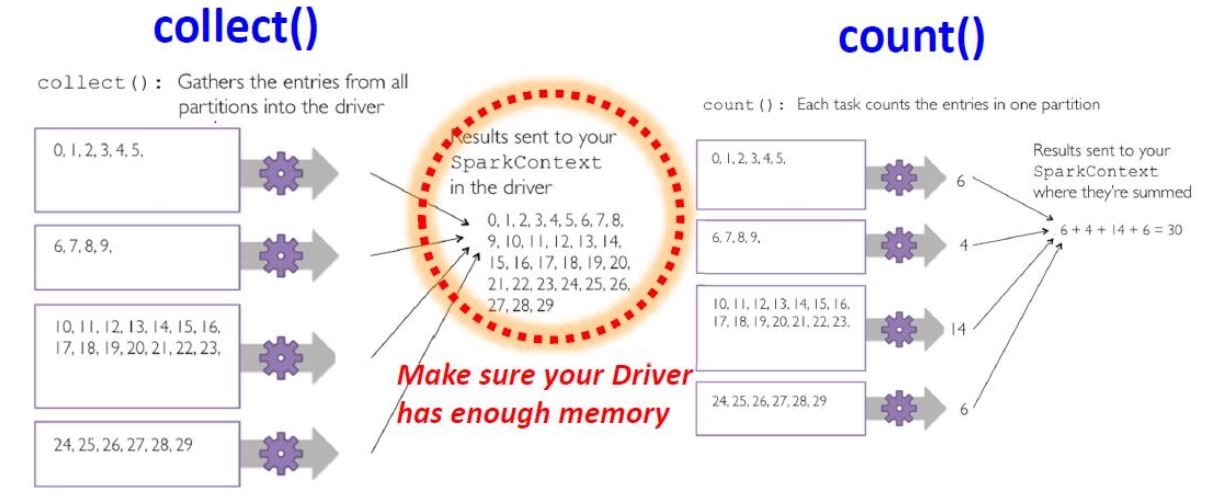

Others

Transformations
- Narrow Transformation:
- all the elements that are required to compute the records in single partition live in the single partition of parent RDD > No shuffling!
- Wide Transformation:
- all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD > Shuffle Needed
E.g., {aggregate/group/sort/ reduce} ByKey,intersect,join?, repartition,…
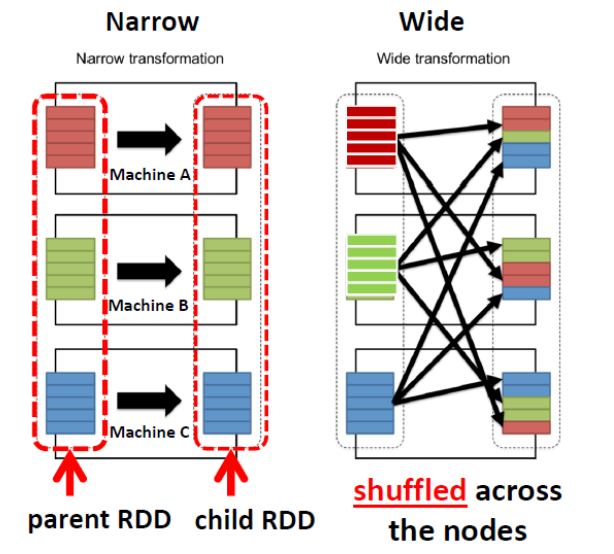
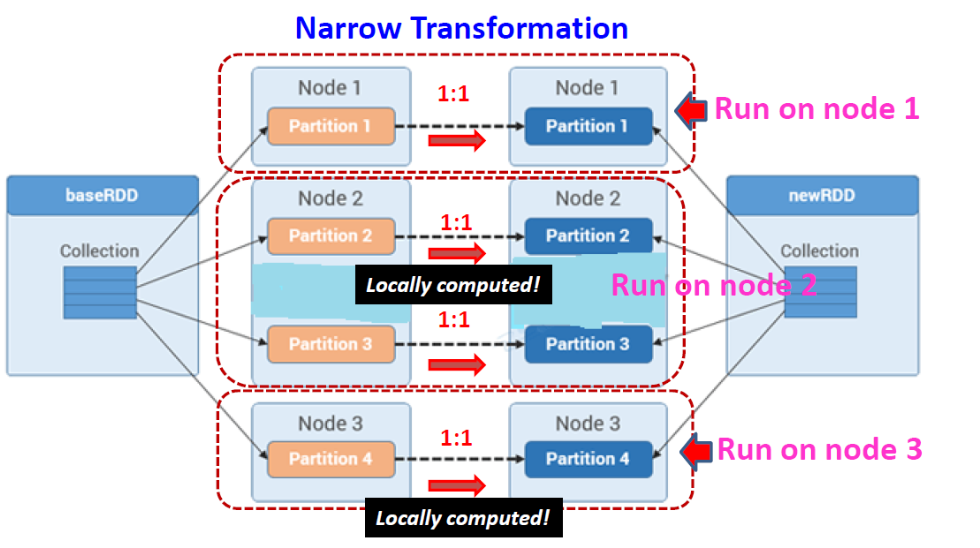
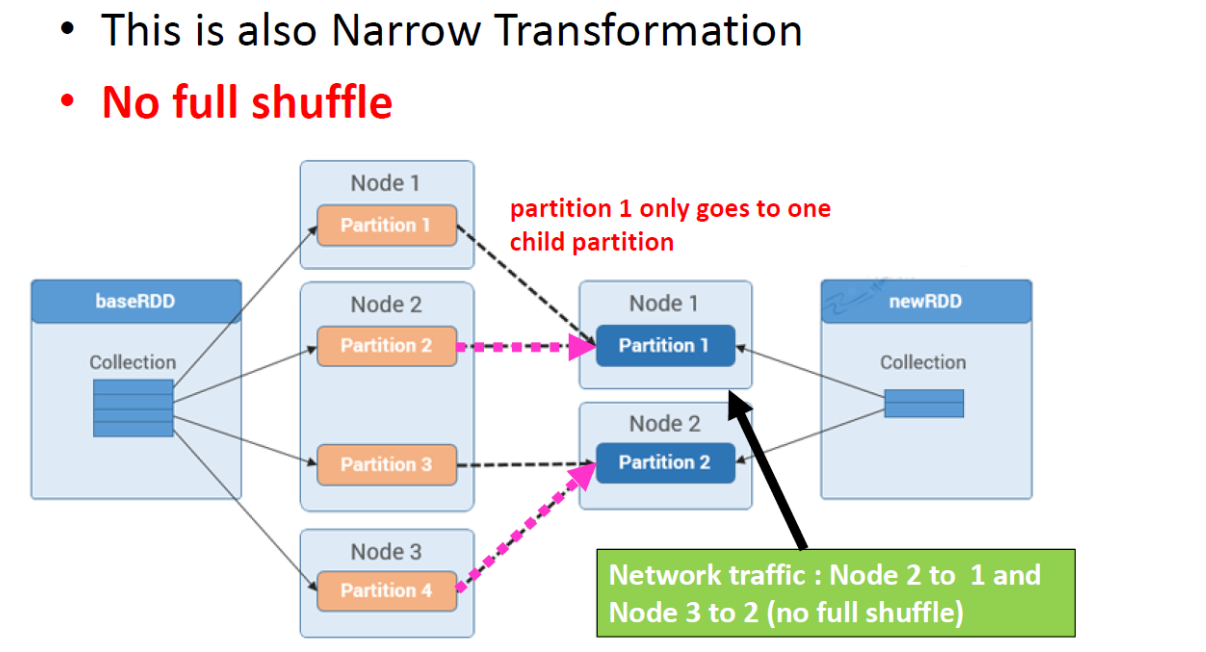
Narrow Transformation
父RDD的每个分区用于生成子RDD的一个分区。
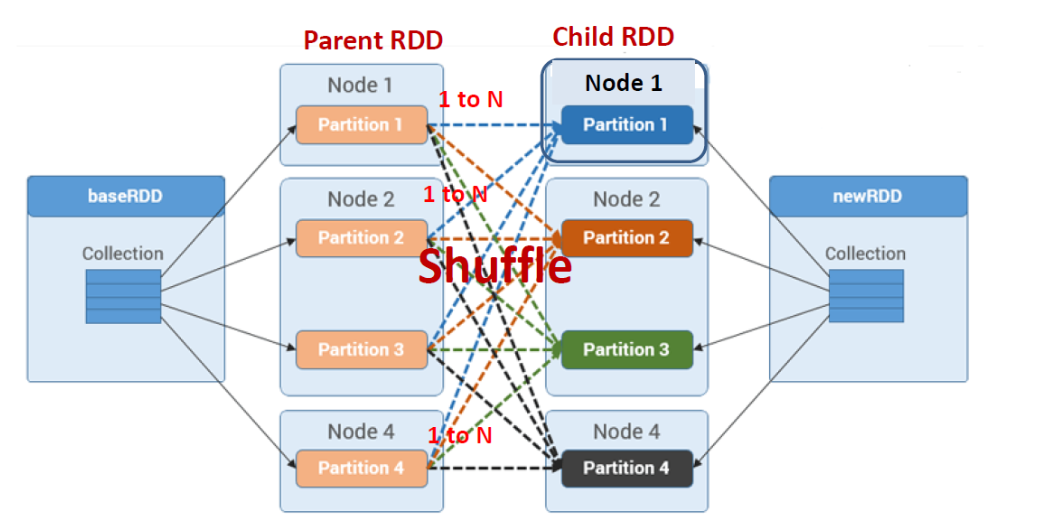
Wide Transformation
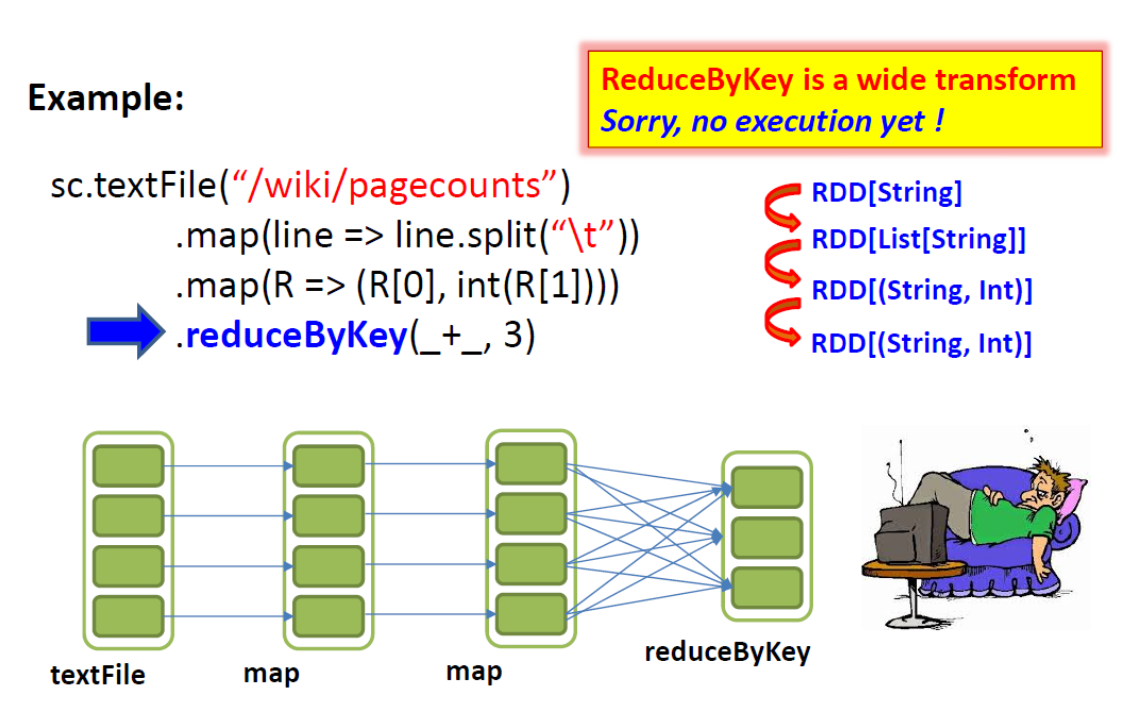
将单个父 RDD 分区中的记录分散(洗牌)到多个子 RDD 分区中(例如,groupByKey、reduceByKey)。
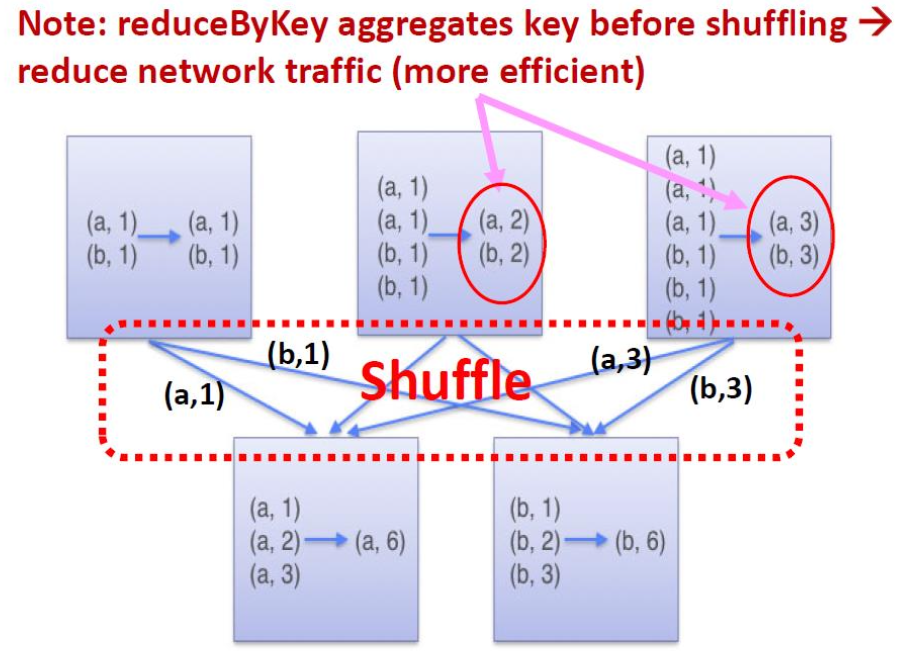
注意:reduceByKey 在 shuffle 之前聚合 key 减少网络流量(更高效)
通过获取源 RDD 的所有不同元素返回 RDD--需要跨分区洗牌。
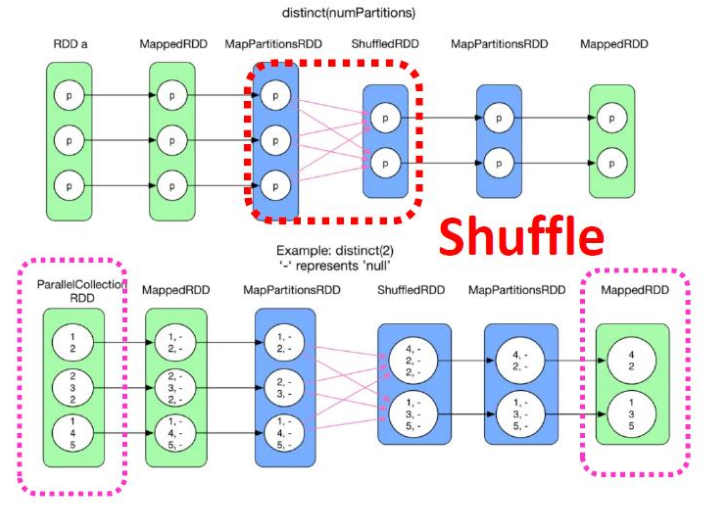
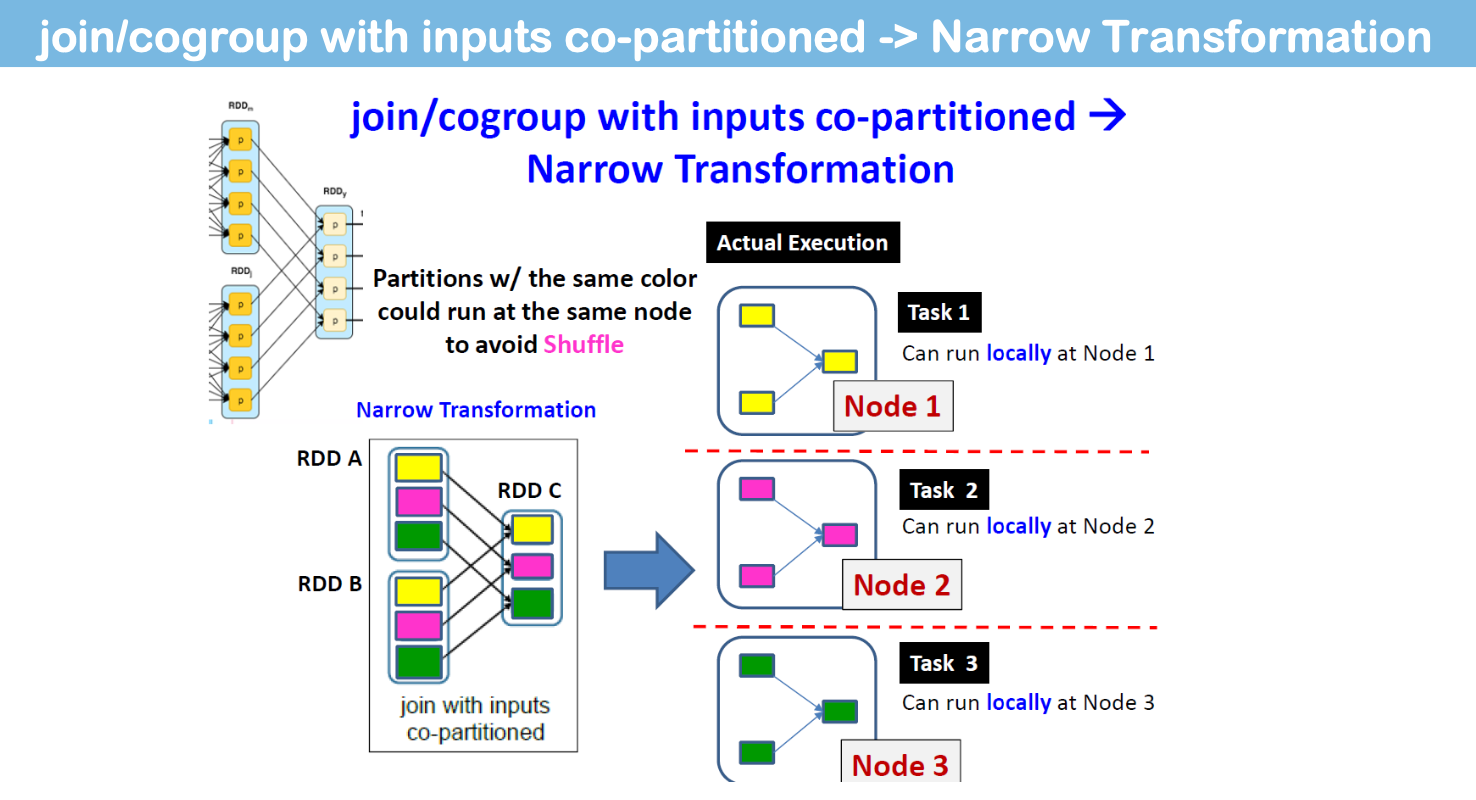
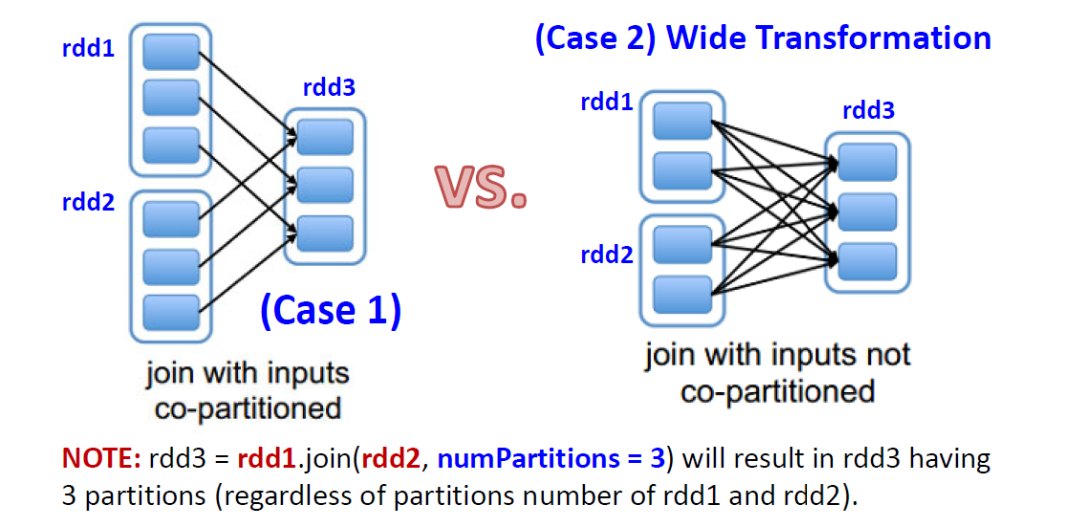
Special Note on Join()
“共同分区”:rdd1和rdd2 使用相同的分区器(HashPartitioner)并且也具有相同数量的分区 -> 不需要shuffle
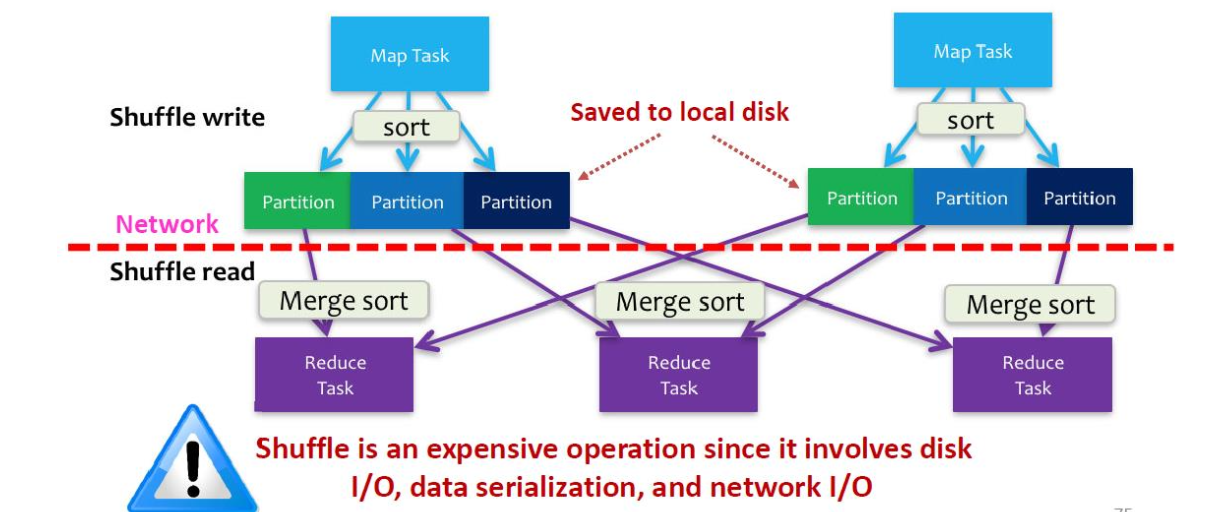
Shuffle
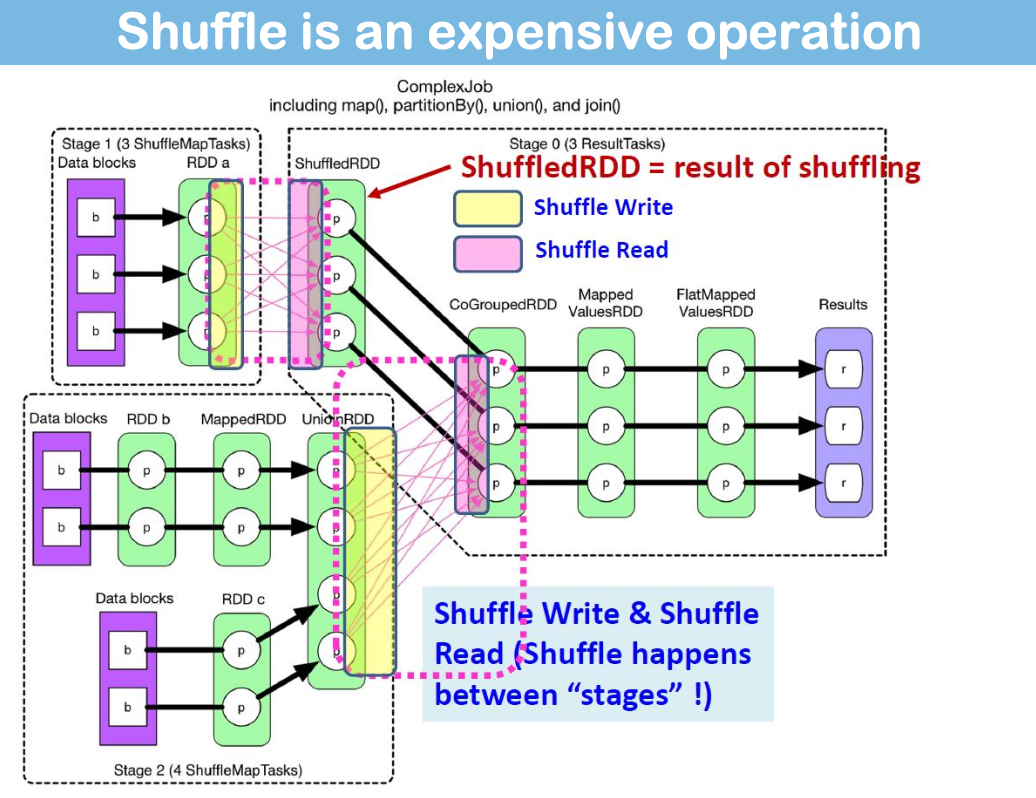
Shuffle is an expensive operation
(Shuffle Write Shuffle Read)
基本上Spark的工作原理与Hadoop相同——执行映射端排序并写入本地磁盘(shuffleWrite)。接下来阶段的任务通过网络获取分区(shuffleRead)。
RDD Partitions
默认情况下,每个 HDFS 分区都会创建一个分区,大小为 64MB/128MB;或您正在读取的文件数。
Performance sensitive

- 分区太少 -> 无法利用集群中所有可用的核心。
- 分区太多 -> 管理许多小任务的开销太大。
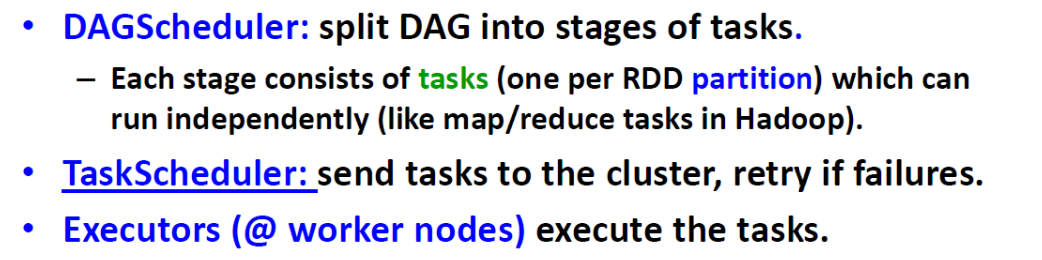
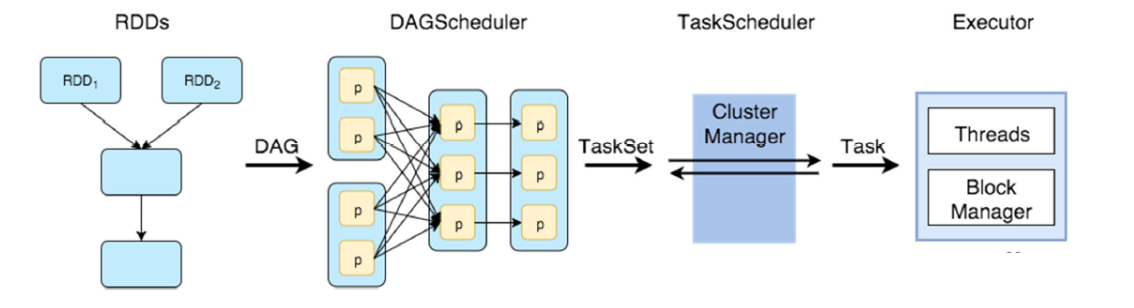
Spark Execution Flow
"All transformations in Spark are lazy": Spark 在执行第一个 "操作"(如 reduce()or collect())之前不会计算任何内容,此时它会递归计算所有 RDDs

用户应用程序创建 RDDs、转换 RDDs 并运行操作,从而形成一个由操作符组成的 DAG(有向无环图)。
详情
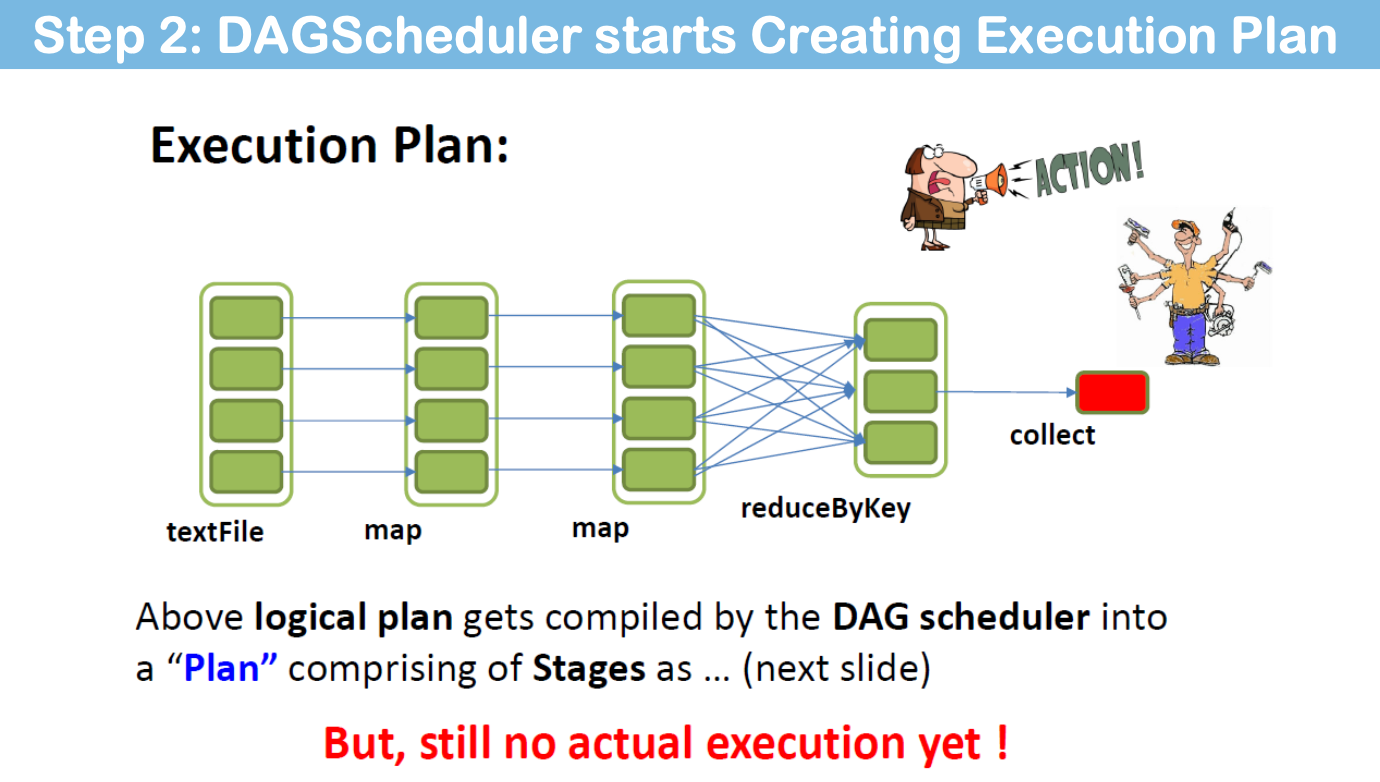
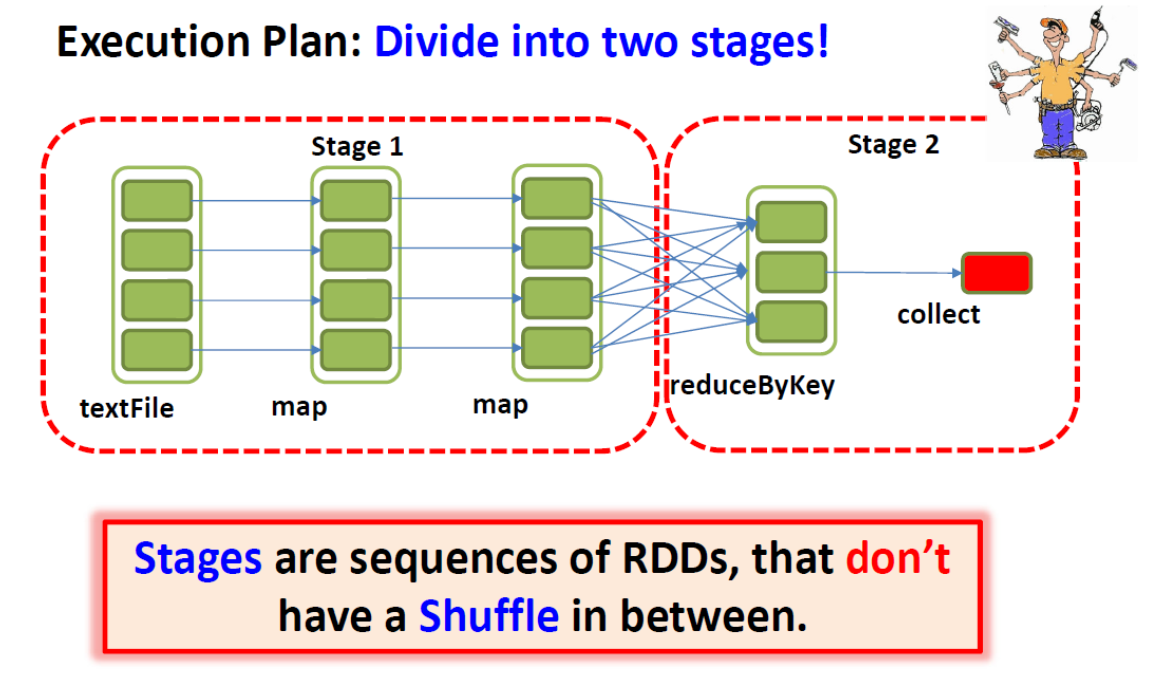
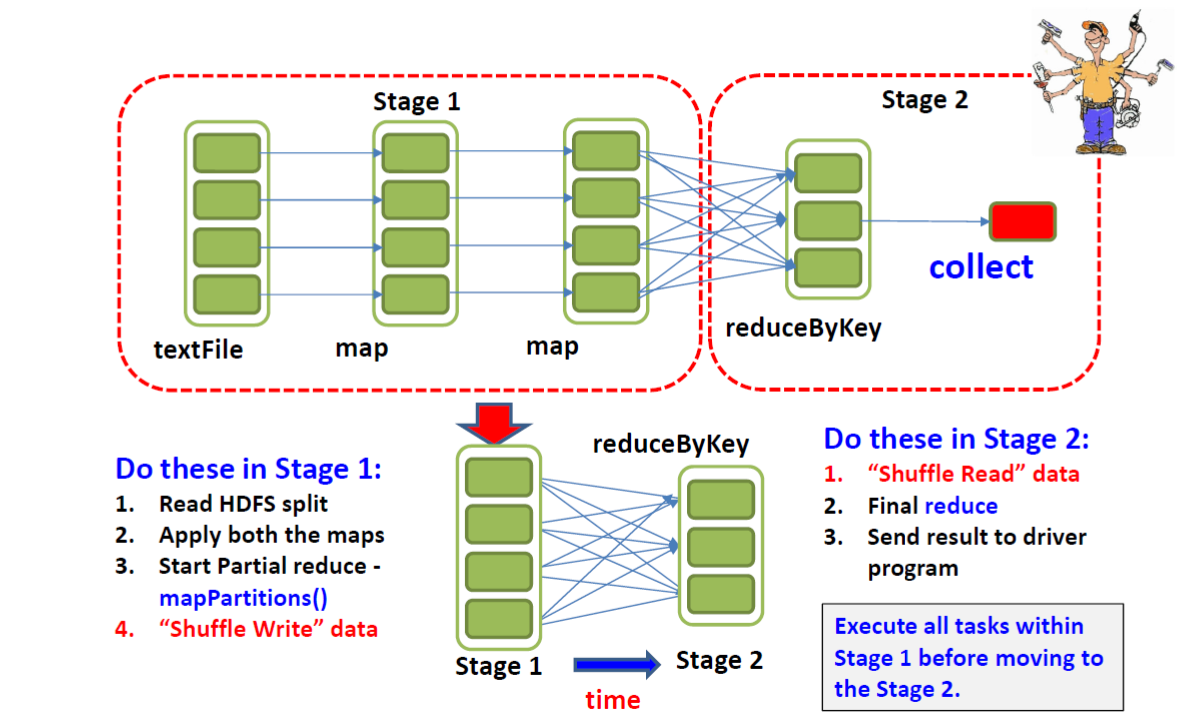
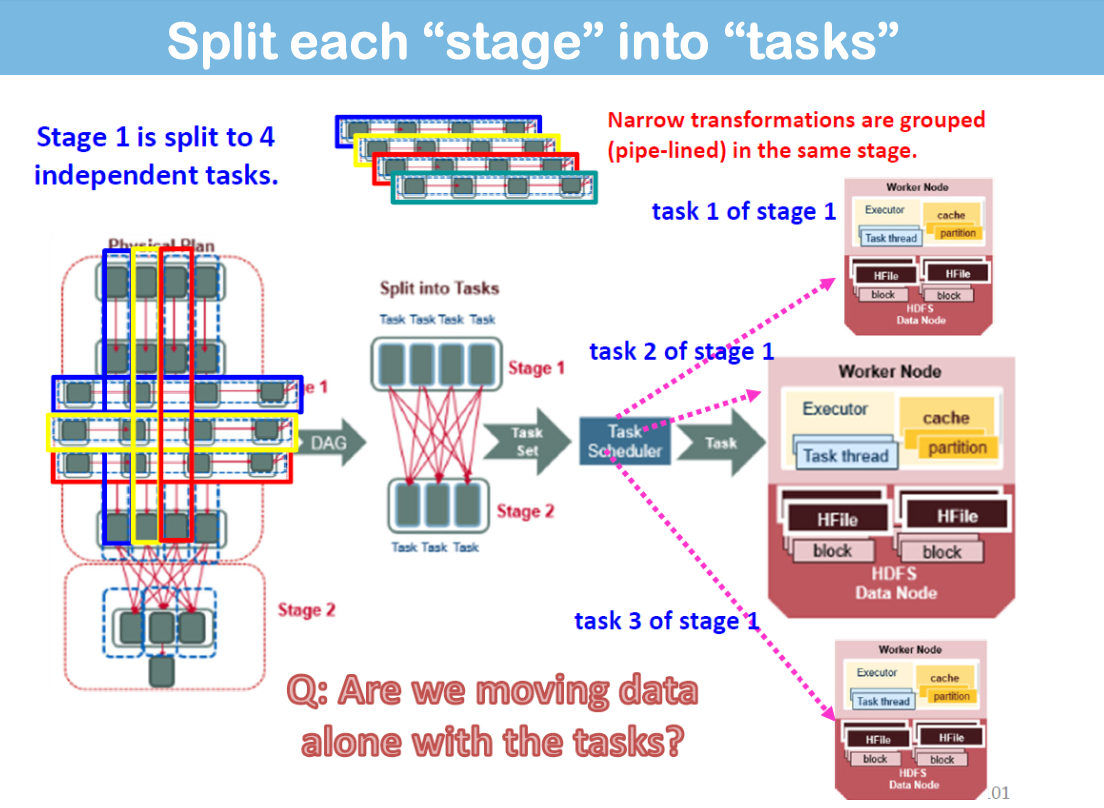
Schedule and Execute “stage by stage” (DAGScheduler)
“Spark is lazy”: Advantages:
- Opportunities of optimization
- 在有机会查看整个 DAG 之后,再做出优化决策(执行计划)。
- Narrow transformations 可以捆绑在一起,以实现内存计算(流水线)。
- Saves computation and increases speed
- 只计算 RDD,生成 Action 想要的值。
- 基于数据位置的动态任务分配(在缓存了 RDD 分区的节点上运行任务)
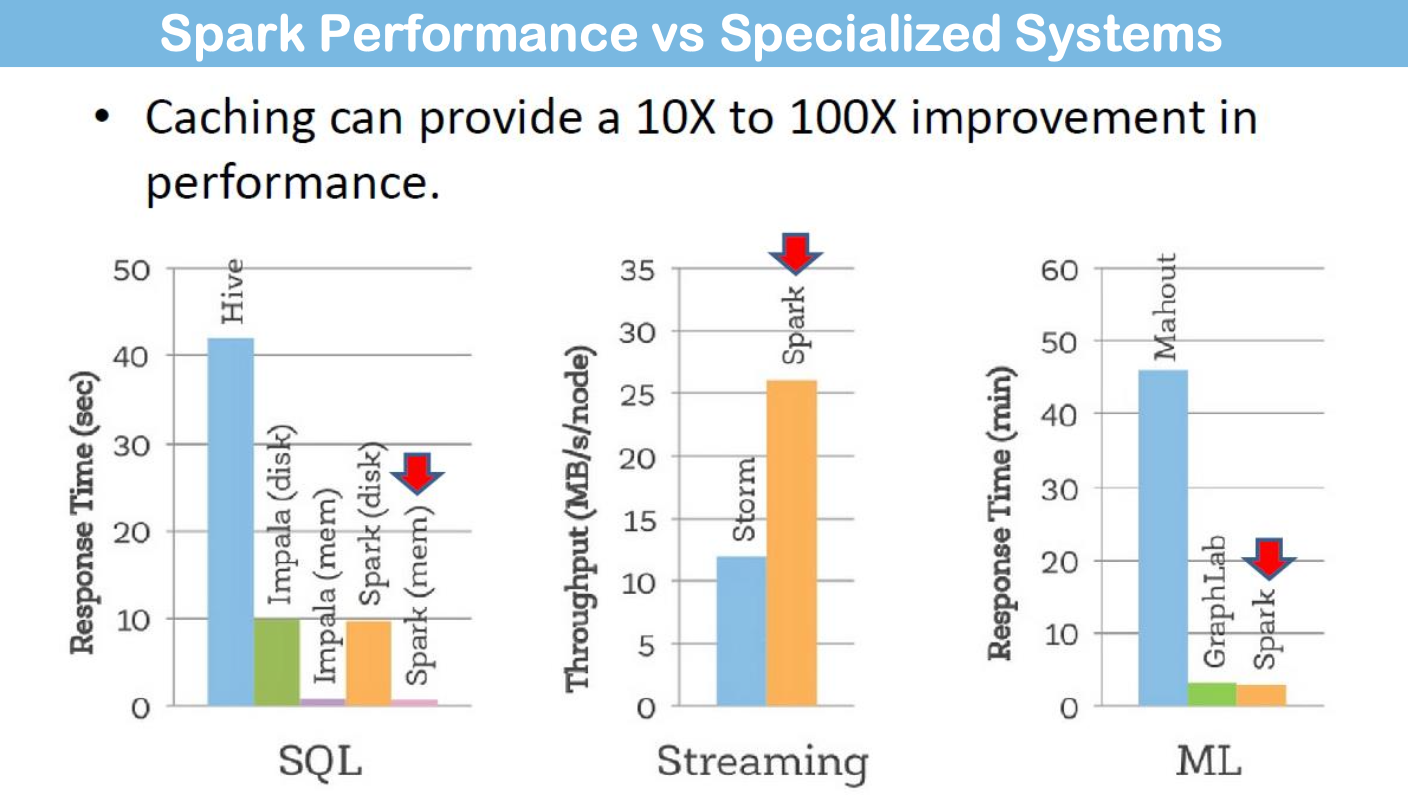
RDD Cache
In-memory Computing: RDD Cache
RDD 可缓存在 RAM 中,以实现快速访问重用
How to cache an RDD?
- 只需在驱动程序中执行 rdd.cache(),其中 rdd 是用户可访问的 RDD
- In Spark shell:scala>RDDName.cache()
- Executor 将 RDD 分区作为 Java 对象缓存在 Java 堆中。
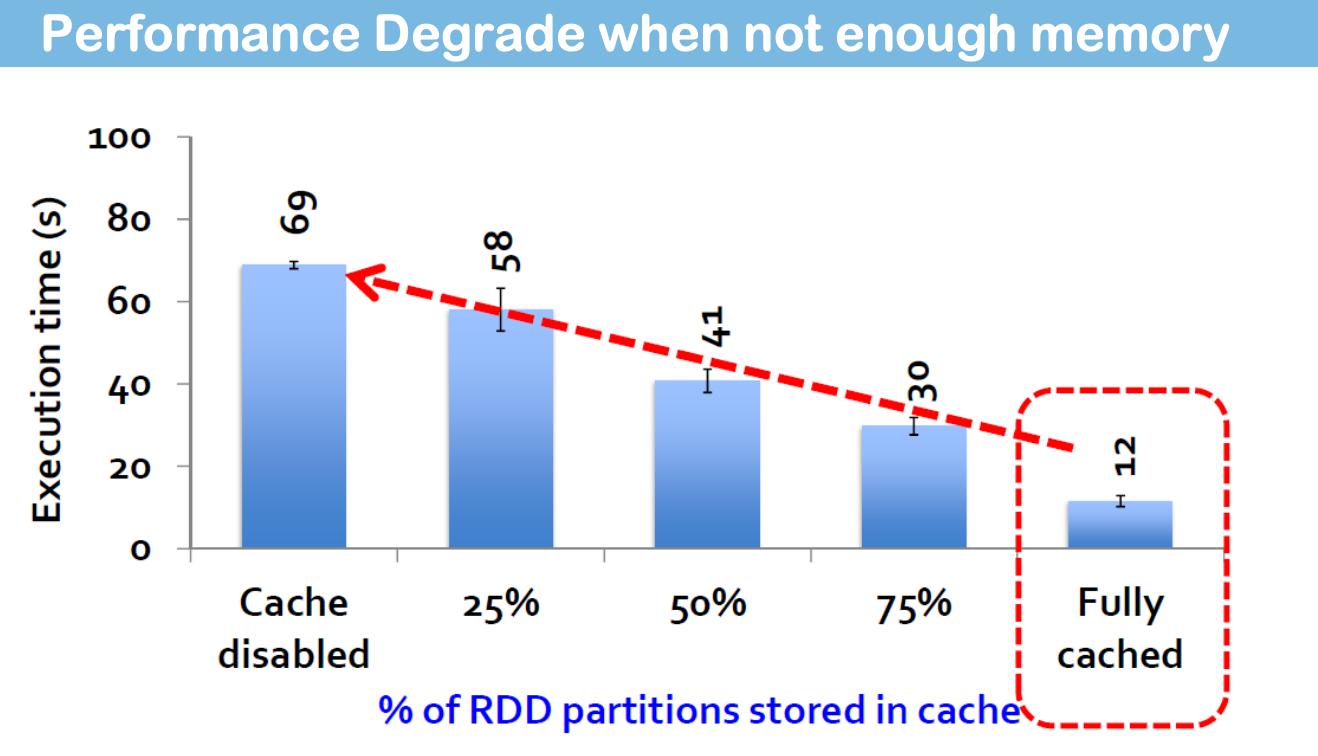
请记住,执行器内存是有限的。Spark 会以最近最少使用(LRU)的方式自动从执行器内存中驱逐 RDD 分区。
缓存 RDD 时,它的分区会被加载到持有它的执行器的内存中。
- 可以增加 "缓存的分数",因为重新分区后,分区的大小会变小,更容易装入内存。
- Advice:"Avoid shuffle"unless needed!
- 注意:虽然缓存提高了速度,但 Spark 会在每次洗牌时将分区写入磁盘(洗牌写入)(类似于 MapReduce)。
“缓存只是一个提示,而不是保证”。
- Spark 监控每个节点上的缓存使用情况,并以 LRU 方式丢弃旧数据分区。
- 内存中无法容纳的缓存分区会在需要时溢出到磁盘或在运行中重新计算,这取决于 RDD 的存储级别(在第二部分中解释)。
如果 RDD 没有缓存,一旦被消耗(例如,在操作之后),就会被垃圾回收,需要重新计算!
When to Use cache()?
- Use an RDD many times
- Performing multiple actions on the same RDD
- For long chains of (or very expensive) transformations
Limitation of caching:
- 缓存减少了执行引擎本身的可用内存(第 4 讲第 Il 部分)
- 缓存的分区可能会在实际重新使用之前被逐出