Virtualization Technologies
Virtualization Technologies

Virtualization Technologies are the CORE of Cloud Computing
Why Cloud is Attractive?
- Dynamic (on-demand) resource scaling
- Pricing: Pay by use
Enabling Technique: Virtualization
What is Virtualization
Virtualization is the pooling and abstraction「汇集和抽象」 of resources in a way that masks「隐藏」 the physical nature and boundaries of those resources for the resource users (e.g.,virtual CPUs,virtual network,virtual storage)
Virtualization at Different Levels
- Instruction Set Architecture(ISA) Level「指令集架构(ISA)级」: Bochs/Crusoe/Qemu/BIRD/Dynamo
- Hardware Abstraction Layer(HAL)Level「硬件抽象层(HAL)级别」:VMWare/Xen (2003)/KVM(2007)/VirtualBox/Hyper-V
- Operating System Level:OpenVZ LXC(Linux Container)/Docker(2013)/Imctfy(2013)/Solaris Containers/LXD(2015)
- Library (user-level API)Level:Wine/WABl/LXRun/Visual MainWin
- Application (Programming Language) Level:JVM/.NET CLI/Parrot
Hardware Abstraction Level (HAL)
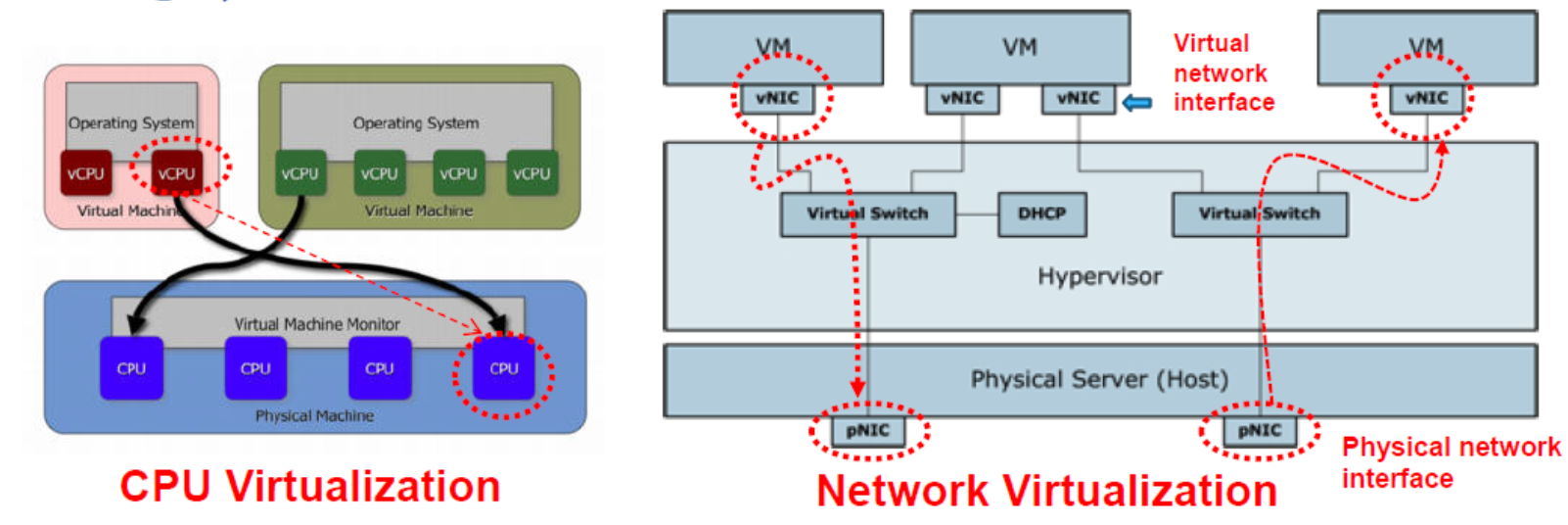
Allow the sharing of the underlying physical machine resources「底层物理机资源」 between different virtual machines,each running its own operating system.
The software layer providing the virtualization is called a virtual machine monitor (VMM) or hypervisor.
A virtualization platform that allows multiple operating systems to run on one machine at the same time.


Three Main Tasks Done by the Hypervisor
- CPU Virtualization
- Memory Virtualization
- Device and I/O Virtualization
CPU Virtualization
- Full virtualization using binary translation
- Without guest OS modifications
- Using Binary Translation(e.g.,Qemu)
- OS assisted virtualization or para-virtualization
- Guest OS经过修改,使其能够更高效地在虚拟机管理程序上运行。Xen使用的主要模型。
- Hardware-assisted virtualization
- 使用硬件支持虚拟化:AMD AMD-V、Intel VT。
- Linux KVM 使用的主要模型(但 I/O 虚拟化仍使用 Qemu),
- 现在也被Xen(HVM)也支持。
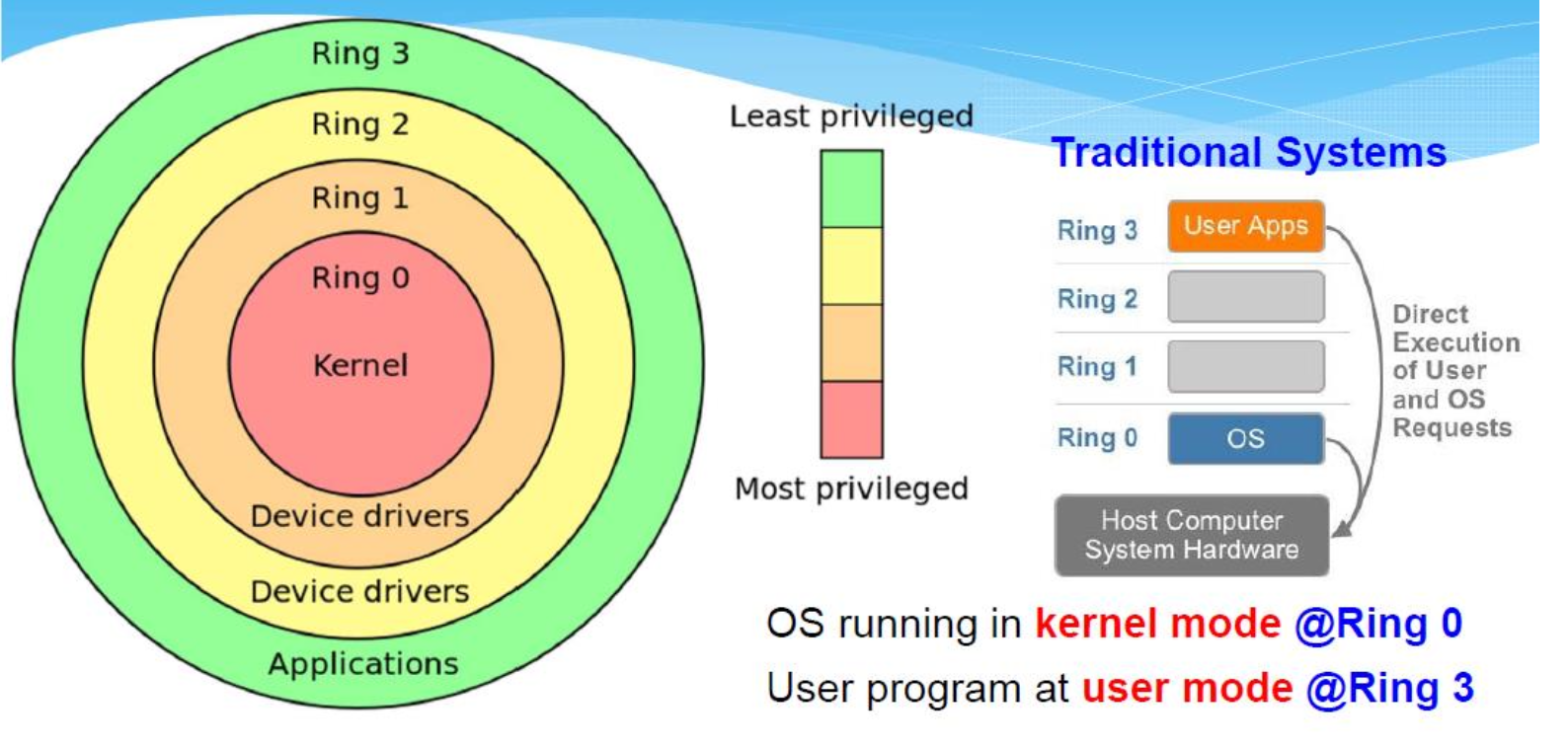
x86架构支持四种特权级别—通常编号为0~3。 Ring 0是权限最高的级别,与CPU、内存等物理硬件交互最直接。
在每个瞬间,CPU 都可能处于以下状态之一:
- Running a user process(@Ring 3,your code)
- Running a system call (@Ring 0,kernel code)
- Running an interrupt handler(@Ring o,kernel code)
- Running a kernel thread (@Ring 0,kernel code)

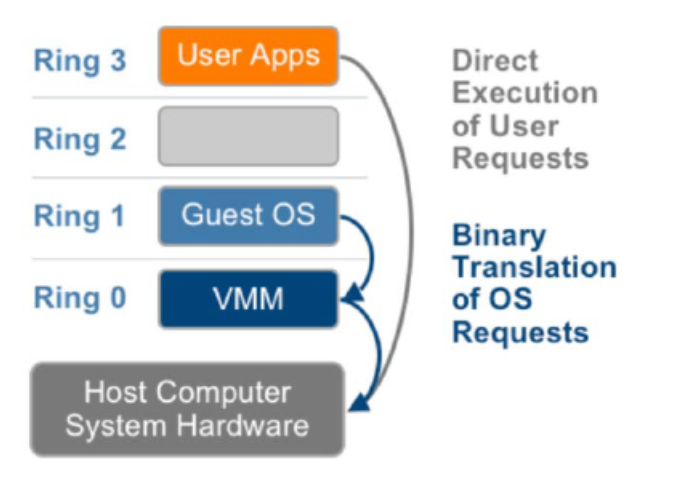
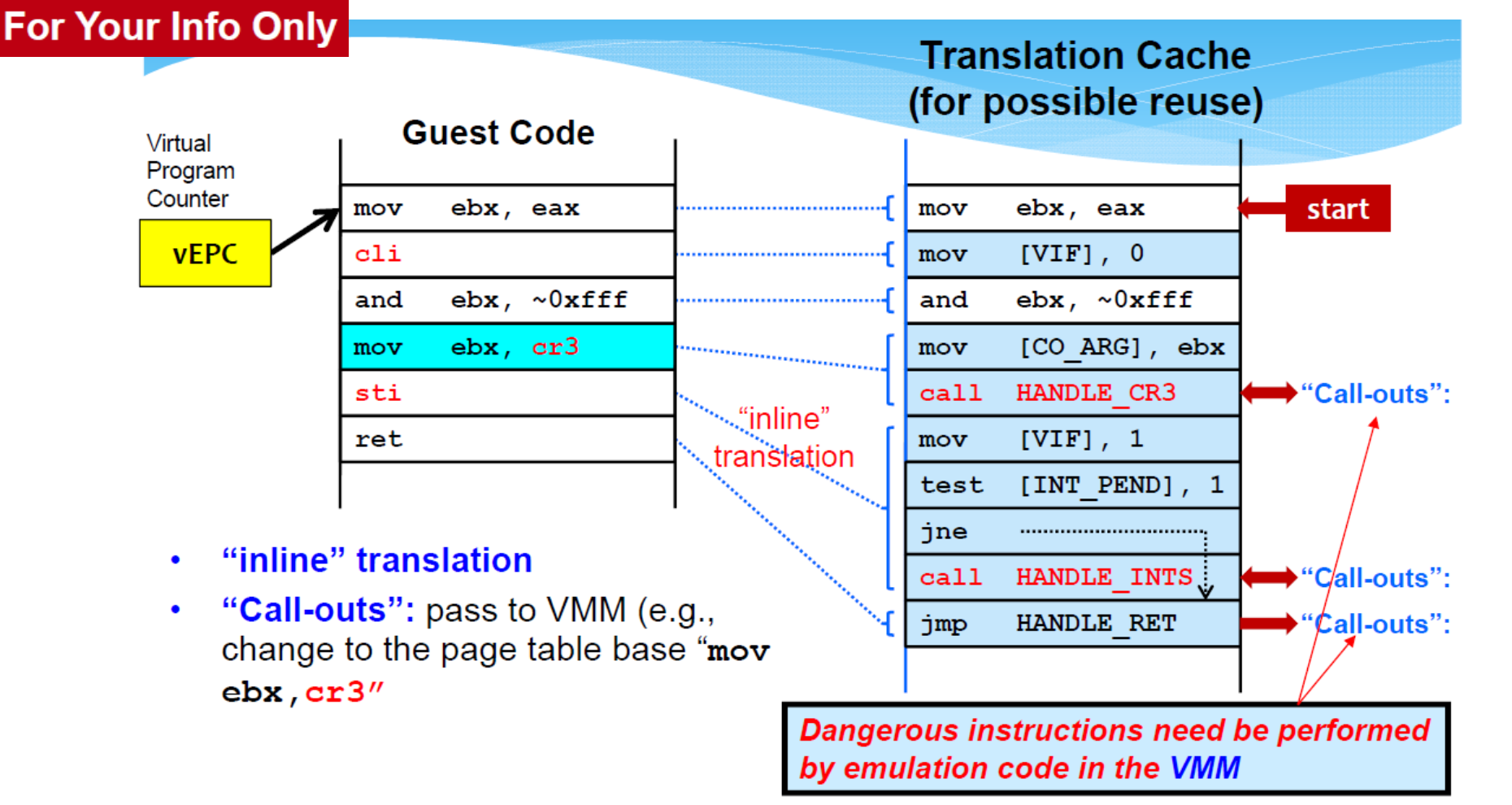
Full Virtualization using Binary Translation
Translates kernel code to replace non-virtualizable instructions with new sequences of instructions that have the intended effect on the virtual hardware.
「翻译内核代码,用新的指令序列替换不可虚拟化的指令,从而在虚拟硬件上达到预期效果。」
- User level code is directly executed on the processor for high performance virtualization.
- The guest OS is not aware it is being virtualized and requires no modification.
Guest OS runs at Ring 1
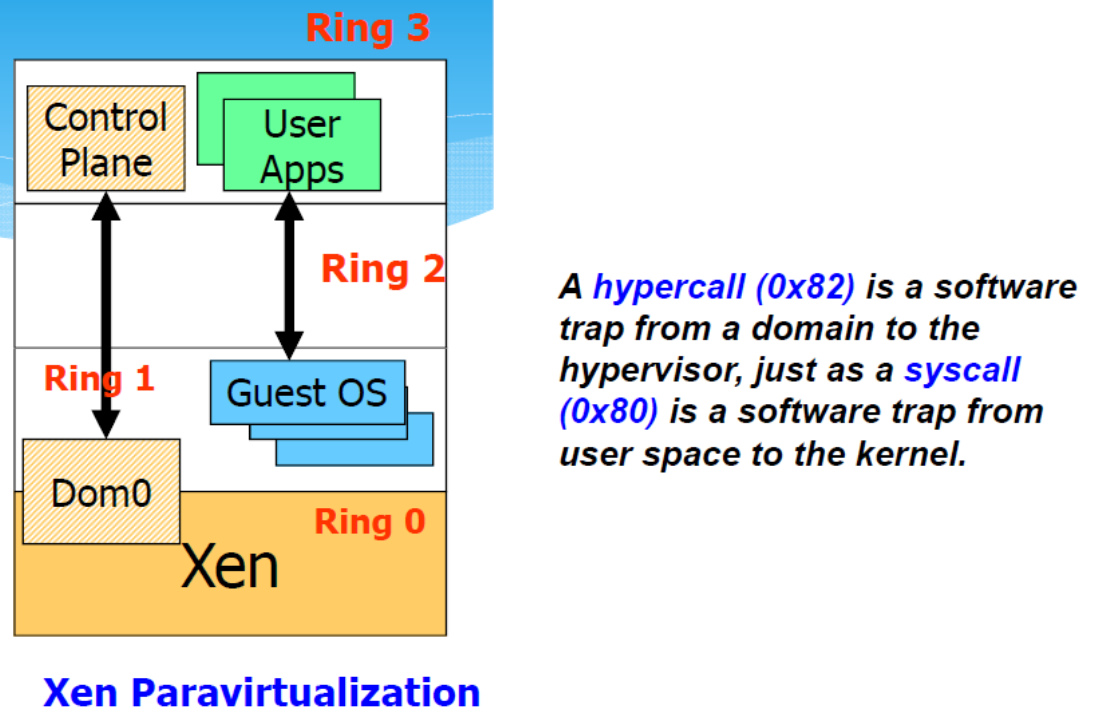
OS-Assisted Virtualization or Para-Virtualization
半虚拟化涉及修改(来宾)操作系统内核,以将不可虚拟化指令替换为直接与虚拟化层管理程序通信的超级调用「hypercalls」。
Trade portability for performance and scalability「以可移植性换取性能和可扩展性。」.
Xen:
- Xen 在Ring 0中运行,修改后的 Guest OS在Ring 1中运行(因此Guest OS仍然受到保护)并且Guest应用程序在Ring 3中未经修改地运行
- Guest OS Modification:
- 将仅在 CPU 的 Ring 0 中运行的任何特权操作「privileged operations」(例如关闭)替换为对虚拟机管理程序的调用(称为超级调用「hypercalls」)
- The hypervisor in turn performs the task on behalf of the guest kernel.
- Leverage OS knowledge of virtualization to provide high-performance VM.
Xen requires modifications to Guest OS's Kernel: Attempt to provide most services directly from the underlying hardware instead of abstracting it.
- Advantages: near-native performance
- 以一次性修改客户操作系统为代价,暴露「exposure」真实硬件,提高性能。
- Disadvantages: Guest OS are limited to open source systems such as Linux.
- Xen 支持的客户操作系统:Linux、NetBSD、FreeBSD、OpenSolaris 和 Novell Netware 操作系统(参见,不支持 Microsoft 操作系统)
Para-virtualization VMMs: Xen、VMware ESX 和 ESXi(自 v3.5)、Microsoft Hyper-V(Windows 2008/2012 Sever)、Oracle VM Server。
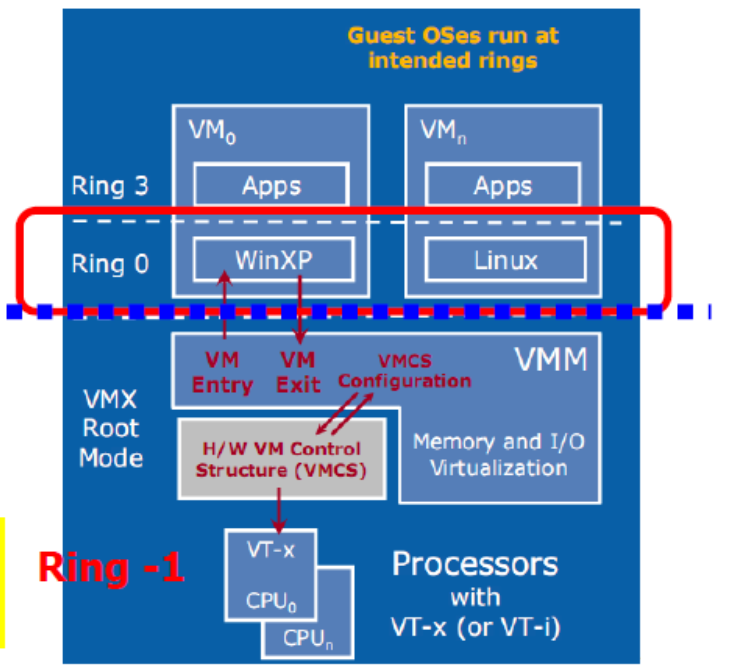
Hardware-Assisted Virtualization
Intel Virtualization Technology (VT-x) and AMD's AMD-V which both target privileged instructions with a new CPU execution mode feature that allows the VMM to run in a new root mode below ring 0 (Ring-1).
Privileged and sensitive calls are set to automatically trap to the hypervisor, removing the need for either binary translation or para-virtualization.
- Xen calls it hardware virtual machine (HVM)
- KVM is designed for hardware-assisted virtualization.
Memory Virtualization
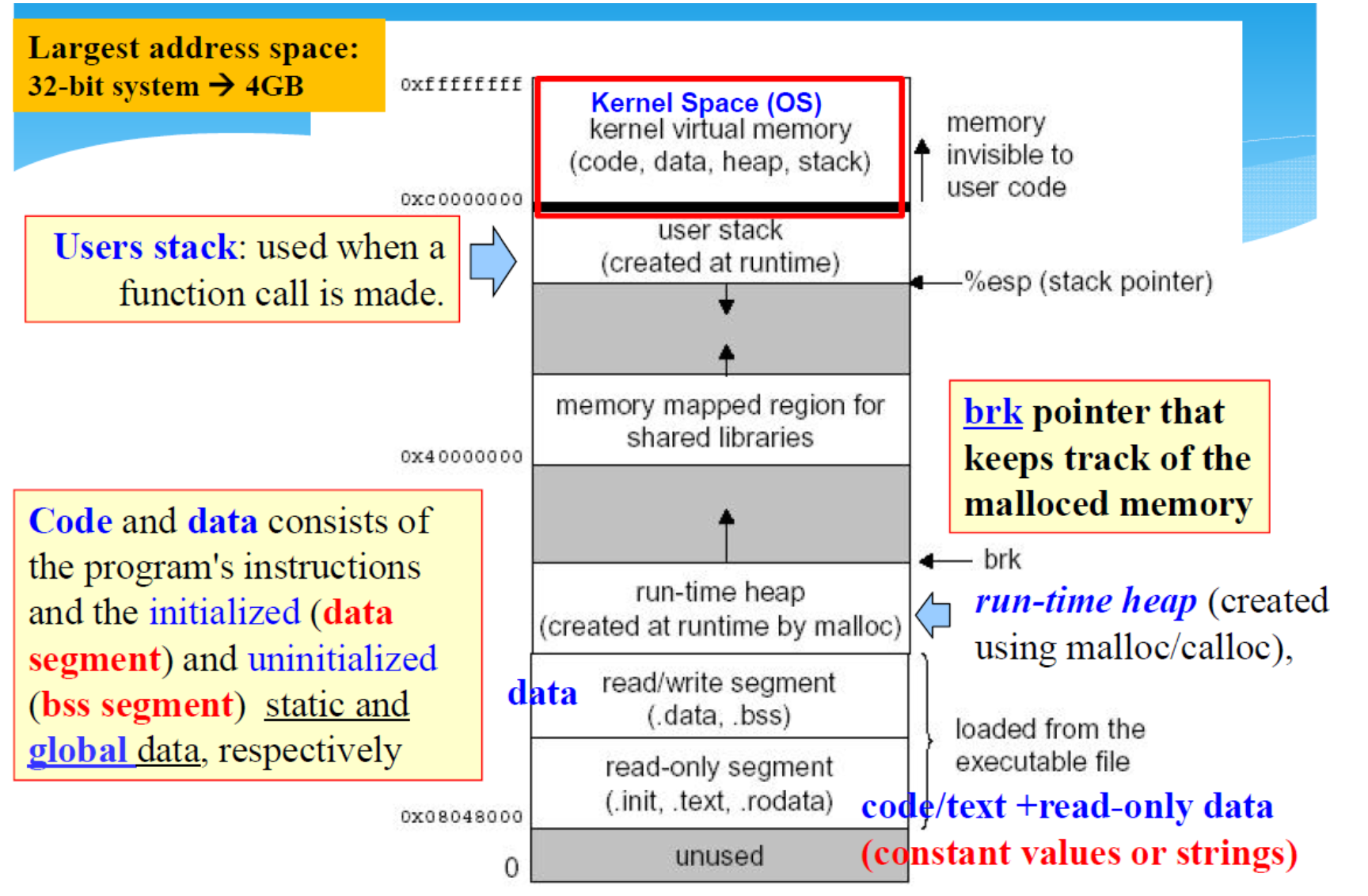
Process Address Space
(32-bit -> 4GB, 64-bit->16 billion GB)
- Code segment:(static) - Stores the code (instructions)of the executable file.Read-only !!
- Data segment:(static) - Static data area (size of the allocation known by compiler, preserved during the lifetime of the program): Array[2000], Matrix[200,200]-array size will not change.
- Heap segment:(dynamic) - Storing data created at runtime,e.g.,by malloc();can be "freed" later.The required size will not be known until run-time.
- Stack segment:(dynamic) - Used to store
- the local variables used in functions
- parameters passed to the functions
- returned values from the function call
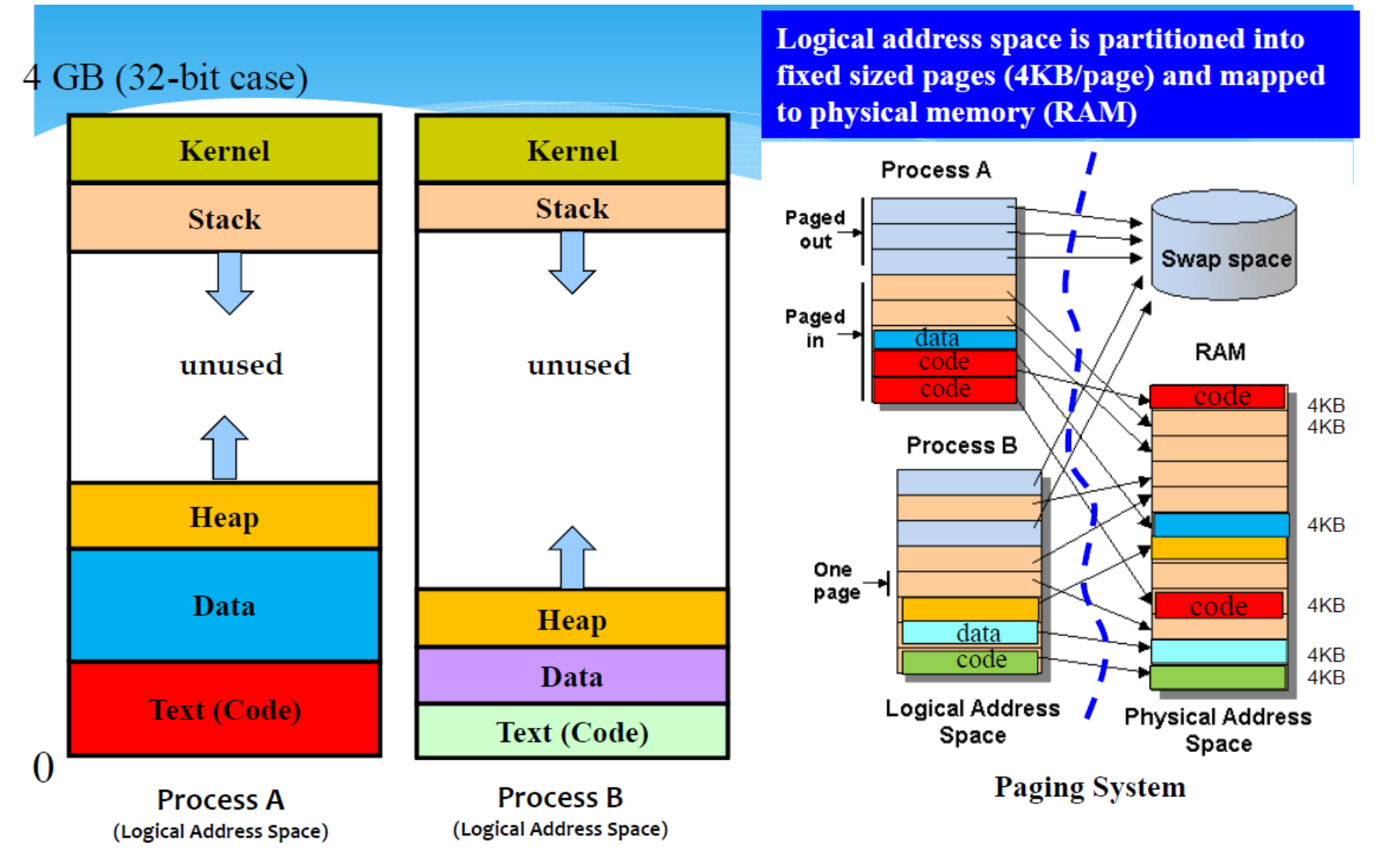
Memory Layout of a Linux Process
Logical vs Physical Address
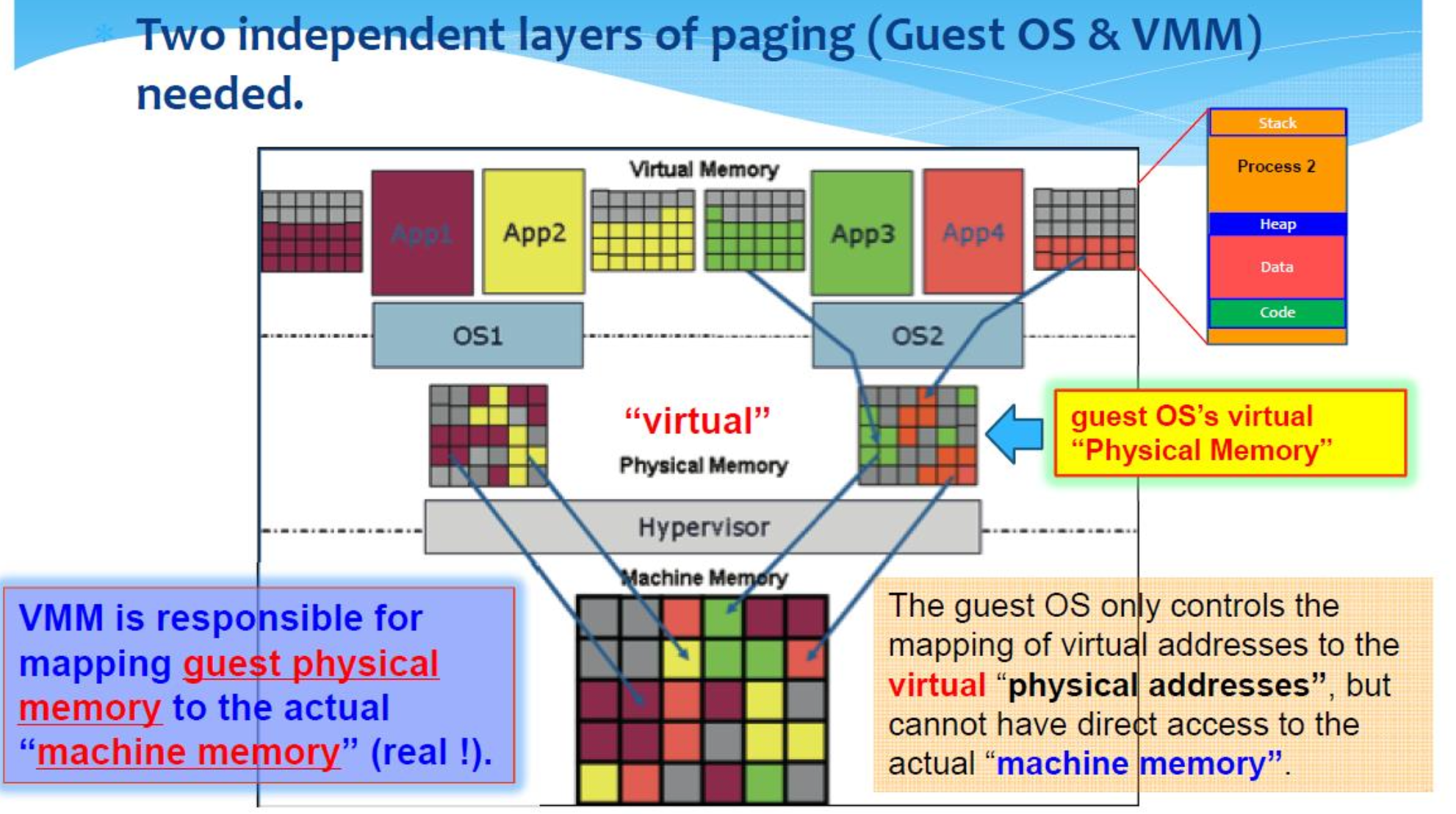
2 Independent Layers of Paging
Two independent layers of paging(Guest OS & VMM) needed.
- 客户操作系统只能控制虚拟地址到虚拟 "物理地址 "的映射,但不能直接访问实际的 "机器内存"。
- VMM 负责将客户物理内存映射到实际的 "机器内存"(真实内存)
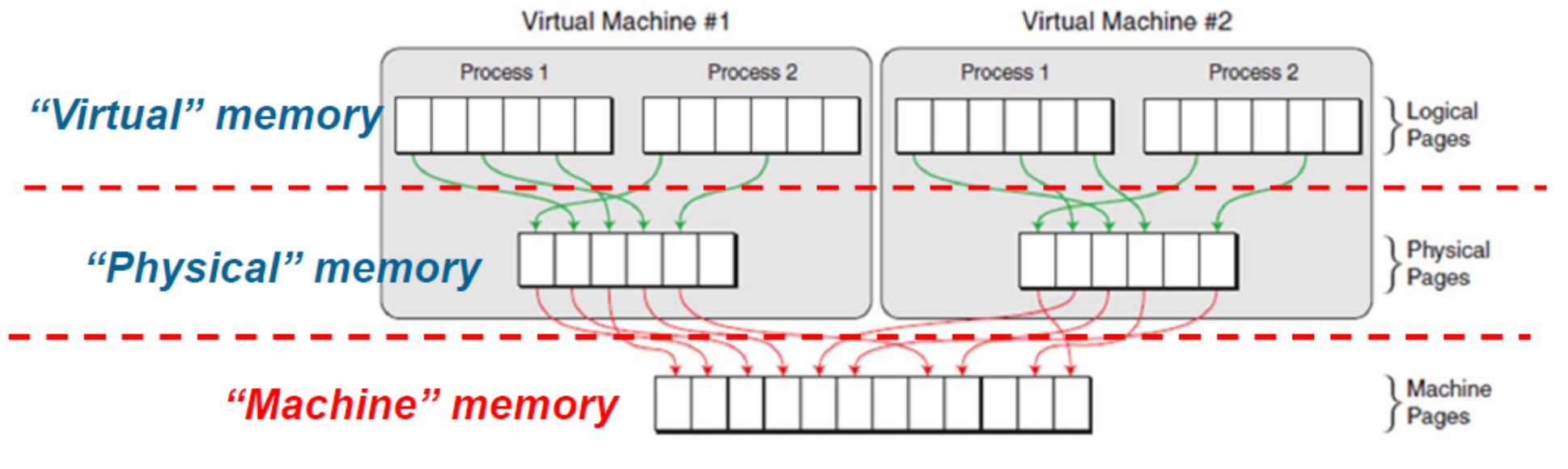
VMWare
- (Guest )Virtual memory (VA):the memory requested by the application
- (Guest) Physical memory (PA):the memory allocated to the virtual machine operating system
- (Host) Machine memory (MA):DRAM installed in your machine.
详情
虚拟机监视器(Virtual Machine Monitor,VMM)或虚拟机管理器(Hypervisor)是在宿主机操作系统之下运行的,它具有直接访问和管理物理硬件(包括内存)的能力。这意味着它可以直接与硬件MMU进行交互,管理物理内存的分配,并控制虚拟到物理地址的映射。
- 当VMM为虚拟机分配内存时,它通常会直接从物理内存中划分出一部分给虚拟机,然后通过管理虚拟到物理地址的映射(通常通过使用像Shadow Page Tables这样的机制),使虚拟机能够像在直接访问物理内存一样使用这部分内存。
- 在这个过程中,宿主机的操作系统并不知道这部分内存已经被VMM分配给了虚拟机,所以它不会对这部分内存进行分页或其他内存管理操作。
然而,需要注意的是,虽然VMM可以直接管理物理内存,但它仍然需要硬件MMU来完成虚拟到物理地址的映射。这是因为虚拟机内部的软件(包括其操作系统和应用程序)仍然在使用虚拟地址,所以我们仍然需要MMU来将这些虚拟地址转换为物理地址。
关于虚拟机监视器或虚拟机管理器的内存是否会被宿主机的操作系统分页,这取决于具体的虚拟化实现和配置。
- 在许多情况下,VMM/Hypervisor 会直接管理物理内存,并为每个虚拟机分配一部分物理内存。在这种情况下,VMM/Hypervisor 的内存不会被宿主机的操作系统分页,因为它直接控制了物理内存。
- 然而,在某些虚拟化实现中,例如在某些类型的容器虚拟化中,虚拟机或容器可能会使用宿主机操作系统的内存管理和分页机制。在这种情况下,虚拟机监视器或虚拟机管理器的内存可能会被宿主机的操作系统分页。
总的来说,这要取决于具体的虚拟化技术和实现方式。在传统的硬件虚拟化中,VMM/Hypervisor 通常会直接管理和控制物理内存。而在某些更轻量级的虚拟化或容器化技术中,可能会使用宿主机操作系统的内存管理和分页机制。
Memory Management Unit
分页是由操作系统软件和硬件内存管理单元(MMU)共同实现的。
操作系统负责创建和管理页表,这是一种数据结构,用来存储虚拟页(来自应用程序或进程的虚拟内存地址)到物理页(实际物理内存地址)的映射。当程序请求访问某个虚拟地址时,操作系统会查找对应的页表,找到对应的物理地址。
硬件MMU的角色是在运行时执行这种虚拟到物理的地址转换。当CPU尝试访问一个虚拟地址时,MMU会查找页表,将虚拟地址转换为物理地址,然后访问对应的物理内存。这个过程对于运行在CPU上的程序是透明的,程序只需要处理虚拟地址。
此外,MMU还负责其他一些与内存管理相关的功能,如内存保护(防止进程访问其他进程的内存)和分页异常处理(如当程序试图访问未映射或不允许访问的内存时)。
所以,分页功能的实现需要操作系统软件和硬件MMU的共同工作。操作系统负责管理页表,而硬件MMU负责在运行时进行地址转换。
Problems
What are the Problems?
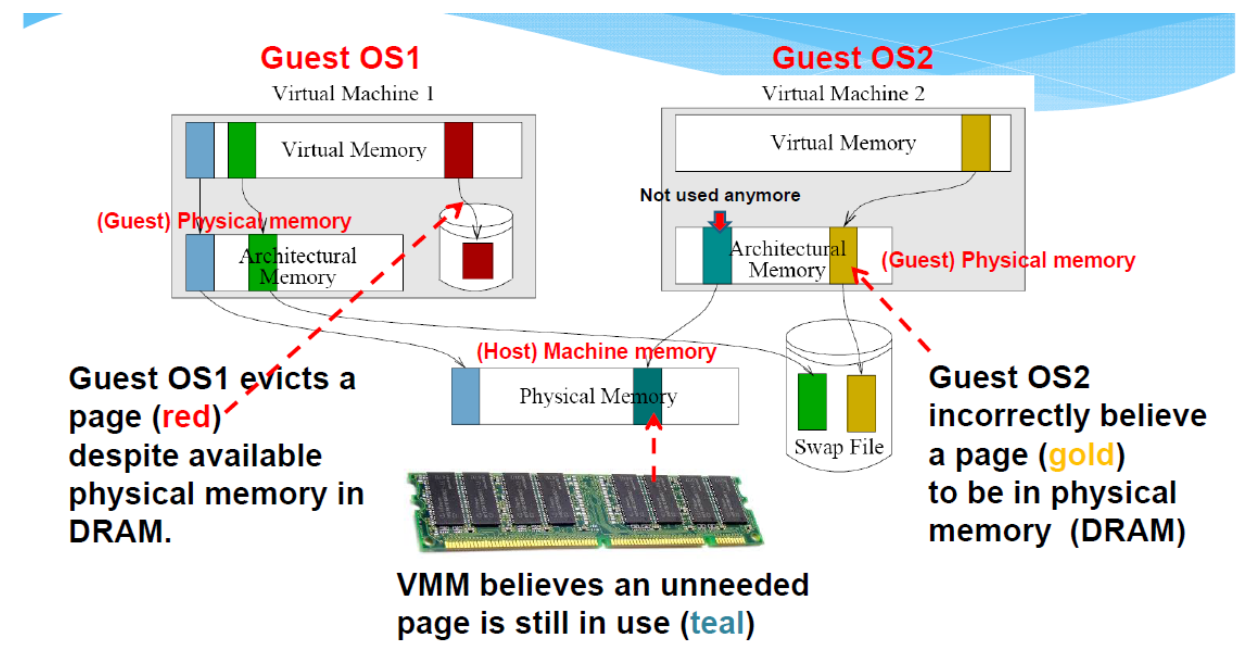
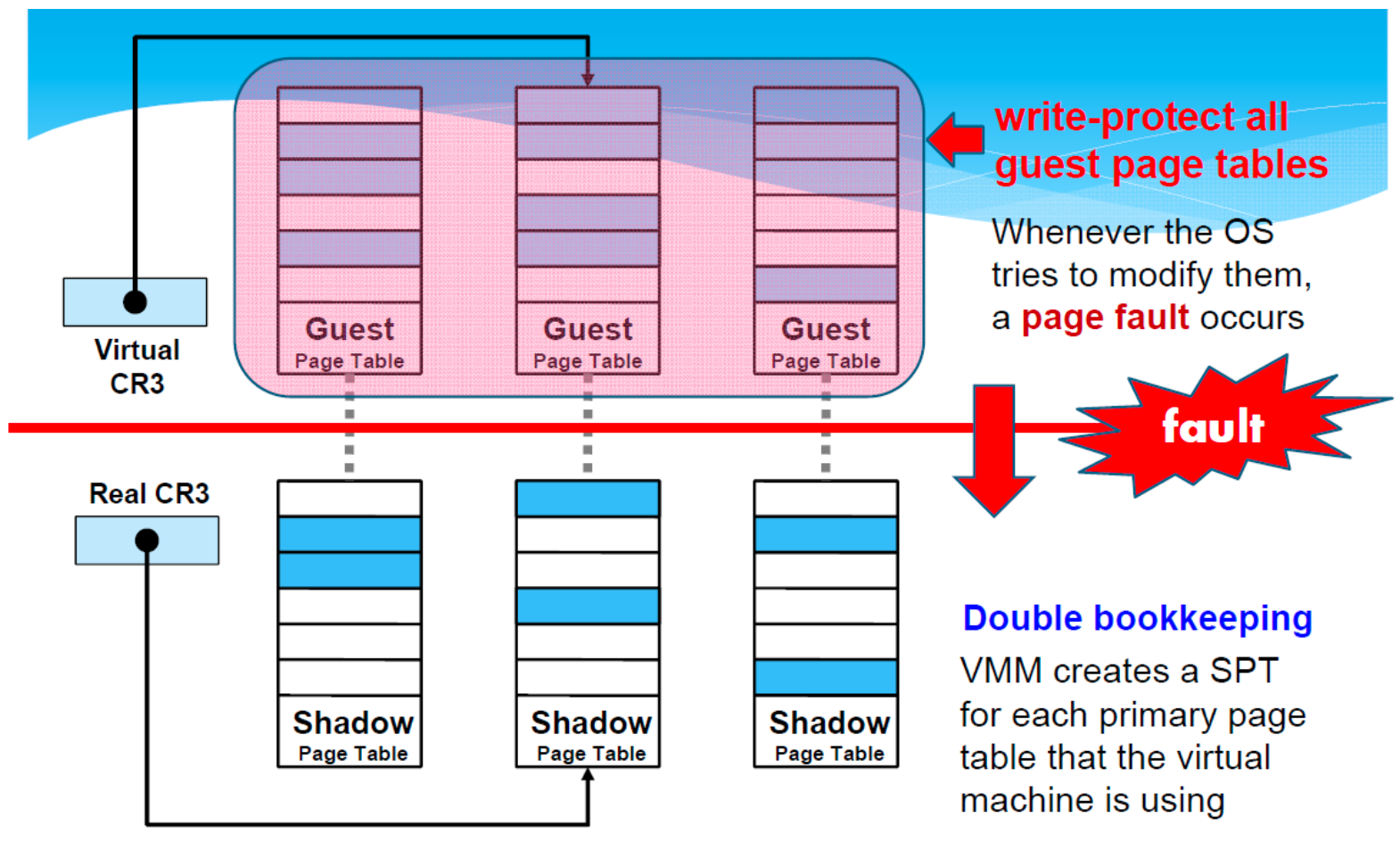
VMware Shadow Page Tables (SPT)
- Two sets of page tables are maintained
- The guest virtual page tables aren't visible to MMU 「 memory management unit」.
- The hypervisor 捕获「trap」虚拟页表更新,并负责验证这些更新并将更改传播到 MMU "影子 "页表。
详情
Shadow Page Tables (SPT) 是一种硬件辅助的虚拟化技术,用于管理虚拟机 (VM) 的内存。这是一种在虚拟化环境中实现内存管理的方法,它在 VMware ESXi 和其他一些虚拟化平台中被广泛使用。Shadow Page Tables 能够提供高效的内存地址转换,从而使虚拟机能够像在物理机上一样运行。
虚拟机的内存管理需要两步转换:
- 首先,从虚拟机的虚拟地址空间转换到虚拟机的物理地址空间,
- 然后再从虚拟机的物理地址空间转换到宿主机的物理地址空间。
这两步转换通常通过页表来完成。在没有硬件辅助的情况下,这两步转换都需要软件(即虚拟机监视器,VMM)来完成,这将导致很大的性能开销。
Shadow Page Tables 的工作原理是这样的:
- 当虚拟机试图访问其内存时,虚拟机监视器 (VMM) 会拦截这个操作,并查看其对应的 Shadow Page Table。
- 如果所需的映射在 Shadow Page Table 中存在,那么 VMM 就会使用这个映射,
- 否则,它会创建一个新的映射,并将其添加到 Shadow Page Table 中。
这样,VMM 就可以直接使用 Shadow Page Table 来完成地址转换,而无需进行两步转换,从而大大提高了性能。
然而,Shadow Page Tables 也有其缺点。例如,它需要 VMM 维护和管理 Shadow Page Tables,这会增加 VMM 的复杂性。此外,每当虚拟机修改其页表时,VMM 都需要更新相应的 Shadow Page Table,这可能会导致额外的性能开销。因此,一些现代的虚拟化平台已经开始使用其他的内存管理技术,如硬件辅助的页表(例如,Intel 的 Extended Page Tables,EPT)。
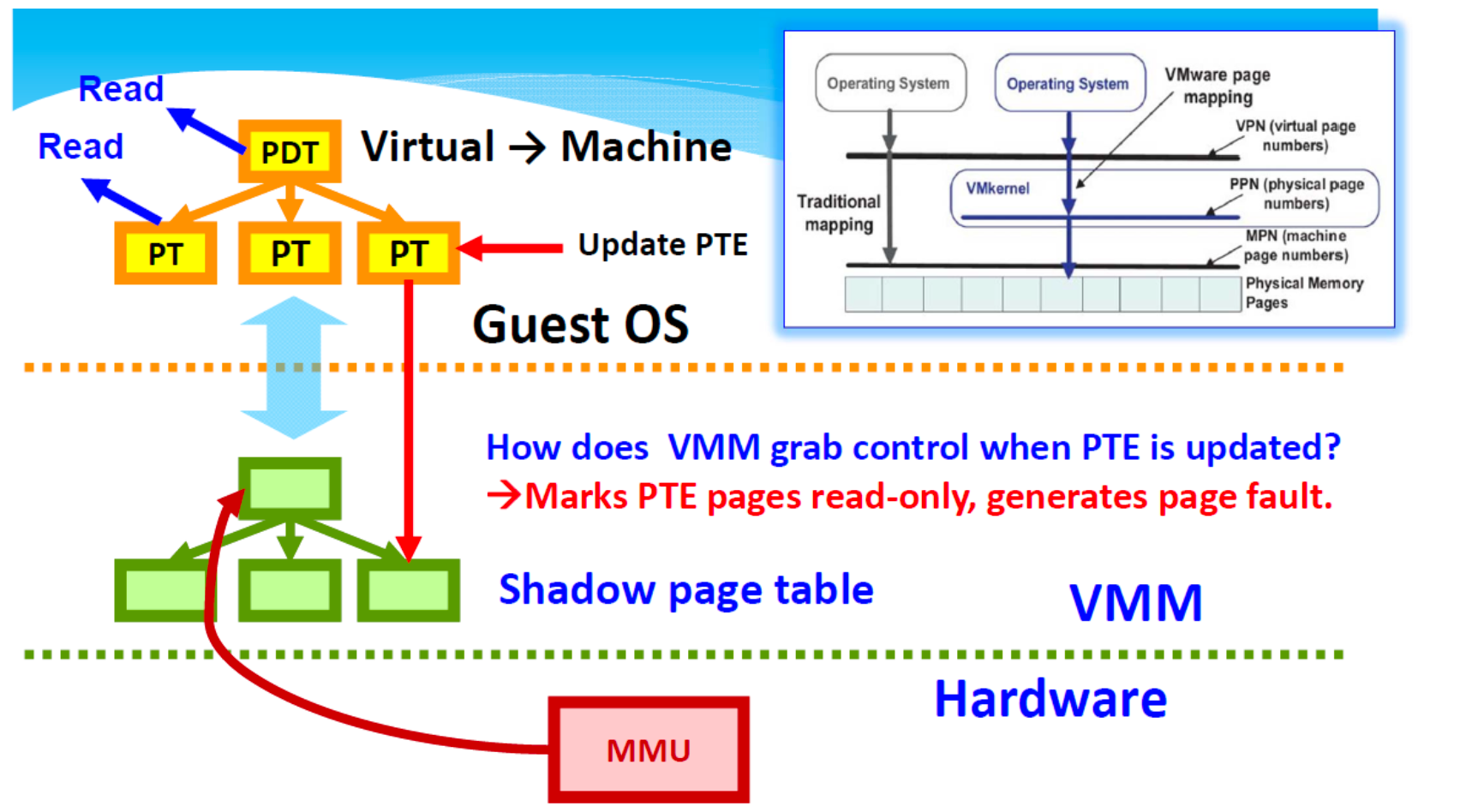
- VMM 为每个进程保留单独的影子页表。
- VMM 在影子页表中维护虚拟到机器 (V2M) 页映射
- 在内部数据结构中维护物理到机器(P2M)映射
- 如何?虚拟机管理程序拦截操作来宾操作系统内存管理结构的虚拟机指令。
- 最近使用的 LPN->MPN 转换缓存在硬件 TLB 中。
- Note: Logical Page Numbers (LPNs)>Machine Page Numbers (MPNs)
- 虚拟机不会直接更新处理器上的实际内存管理单元(MMU)。
Issues with Shadow Page Table
- Overhead in Maintaining Page Table Consistency
- (bad) Process creation in virtual machines is slower.
- (bad) First memory access after process creation is slower:the shadow page table entry mapping this memory is created on demand.
- Context switch:VMM must intervene to switch the physical MMU to the new process'shadow page table root(PGD).
详情
Context Switch:这是操作系统用来在多个进程之间共享单个 CPU 的技术。当一个进程从运行状态转换到等待状态(或者反过来)时,操作系统会保存当前进程的状态(即“上下文”),然后加载另一个进程的状态。这个过程被称为上下文切换。
- Physical MMU:内存管理单元(Memory Management Unit, MMU)是一种硬件设备,它负责管理虚拟内存到物理内存的映射。物理 MMU 是指在物理硬件层面上实现这种映射的 MMU。
- Shadow Page Table:这是一种硬件辅助的虚拟化技术,用于管理虚拟机的内存。Shadow Page Table 是虚拟机监视器(VMM)用来跟踪虚拟机页表和物理页表之间映射关系的数据结构。
- PGD (Page Global Directory):在分页系统中,页全局目录是页表层次结构的顶层。每个进程都有自己的页全局目录,它包含了该进程所有的虚拟内存到物理内存的映射。
所以,当你看到 "Context switch: VMM must intervene to switch the physical MMU to the new process's shadow page table root (PGD)" 这句话时,它的意思是:
在上下文切换过程中,虚拟机监视器(VMM)必须介入,以将物理内存管理单元(MMU)切换到新进程的 Shadow Page Table 的根(也就是新进程的页全局目录,PGD)。这是因为每个进程都有自己的虚拟内存空间,所以它们各自的页表(和对应的 Shadow Page Table)都是不同的。因此,当进行上下文切换时,VMM 需要更新物理 MMU,以确保它使用正确的 Shadow Page Table,从而正确地映射虚拟内存到物理内存。

"Memory Bloat':
- 影子页表会消耗额外的内存。
- Double bookkeeping -> x2 memory consumption
Xen: Direct Page Tables Access (a.k.a.Direct Paging)
Xen: Direct Paging -> Para-virtualised MMU model
- 客户操作系统允许对真实页表进行只读访问。
- 更新仍必须通过管理程序,由管理程序进行验证。
- 客户操作系统使用超级调用分配和管理自己的页表
- 操作系统不得向自身提供不受限制的 PT 访问、对虚拟机管理程序空间的访问或对其他 VM 的访问。
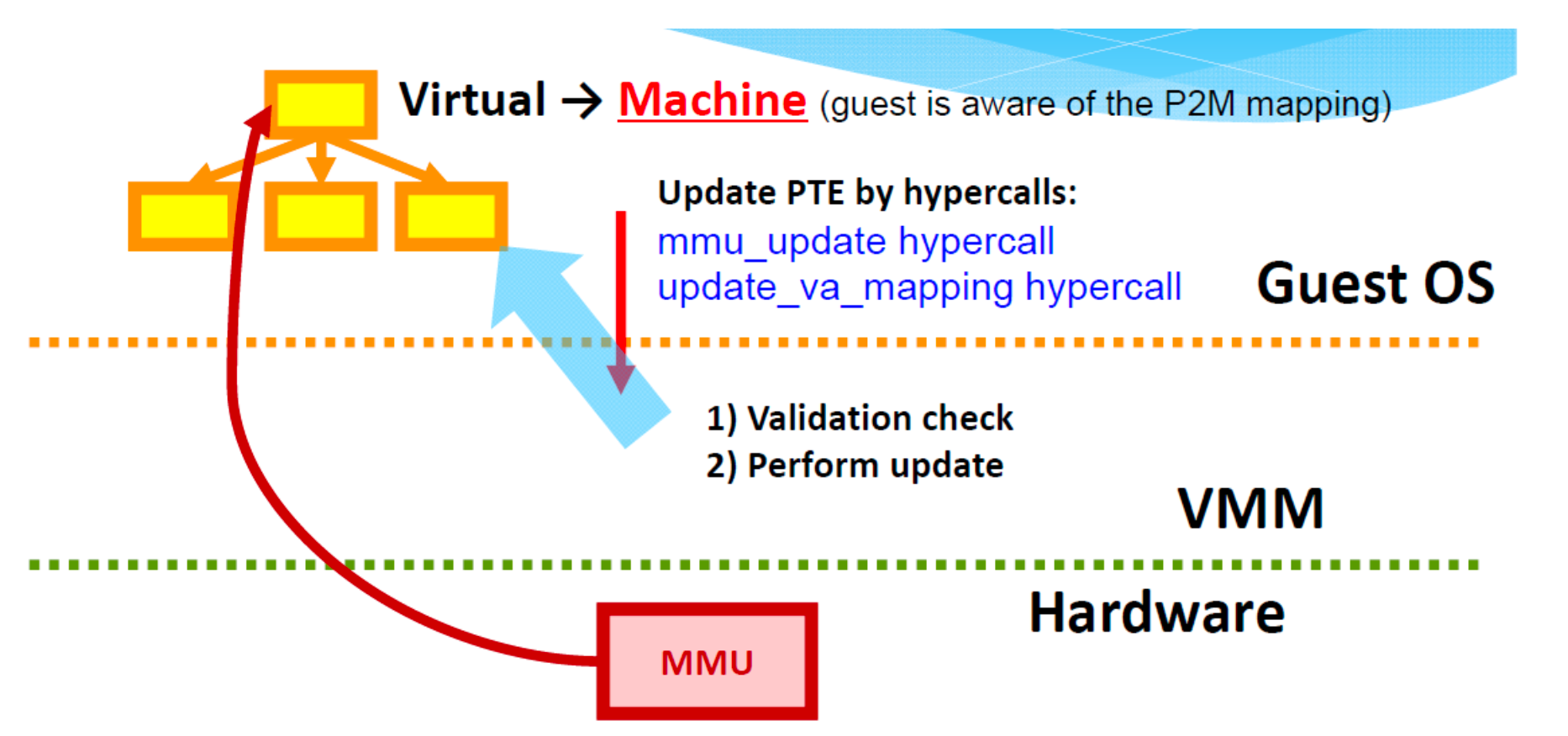
Xen 是一个虚拟机监视器(VMM),它允许多个操作系统同时运行在同一台物理机器上。Xen 使用一种称为硬件抽象层(HAL)的技术,将物理硬件资源抽象化,以便可以在多个虚拟机之间共享。
在 Xen 中,Direct Page Tables Access 或 Direct Paging 是一种内存管理技术。在传统的虚拟化环境中,每个虚拟机都有自己的页表,用于映射虚拟地址到物理地址。这种映射由虚拟机监视器(VMM)管理,但这种管理过程可能会导致性能开销。
Direct Paging 是一种解决这种性能开销的方法。通过 Direct Paging,虚拟机可以直接访问和管理其页表,而无需通过 VMM。这可以减少虚拟化的开销,提高性能。
然而,Direct Paging 也有其挑战和限制。例如,虚拟机必须能够处理页表的复杂性,包括处理页错误和其他相关的硬件异常。此外,由于虚拟机直接访问和管理其页表,因此需要确保虚拟机不能修改其他虚拟机或主机的页表,以防止潜在的安全问题。

- 客户操作系统分配和管理自己的 PT
- Each domain has a maximum memory allocation "reserved"at domain creation time.(isolation)
- Domain can increase/decrease its quota with its "ballon"driver.
- When starting a new process,it allocates and initializes a page from its own memory reservation and registers with Xen.
- Guest OS has read-only access to the page tables
- All updates go through the hypervisor,which validates them
- Hypercalls can be used to modify page-table entries,update the machine-tophysical mapping table,flush the TLB「Translation Lookaside Buffer」,load a new page-table base pointer,...
- Optimization:Updates can be batched into a single hypercall (reduce cost of entering/exiting Xen)
l/O Virtualization
I/O Devices :keyboard,mouse,graphics display,real-time clock, 8259 programmable interrupt controller,CMOS,disk drive,CD-ROM etc.
l/O 虚拟化环境是通过将上层协议从物理连接中抽象出来而创建的。
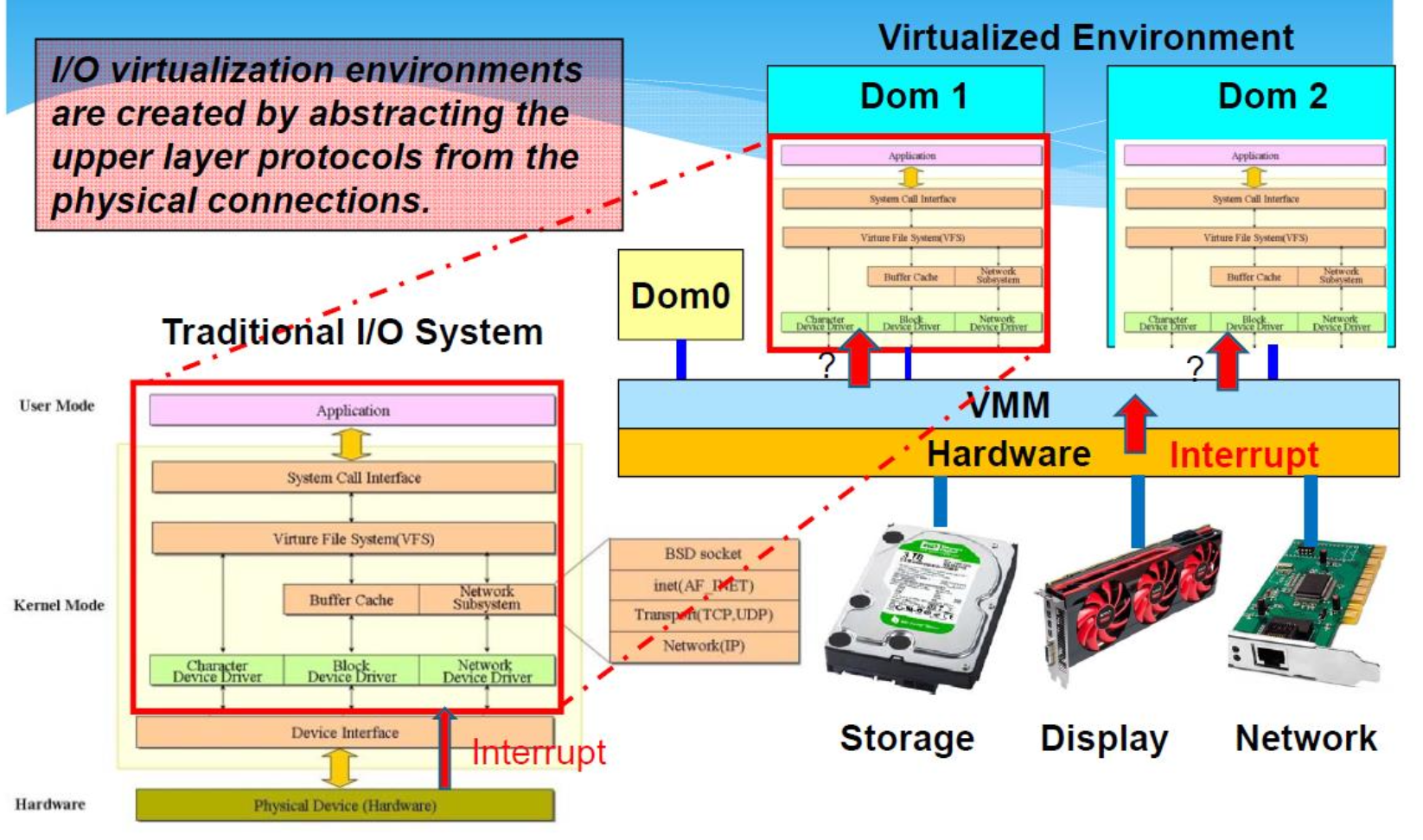
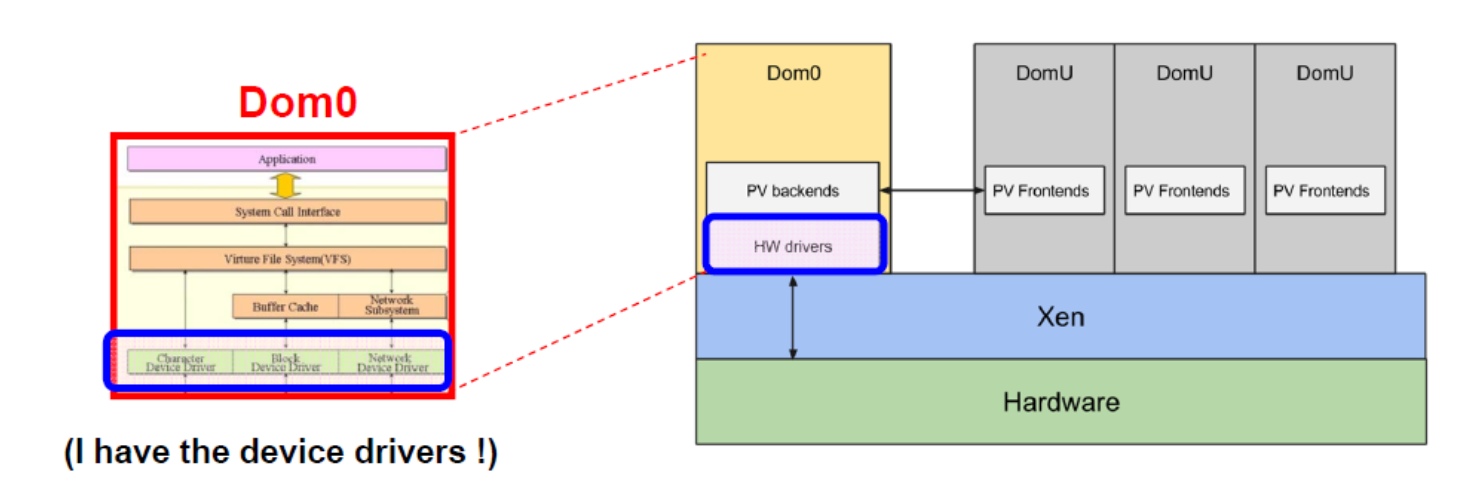
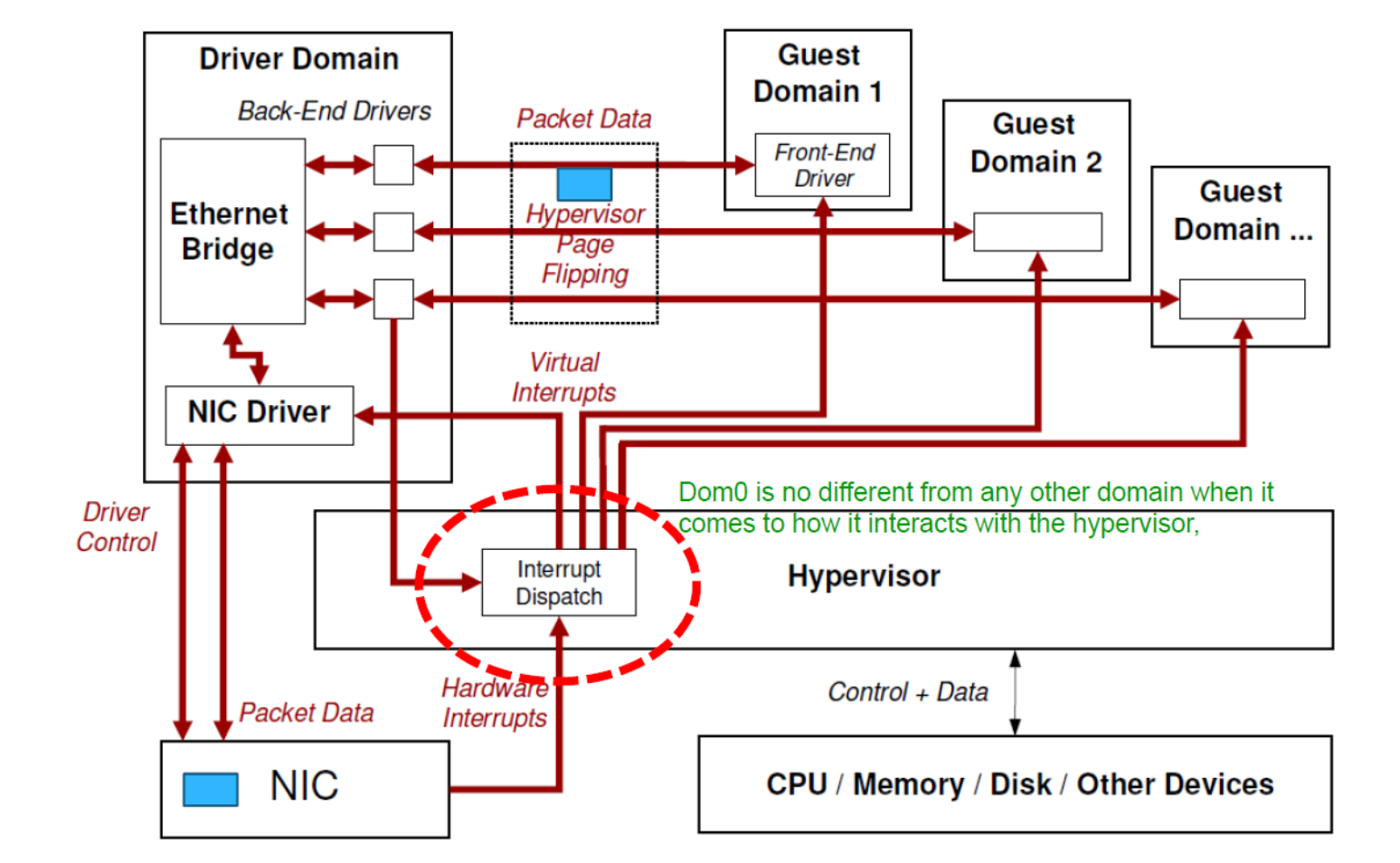
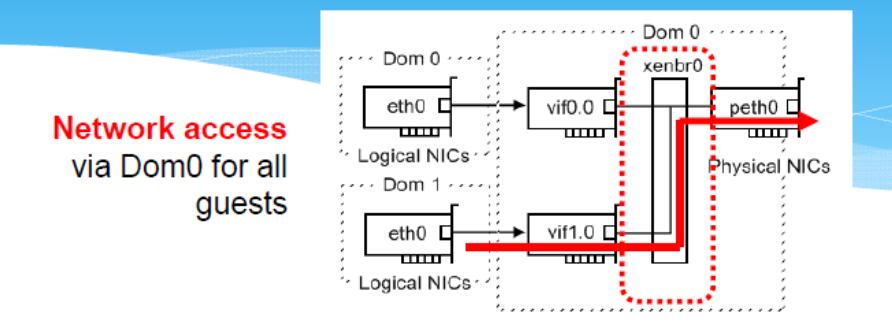
Xen: Split Device Driver Model
- Xen 利用现有的驱动程序代码 -> 真正的驱动程序位于 Dom0 中。
- 每个客户操作系统(DomU)只需要实现“模拟「emulated」驱动程序”(前端接口「Front End Interface」),它将驱动程序调用转发给Domo中的真实驱动程序。
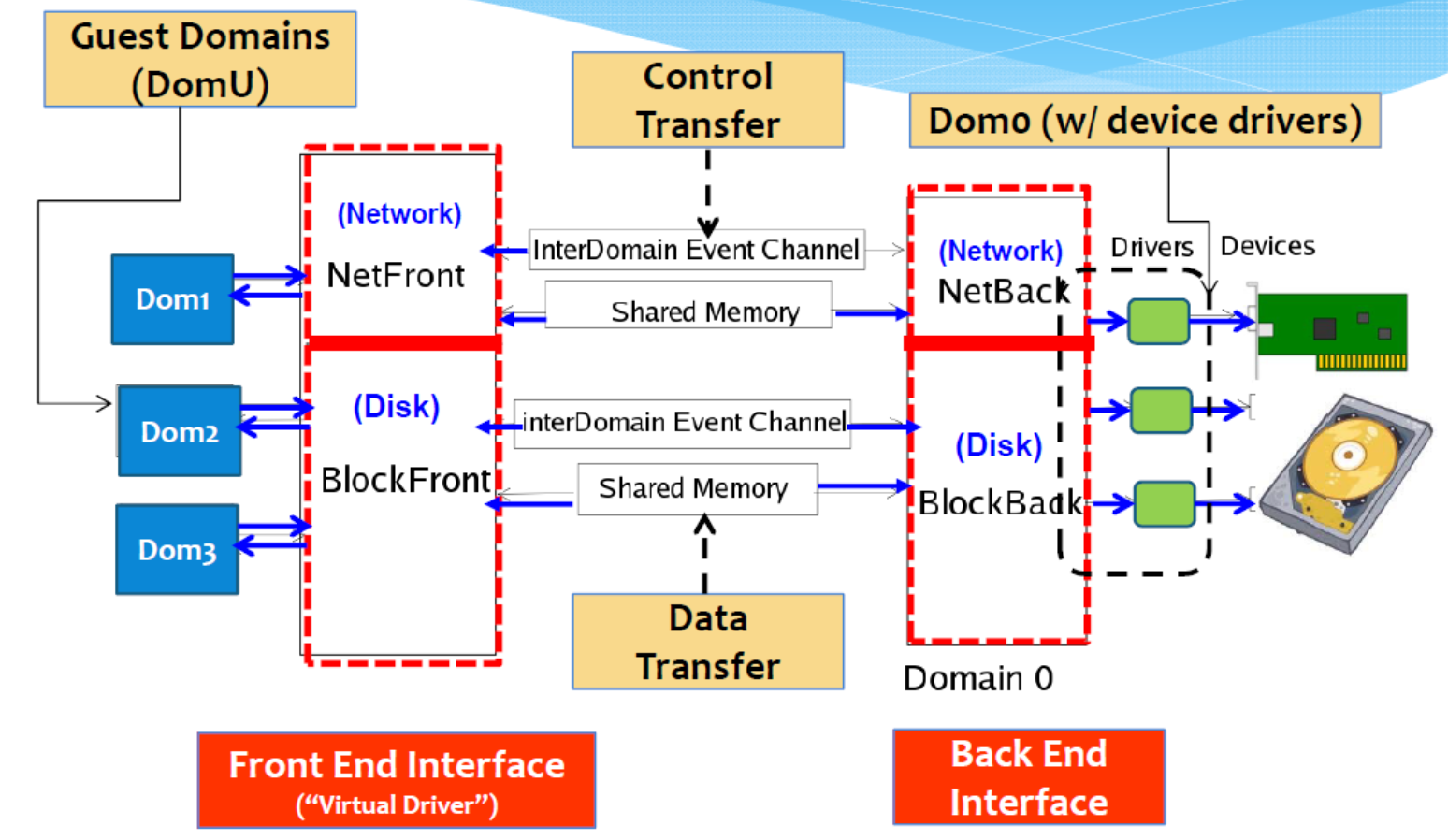
conceptual view
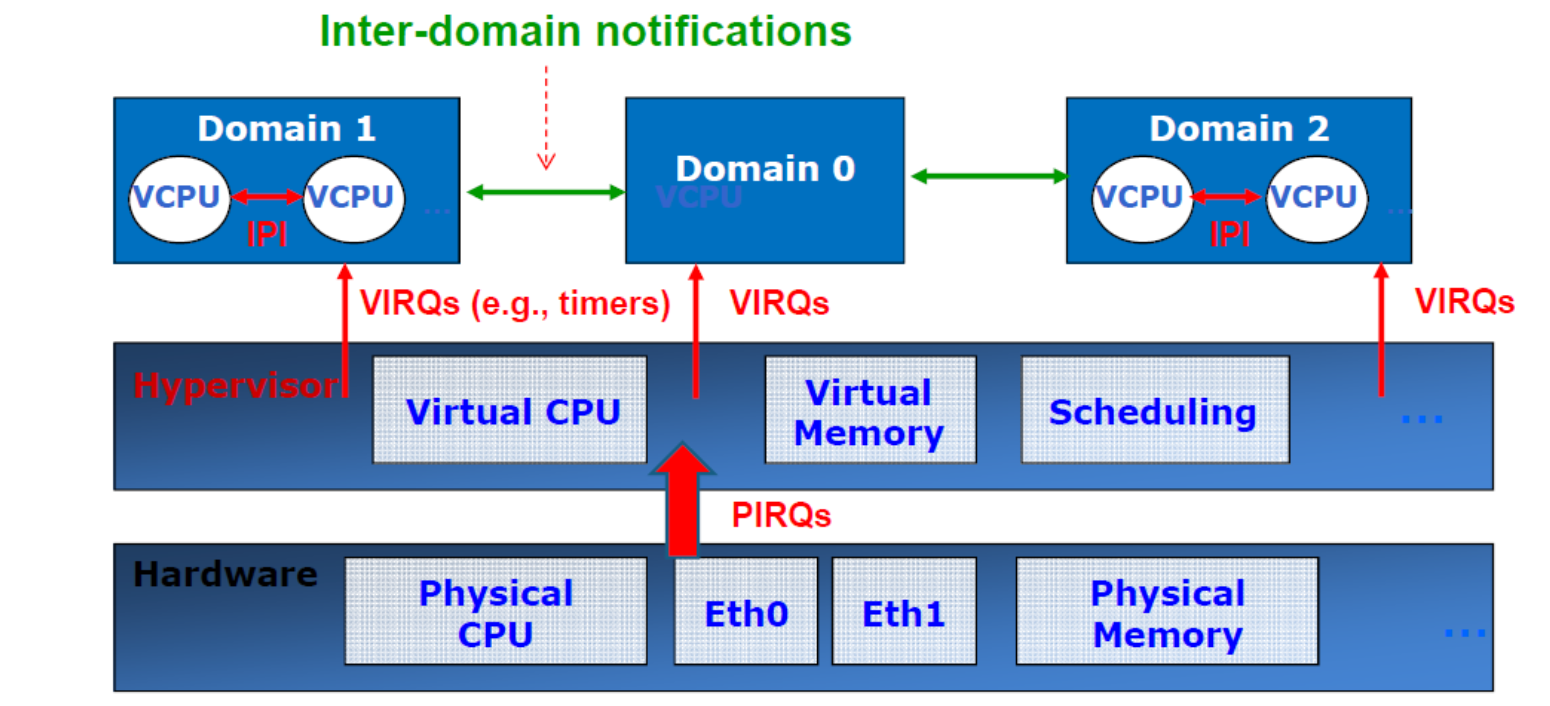
How to Handle Interrupt in Xen: Event Channels
Four types of events:
- Inter-domain notifications.
- E.g.,notifications between frontends and backends,
- VIRQS (virtual IRQ):Xen→Domo or Xen→DomU, typically for timers interrupts;
- IPIs (inter-processor interrupt):VCPU to VCPU
- PIRQs (physical IRQ):hardware interrupts.
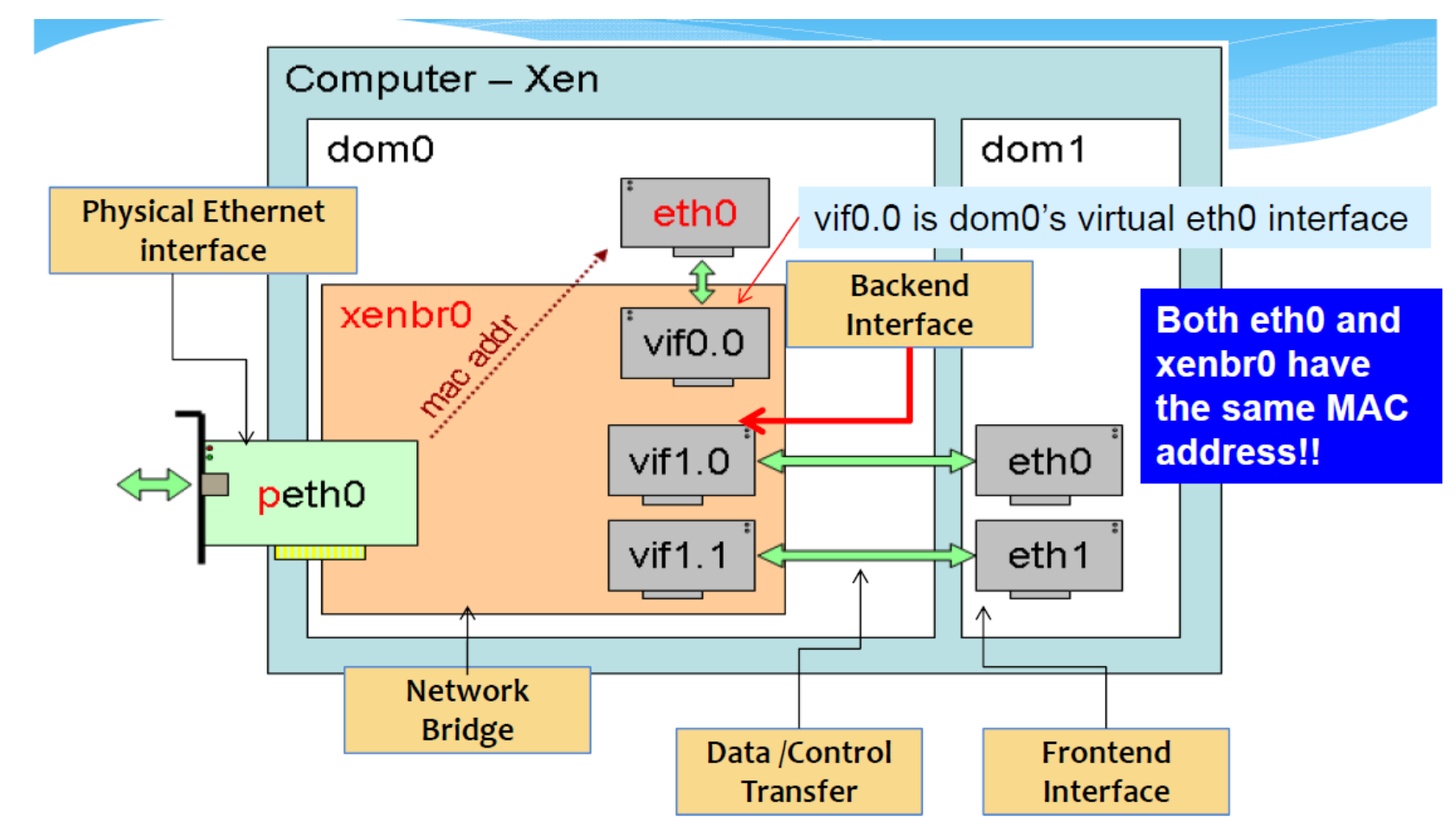
Xen: Network Virtualization
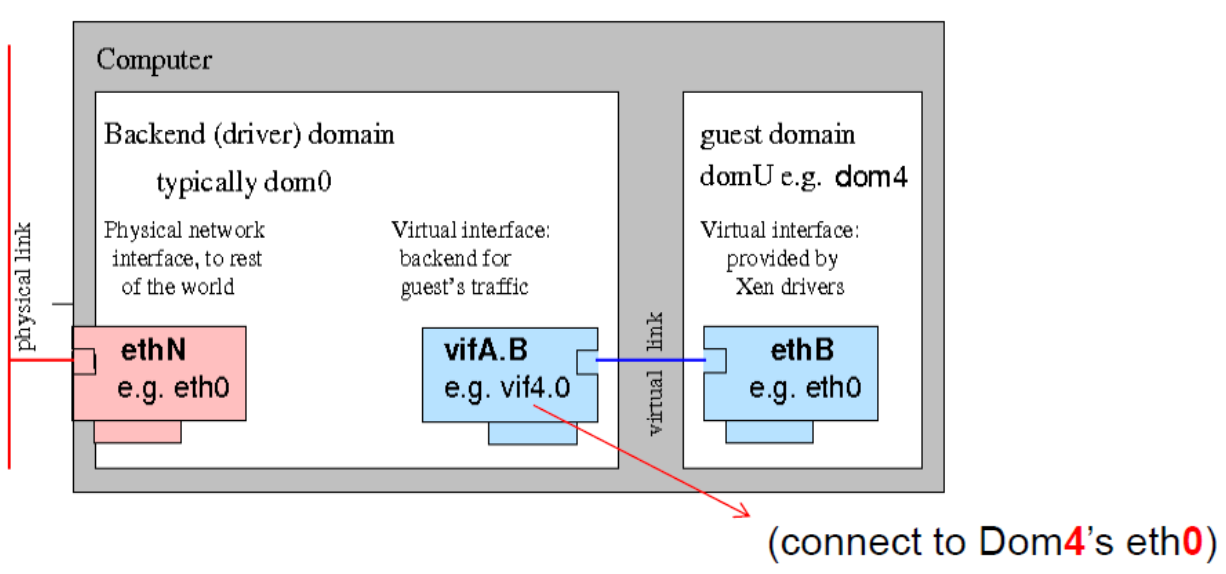
Network interfaces:
- Front-end within DomU: eth0,eth1,eth3,..(these are virtual NICs「网卡 (Network interface controller)」)
- Back-end in Domain-0: virtual interface (vif) :vif0.0,vif1.0,vif 2.0,..
- Netfront 和 Netback 之间的连接由虚拟机「hypervisor」管理程序提供(I/O 通道)。Domain-o 管理所有 netbacks
Virtual Network Interfaces
Virtual Interface
VIF 是 Virtual Interface 的缩写,它是虚拟化技术中的一个重要概念。
- 在虚拟化环境中,VIF 是物理设备(如网络接口卡、硬盘驱动器等)的虚拟表示,它允许虚拟机(VM)与物理设备进行交互。
在网络虚拟化中,VIF 通常指的是虚拟网络接口。每个虚拟机都会有一个或多个 VIF,这些 VIF 连接到虚拟交换机或虚拟网络。这样,虚拟机就可以像使用物理网络接口一样使用这些 VIF,进行网络通信。
提示
Xen 是一种虚拟化技术,它允许多个操作系统同时在同一台物理机器上运行。
Xen 中,有一个特殊的虚拟机称为 Domain 0(Dom0),它具有特权,可以访问物理硬件,并且可以控制其他的虚拟机(称为 Domain U 或 DomU)。
- 在网络虚拟化的环境中,Xen 使用一种称为虚拟网络接口(Virtual Network Interface,简称 VIF)的机制来为 DomU 提供网络服务
- 每个 DomU 都有一个或多个 VIF
- 这些 VIF 通过虚拟交换机(例如 Open vSwitch)或者网桥与 Dom0 中的物理网络接口(例如 eth0 或 eth1)连接。
具体来说,当一个 DomU 需要向网络发送数据时
- 数据会通过其 VIF,然后通过虚拟交换机或网桥,最后通过 Dom0 的物理网络接口发送出去。
- 反过来,当 Dom0 的物理网络接口接收到数据时,数据会通过虚拟交换机或网桥,然后通过相应的 VIF 传递给相应的 DomU。
在 Xen 中,还有一种称为 veth 的虚拟网络设备。
- veth 设备总是成对出现,当数据发送到一个 veth 设备时,数据会从另一个 veth 设备出来。
- 这种机制可以用来连接两个网络命名空间,或者连接一个网络命名空间和一个网桥。
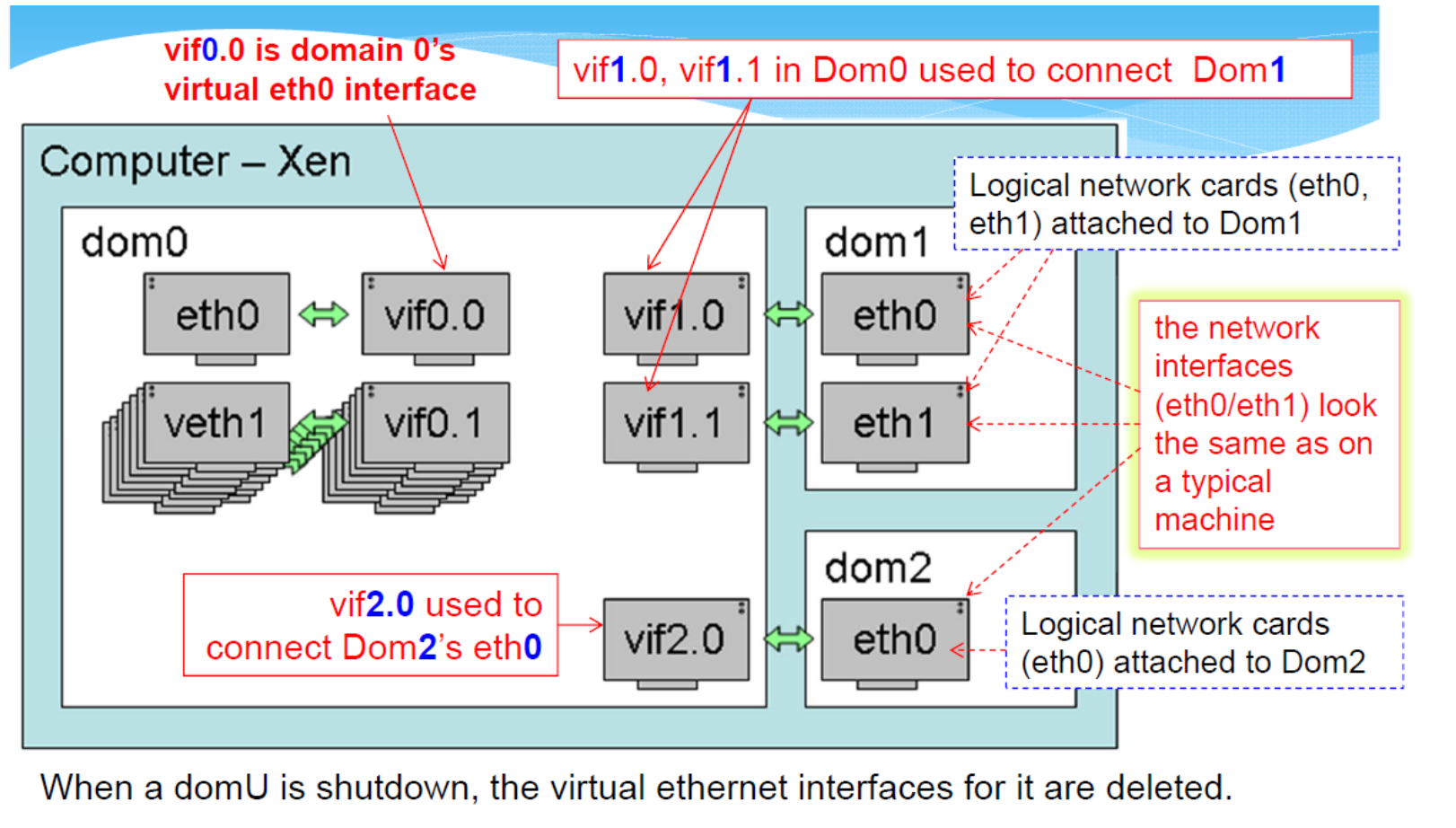
"VIF 1.0 1.1" 中,1.0 和 1.1 是 VIF 的标识符。
- 1.0 表示 Dom0 的第一个 VIF
- 1.1 表示 Dom0 的第二个 VIF
这些 VIF 可以连接到不同的虚拟交换机或网桥,从而连接到不同的物理网络接口,或者连接到不同的网络命名空间。
Defining Virtual Interfaces
每 demain 域都有一个配置文件,指定与该域关联的网络设置

- bridge:该接口使用的网桥
- ip:与虚拟网络接口相关联的 IP 地址
- mac:该虚拟接口的 MAC 地址
- 默认情况下,大多数 Xen 工具堆栈将选择随机地址
Special Note on MAC Address
根据工具堆栈,分配的 MAC 地址要么在来宾的整个生命周期内保持静态(例如 Libvirt、XAPI 或 xend“受管域”),要么在每次来宾启动时发生变化(例如 XL 或 xend“非受管域”) )。
MAC 地址在同一本地网段(例如包含 Xen 主机的 LAN 上)的所有网络设备(物理和虚拟)中必须是唯一的。
Network Bridge
VNIC 对于虚拟机来说就像一个真实的网络接口卡,虚拟机可以通过 VNIC 与外部网络通信
- VNIC 通常连接到 VIF
- 然后通过 VIF 连接到物理网络
VIF是虚拟接口的简称,
- 它是一种虚拟的网络设备,通常用于虚拟机或容器中。
- VIF可以用来连接虚拟机或容器和宿主机,或者连接虚拟机或容器和虚拟网络。
veth 则是一种特殊类型的网络设备,它总是成对出现。
- 这对设备可以用来连接两个网络命名空间。
- 当数据从一个veth设备发送出去时,它会从配对的veth设备出来。
- 这使得veth设备对于创建复杂的网络拓扑结构非常有用。
网桥,也被称为网络桥接器或者桥接器,
- 是一种用于连接两个或更多个网络段的设备,
- 它可以将这些网络段连接成一个大的网络。
网桥、VIF和veth经常一起使用,以创建复杂的虚拟网络环境。例如,你可能会创建一个网桥,然后将多个VIF或veth设备连接到这个网桥上。这样,通过这个网桥,所有连接的设备都可以相互通信。
Xen: Bridge Ports in Dom0
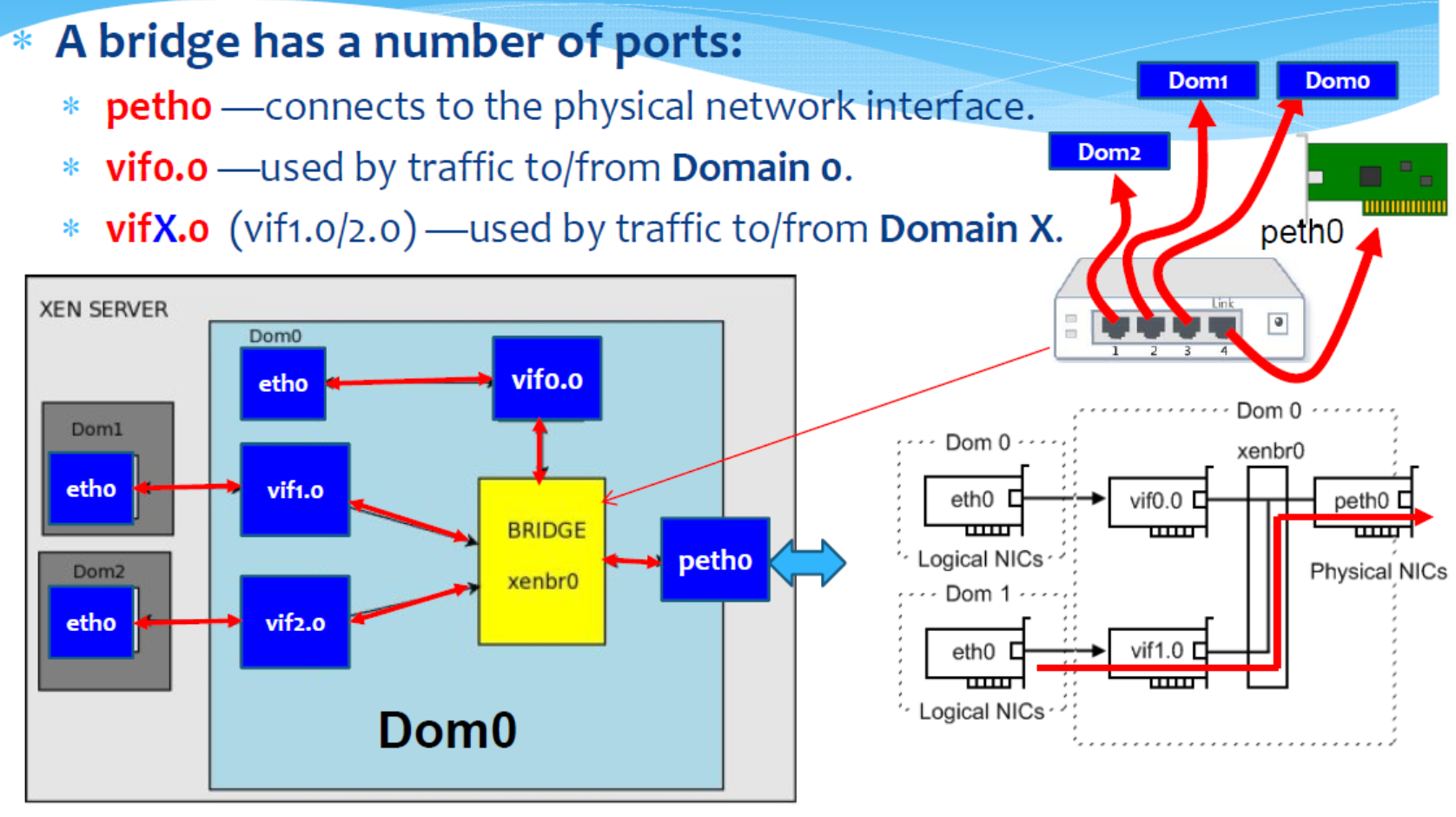
Example
我们有一个云服务提供商,他们提供虚拟机(VM)服务。他们的基础设施包括物理服务器,每个服务器上运行多个虚拟机。为了让这些虚拟机能够与外部网络通信,他们需要配置网络接口和相关的网络设备。
- 物理层(Physical Layer):在这一层,我们有物理服务器,它具有一个或多个物理网络接口卡(NIC)。
- 虚拟化层(Virtualization Layer):在物理服务器上,运行着一个虚拟化软件,如KVM或VMware。
- 这个软件可以创建和管理虚拟机。
- 每个虚拟机都有一个VNIC,这是虚拟网络接口卡,它模拟了物理NIC的功能。
- VNIC是虚拟机与虚拟化层之间的接口。
- 虚拟以太网(Veth):Veth是一对虚拟网络设备,它们在网络上表现得就像是通过以太网线缆连接的两个设备。
- 在我们的例子中
- 每个VNIC都连接到一个Veth设备
- 另一个Veth设备连接到虚拟接口(VIF)
- VIF是虚拟化层和物理层之间的接口。
- 在我们的例子中
- 网桥(Bridge):为了让多个虚拟机能够共享同一个物理NIC,我们需要一个网桥。
- 网桥是一种网络设备,它可以将多个网络接口连接起来,并在它们之间转发数据包。
- 在我们的例子中,所有的VIF都连接到同一个网桥,网桥又连接到物理NIC。
这样,当一个虚拟机发送一个数据包时,数据包会从VNIC传输到Veth,再从Veth传输到VIF,然后通过网桥和物理NIC发送出去。接收数据包的过程则是相反的。
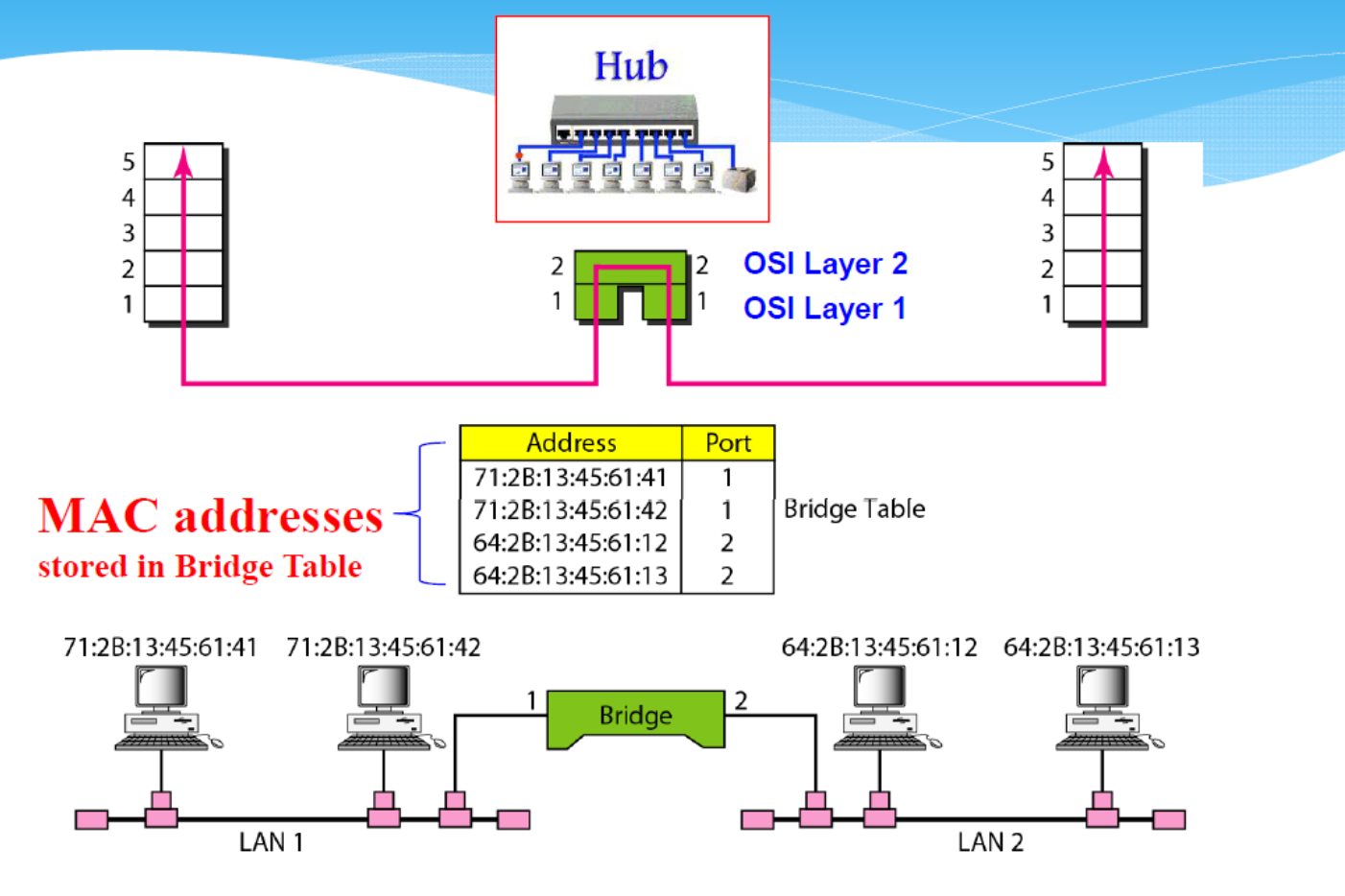
Bridging Virtualization
Xen 的默认网络配置:网桥模式 「Bridge mode」
- 允许所有域作为独立主机出现在网络上。
- Named xenbro or bro by default.
- 默认情况下,Xen 会为每个域分配一个随机 MAC 地址(00:16:3e:xx:xx:xx 范围内)。
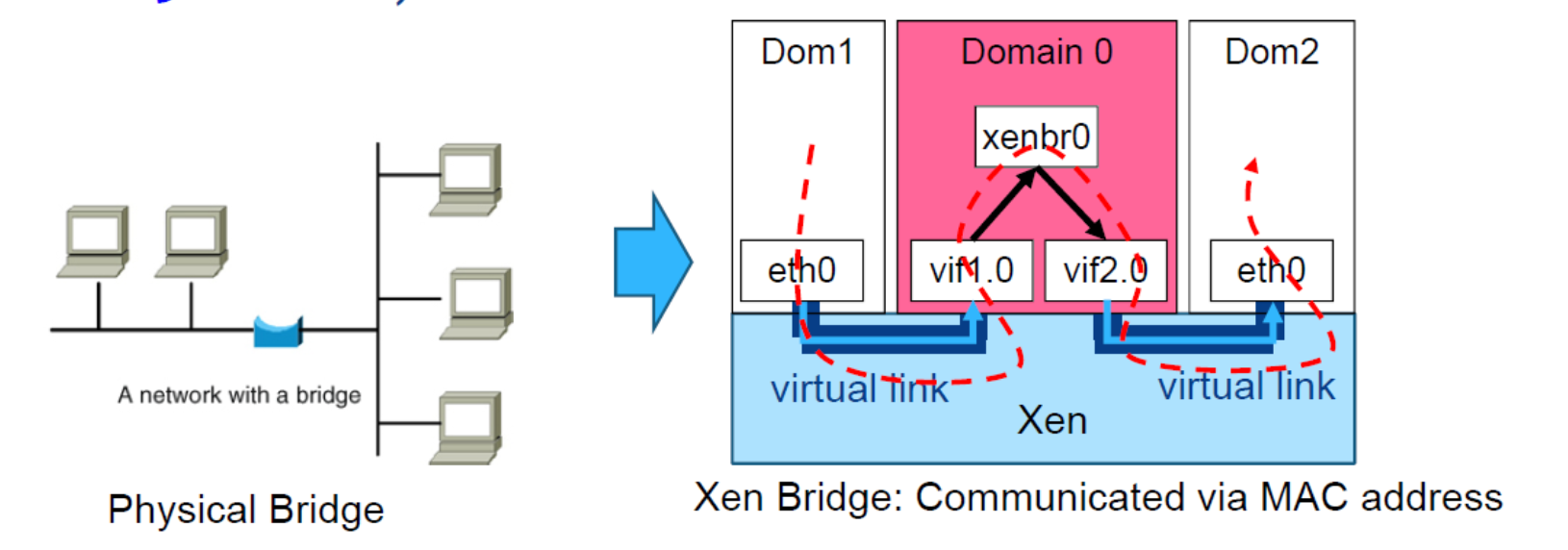
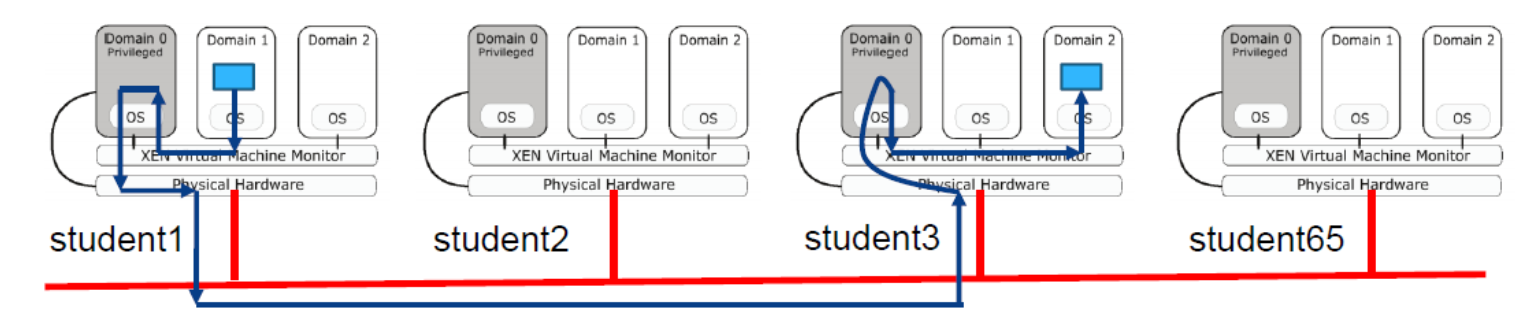
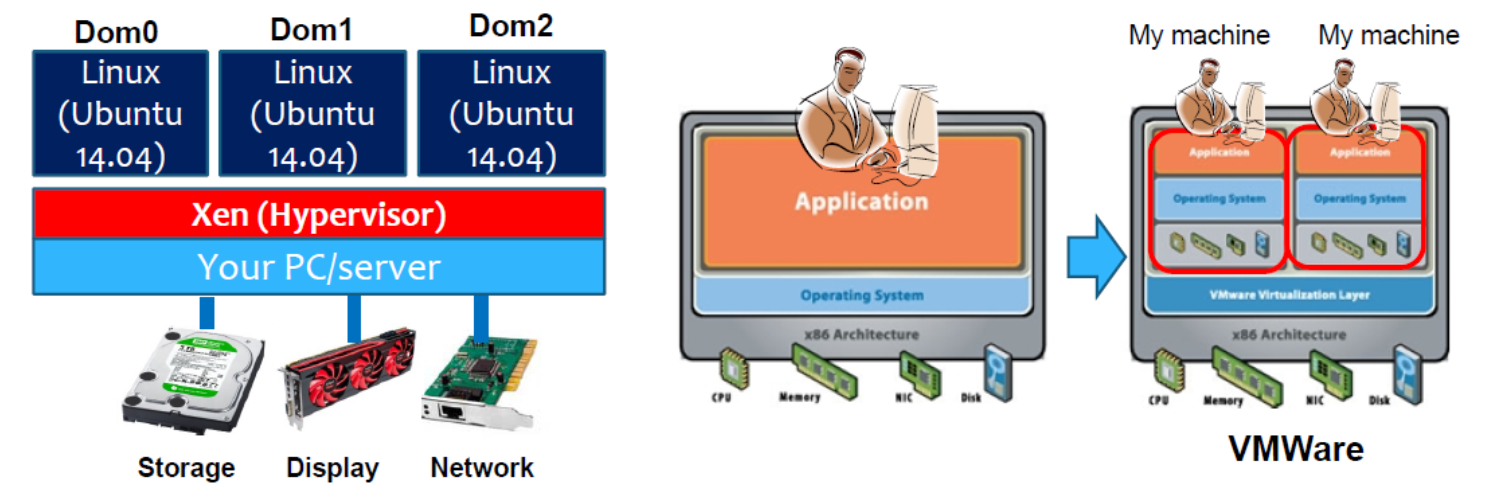
现在,每台 PC 都运行 3 个操作系统 (Dom0-2)。 所有域都将作为独立主机出现在网络上。
- 在网桥模式下,数据包根据 MAC 地址而不是 IP 地址转发。
- Xenbr0(Dom0 中的网络驱动程序)帮助将数据包路由到目的地