Apache Spark
大约 7 分钟
Apache Spark
- Offers over 80 operators.
- Languages binding Scala,Java,SQL, Python(PySpark),R(SparkR).
- RDD:in-memory cache > "Up to 100x faster than MapReduce"
- Deployment standalone,YARN, Mesos, Kubernetes(containers)
- External storage systems:HDFS, HBase,Amazon S3,Azure Storage,Azure Datalake,Google Cloud Storage,Cassandra, Alluxio,.…
Build-in Libraries
- Spark SQL: processing structured data with relational queries(newer API than RDDs->DataFrame API)
- Spark Structured Streaming: processing structured data streams with relation queries
- MLlib: Spark's machine learning (ML)library
- (new) DataFrame - based API in the spark.ml package
- GraphX: distributed graph-processing
- Page Ranking,Recommendation Systems, financial Fraud Detection, Geographic Information Systems,...
Architecture
- One Master node + multiple Worker nodes
- Equivalent to Hadoop's Master and Slave nodes.
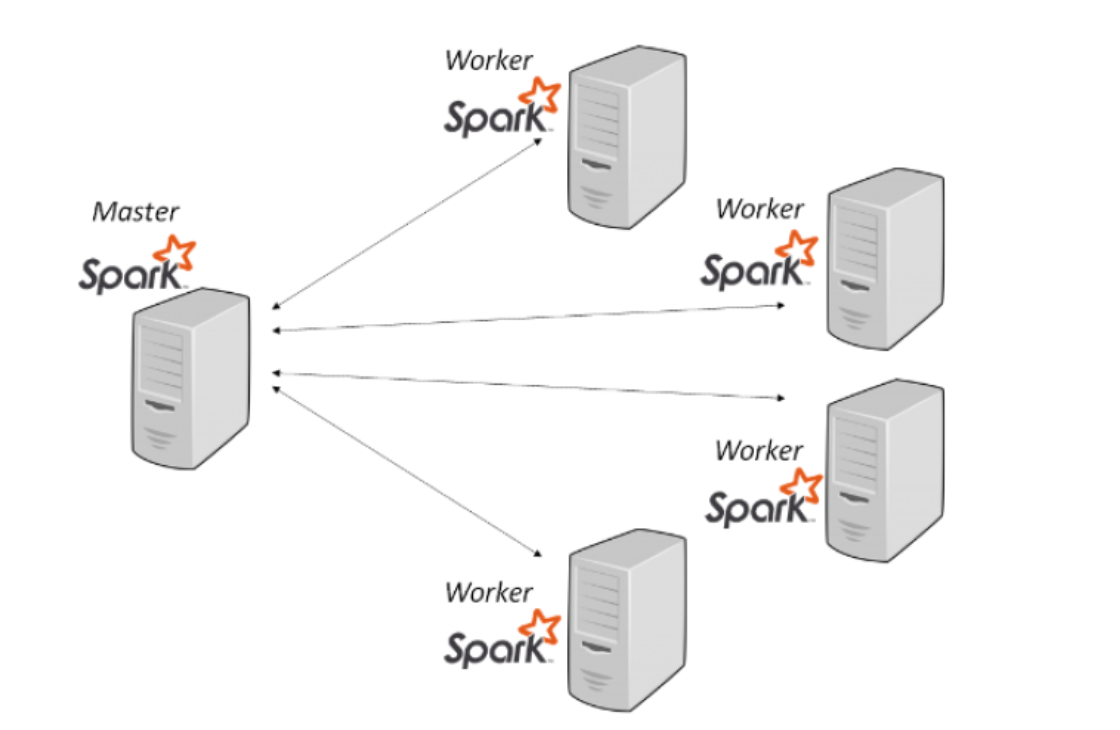
Key Elements of a Spark Cluster
- Spark Driver: your Spark application that launches the main method
- Cluster Manager: manages the resources of a cluster
- Support YARN,Kubernetes(K8S),Mesos,or Spark Standalone
- Workers:集群中任何可以运行应用程序代码的节点。
- Executors: Executors are worker nodes' JVM processes in charge of running individual tasks in a given Spark job.
Runs on Kubernetes
Each Spark app is fully isolated from the others and packages its own version of Spark and dependencies within a Docker image.
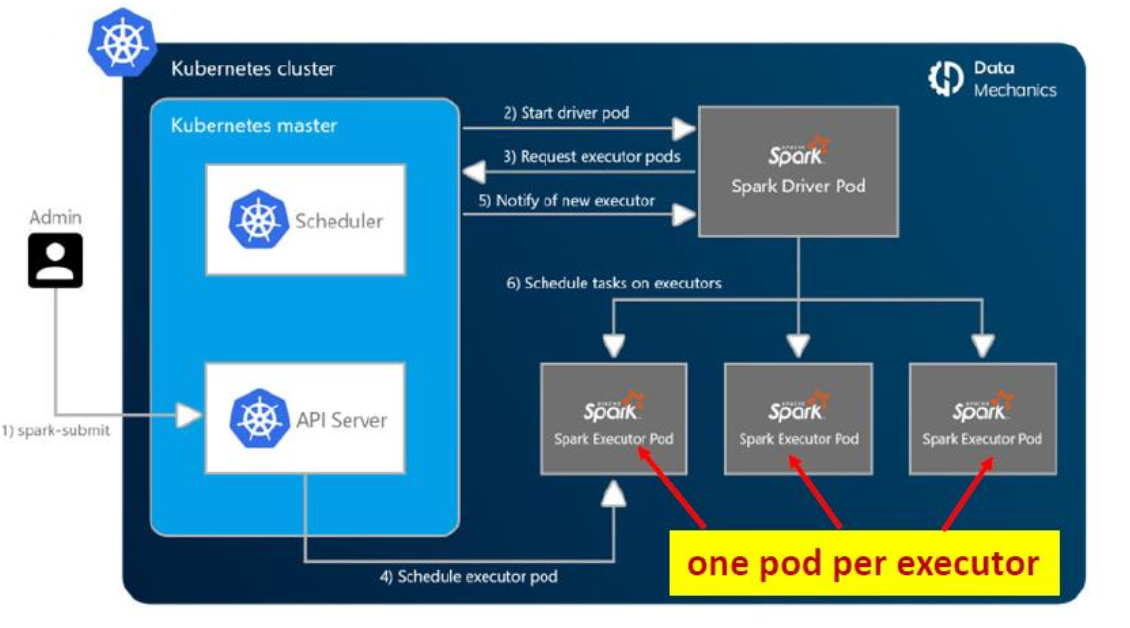
Runs on Yarn
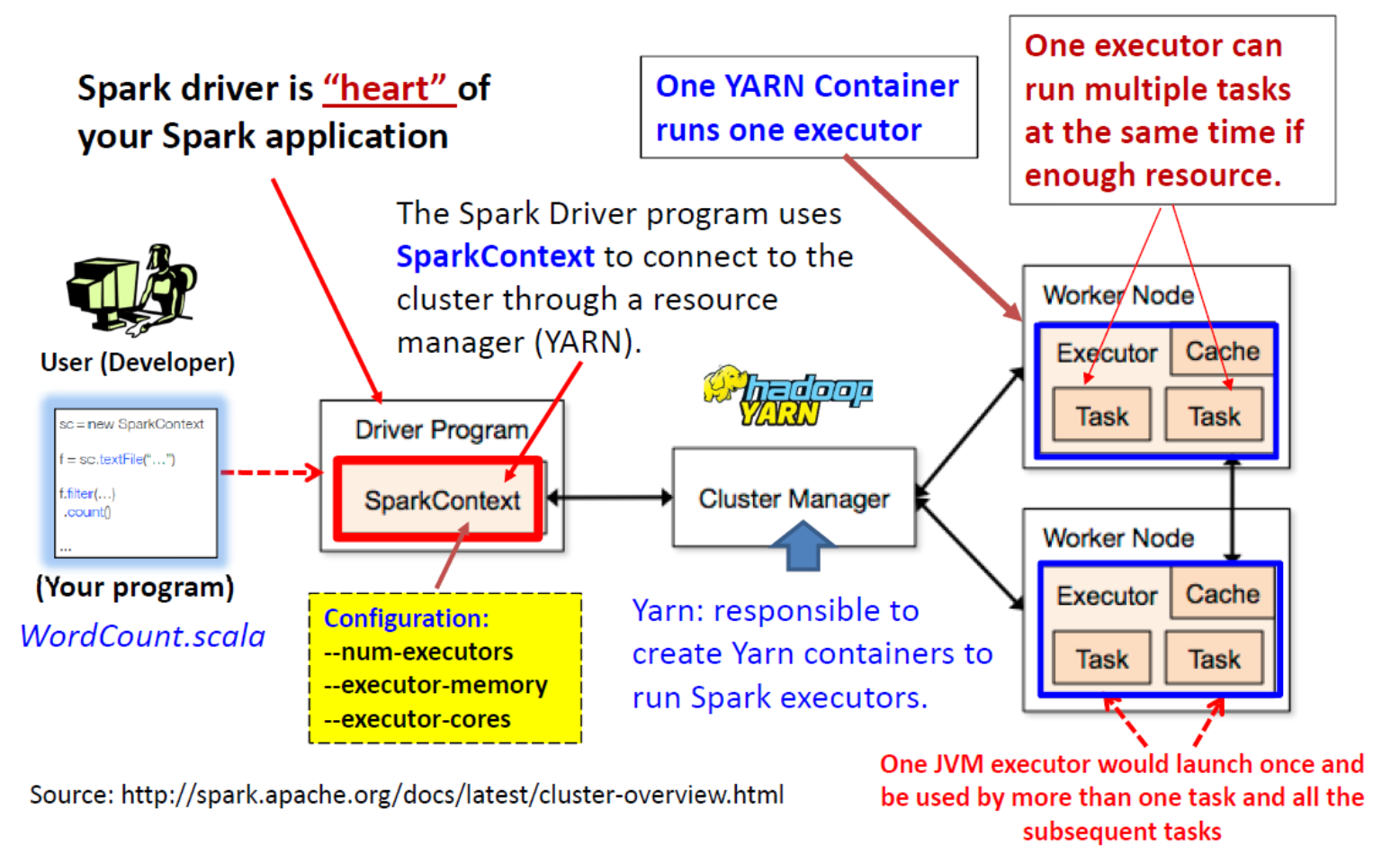
Spark Executors Runs on Yarn
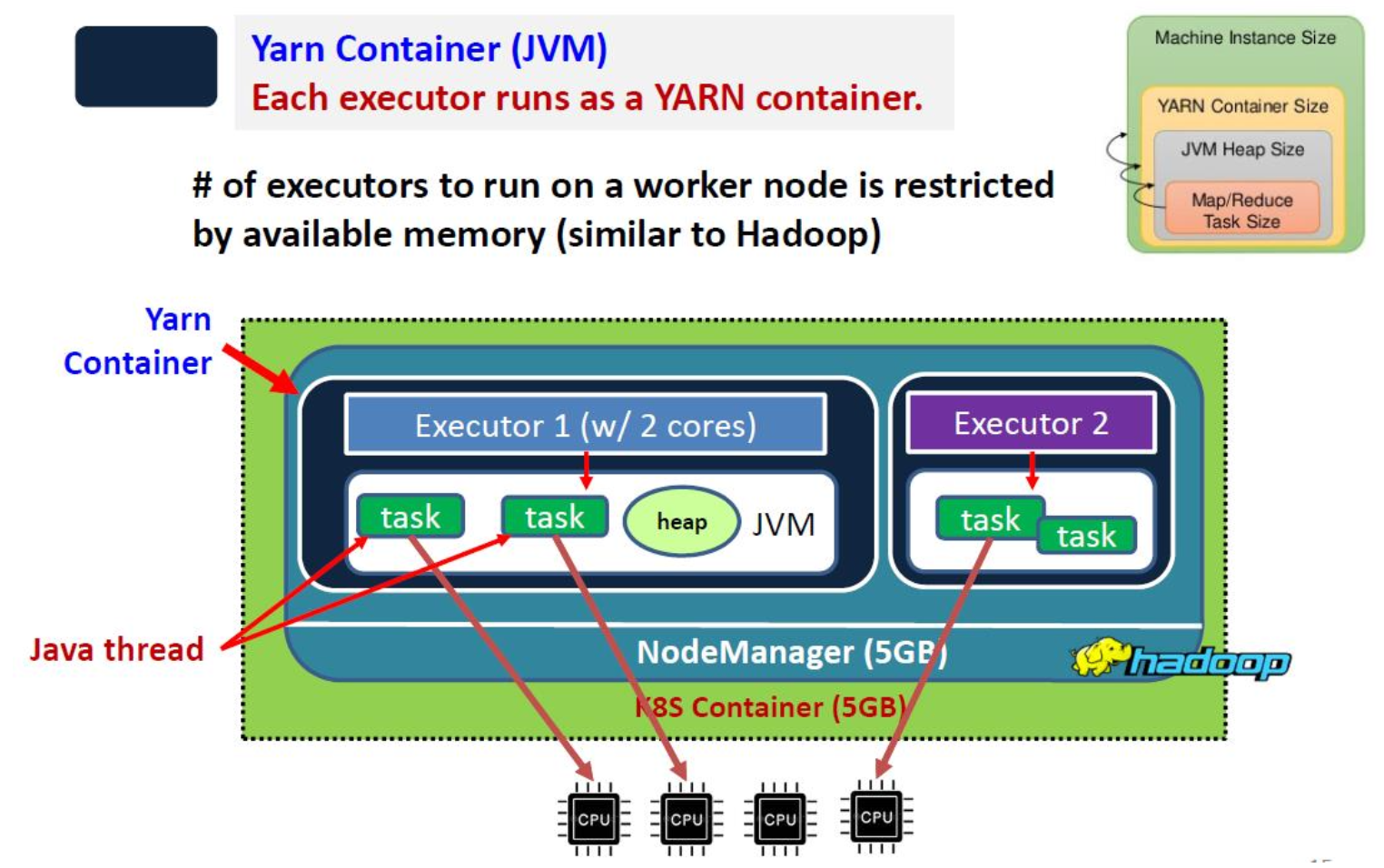
Run Schedule Tasks
Schedule Tasks to run on Executors
- 执行器启动一次,可被多个任务和所有后续任务使用
- 任务总数取决于 RDD 分区的数量
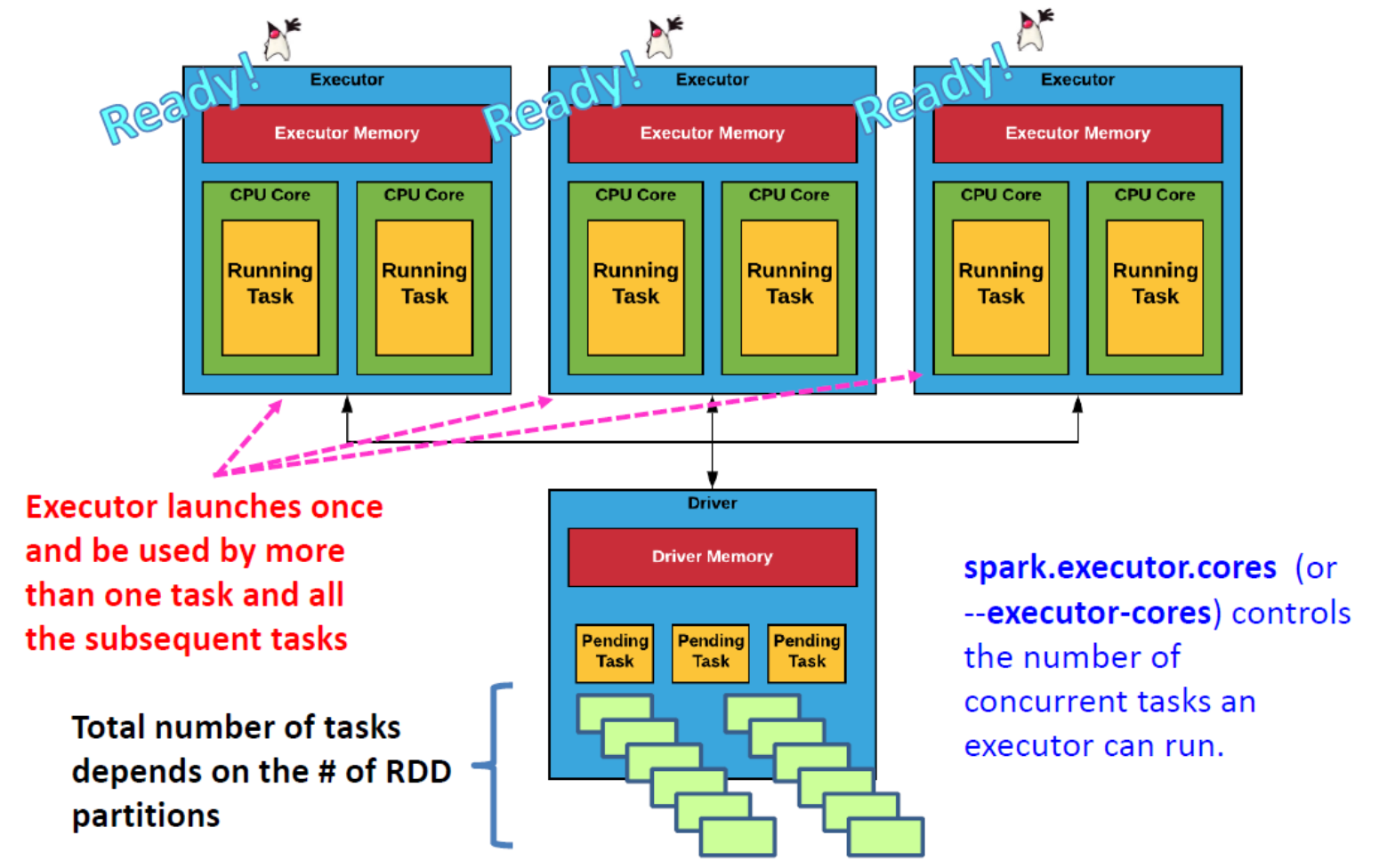
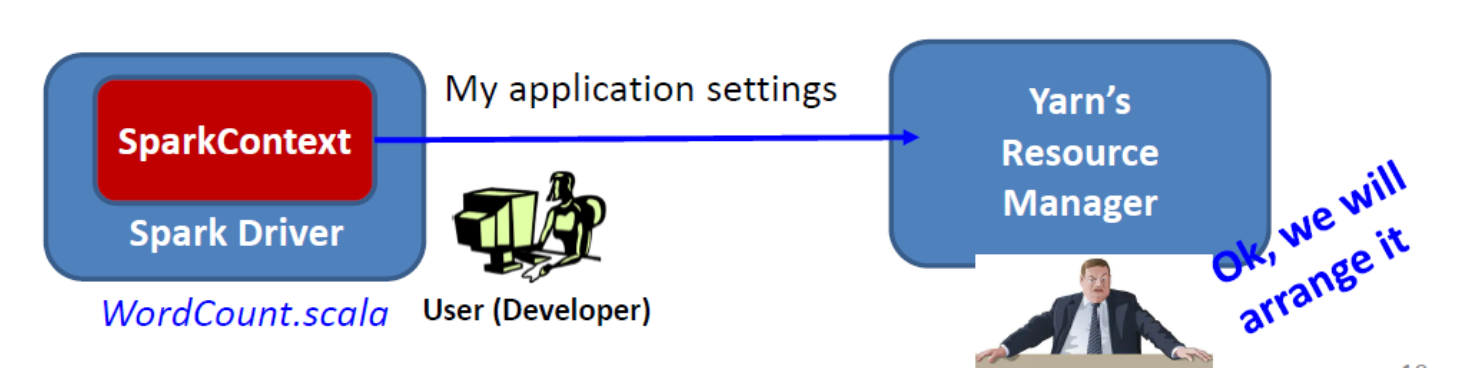
Spark Driver
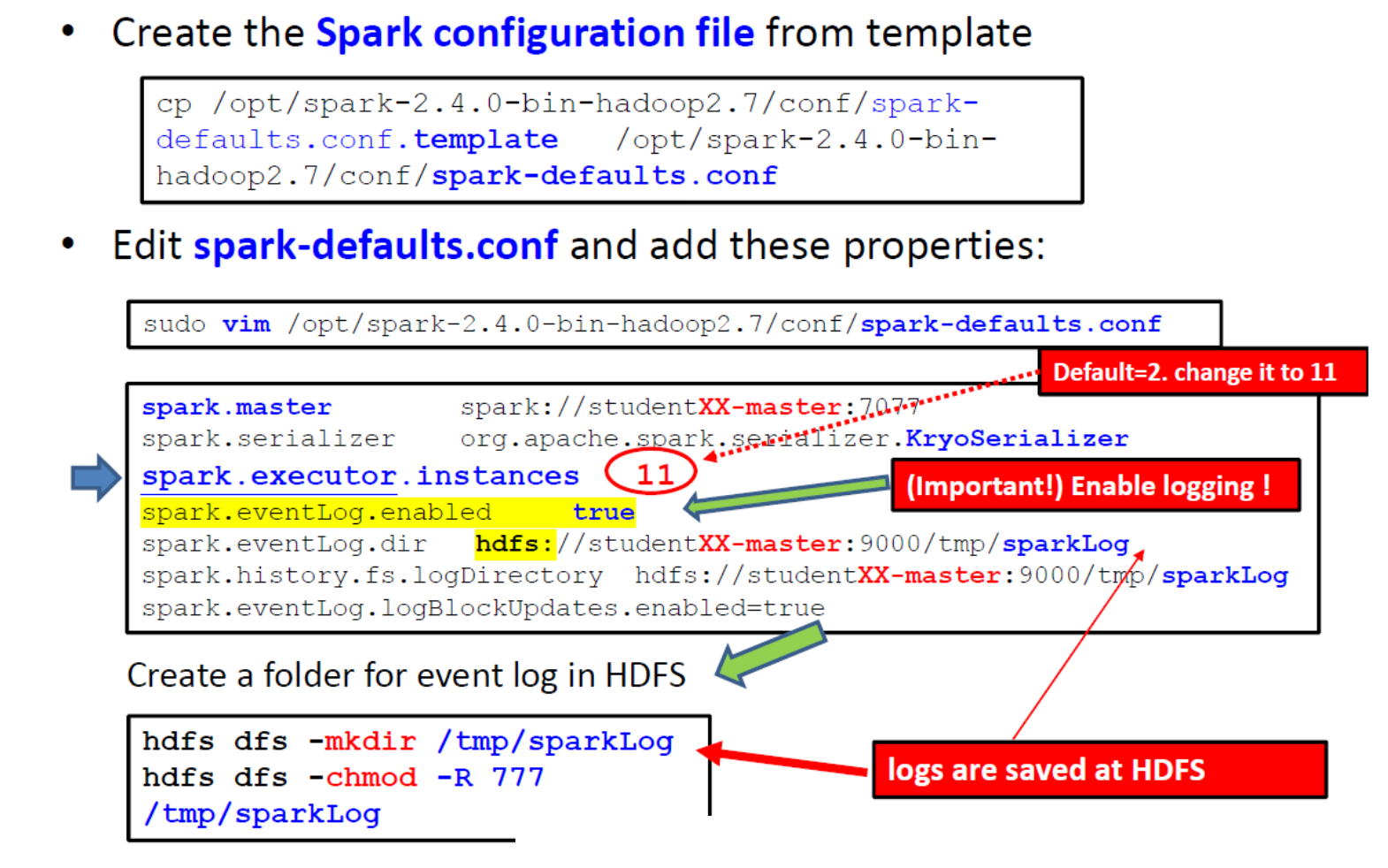
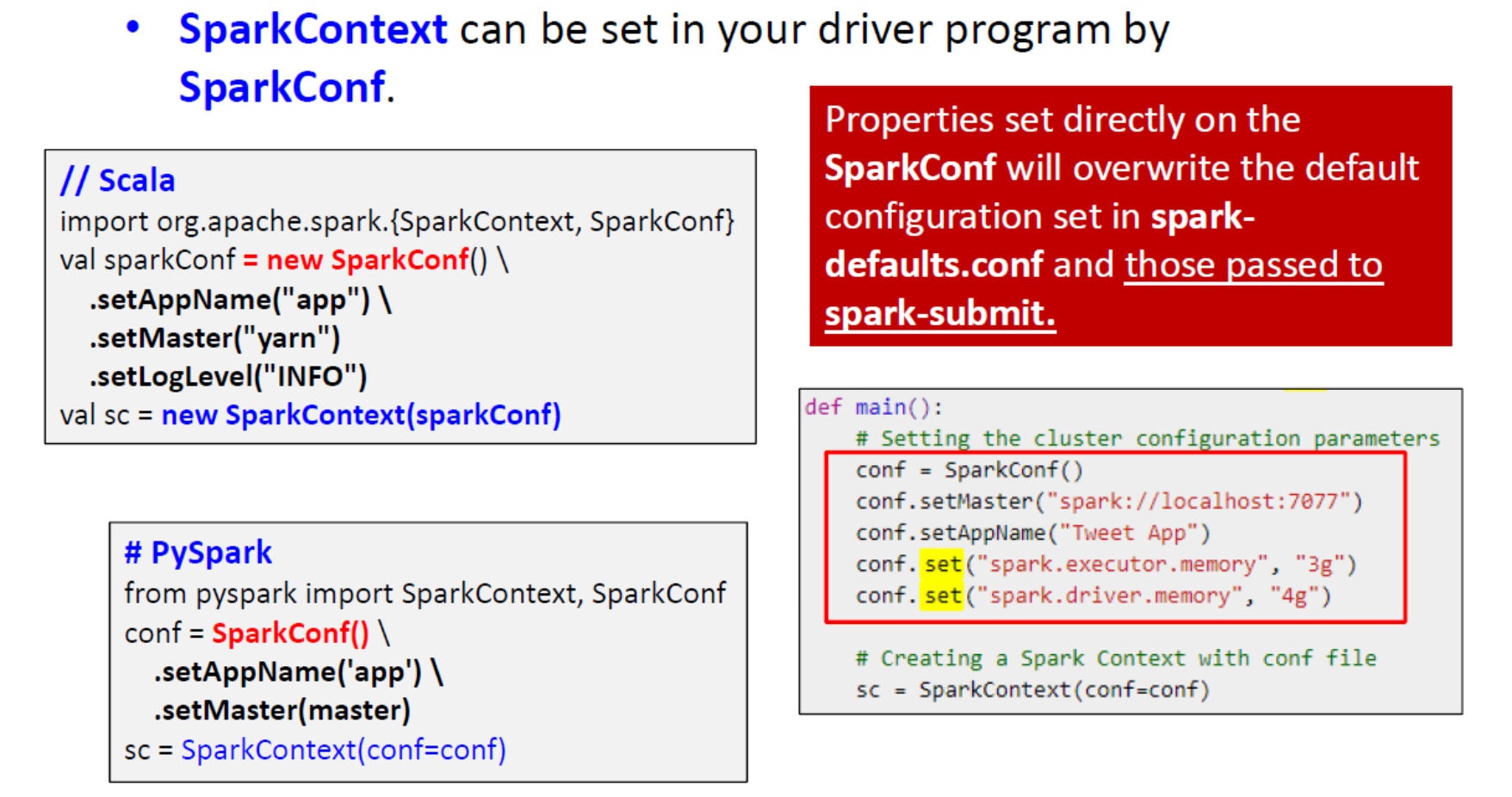
任何 Spark 驱动程序应用程序中最重要的步骤是生成 SparkContext。
- Spark Driver 程序使用 SparkContext 通过资源管理器(例如 Yarn)连接到集群。
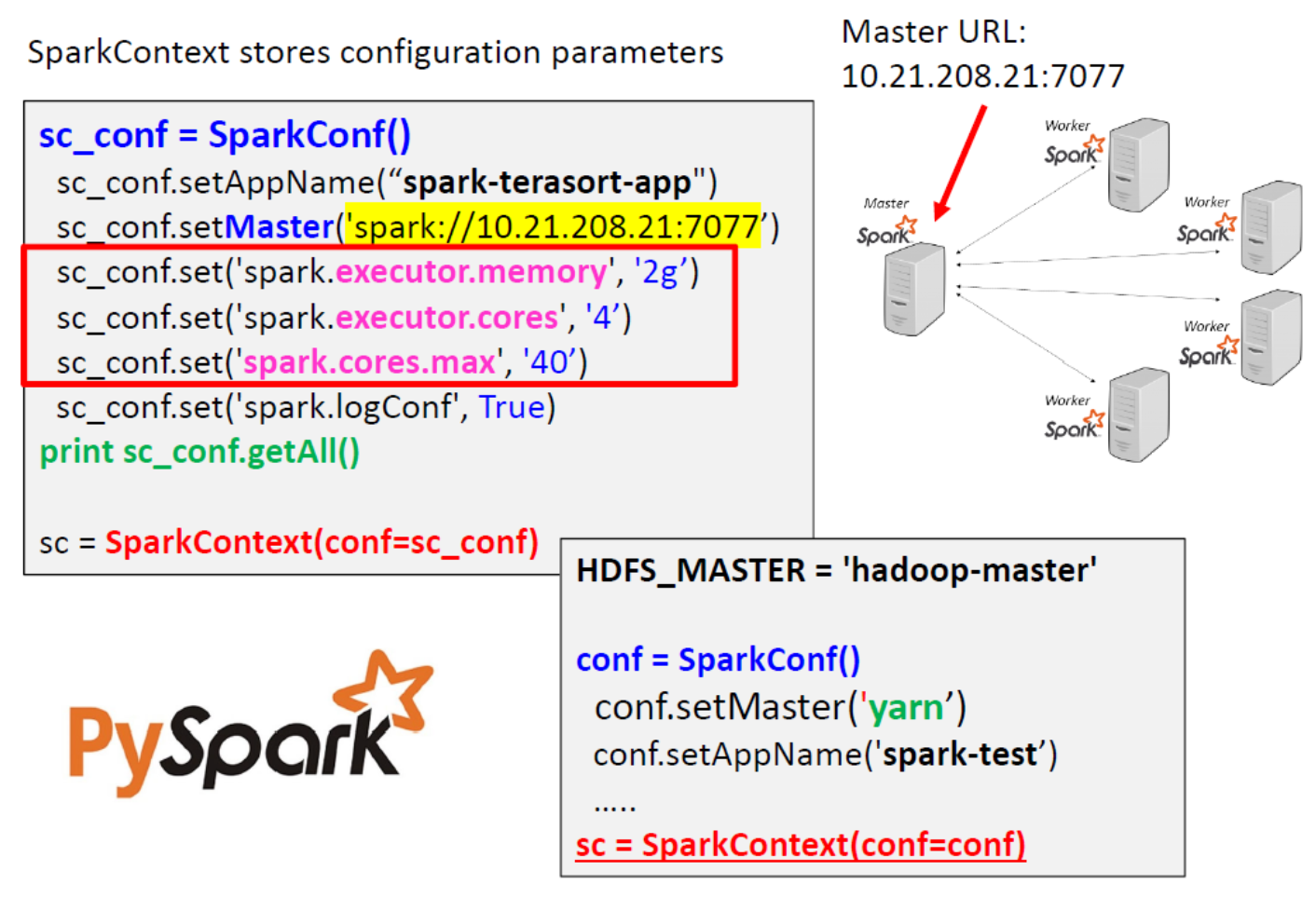
- SparkContext 存储配置参数:
- 例如,应用程序名称、集群的主 URL、资源请求(执行器数量、执行器内存/核心数)、...
SparkContext: PySpark Example
Cluster Managers
Spark Supported Cluster Managers
- Spark Standalone Mode
- 使用 Spark 自带的集群管理器。
- YARN - the resource manager since Hadoop 2.X.
- 更丰富的调度能力:FIFO、Capacity、Fair调度器。
- Kubernetes (> Spark 2.3)
- K8S 创建执行器 pod 来运行 Spark 应用程序,每个执行器一个 pod!
- Mesos - Deprecated as of Apache Spark 3.2.0
How to run

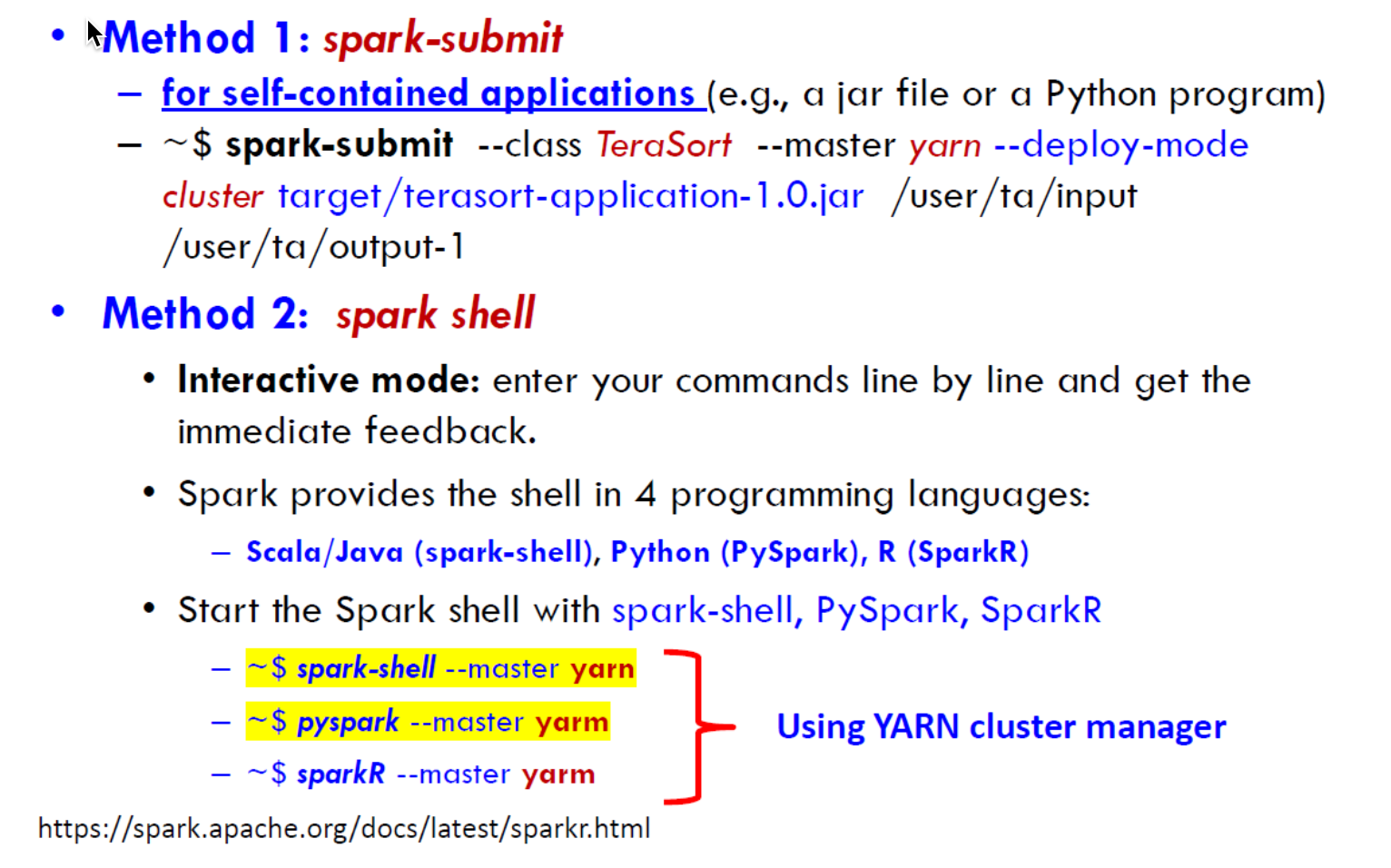
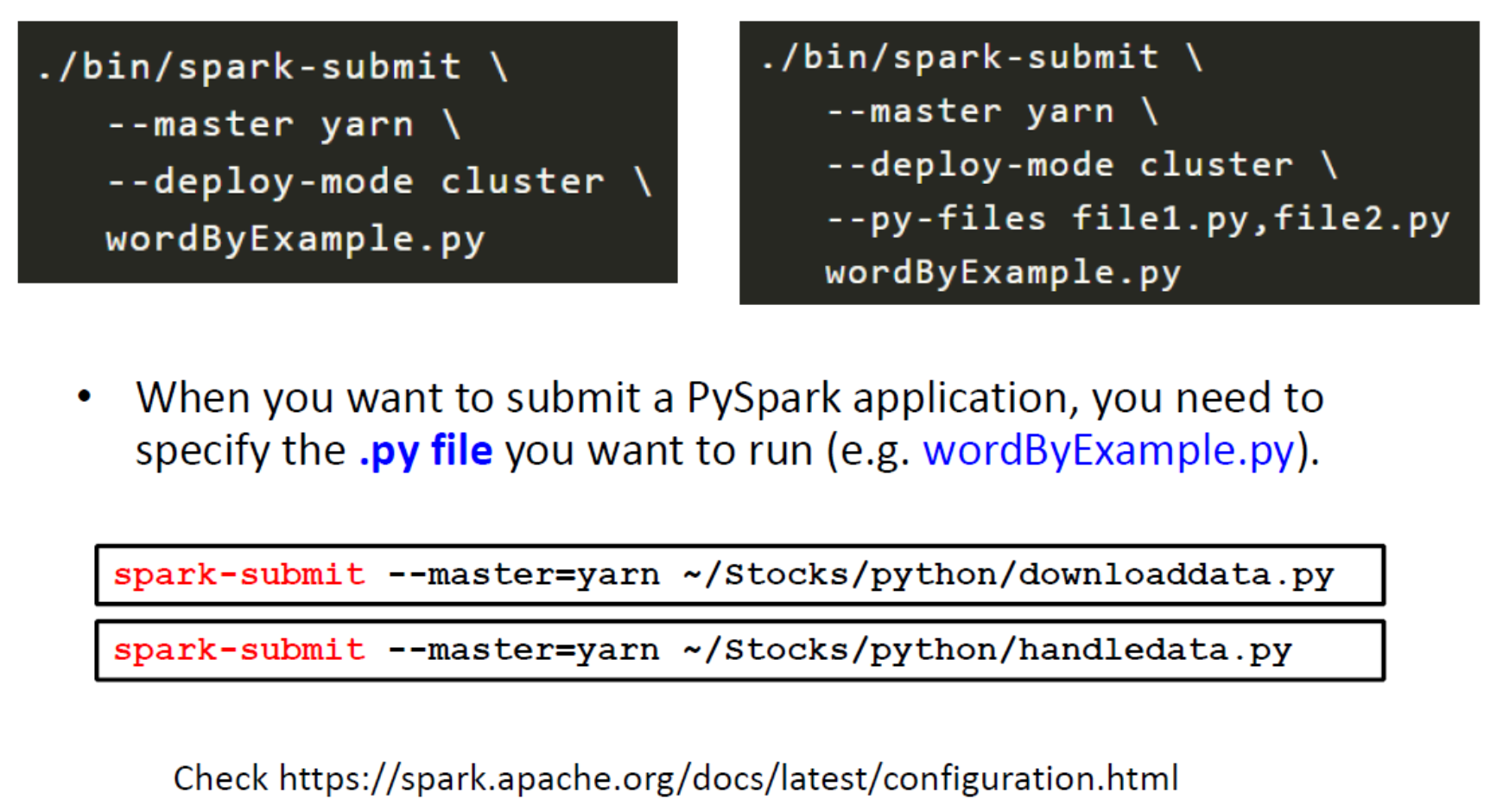
Method 1: Spark-Submit


Use spark-submit to run PySpark Application
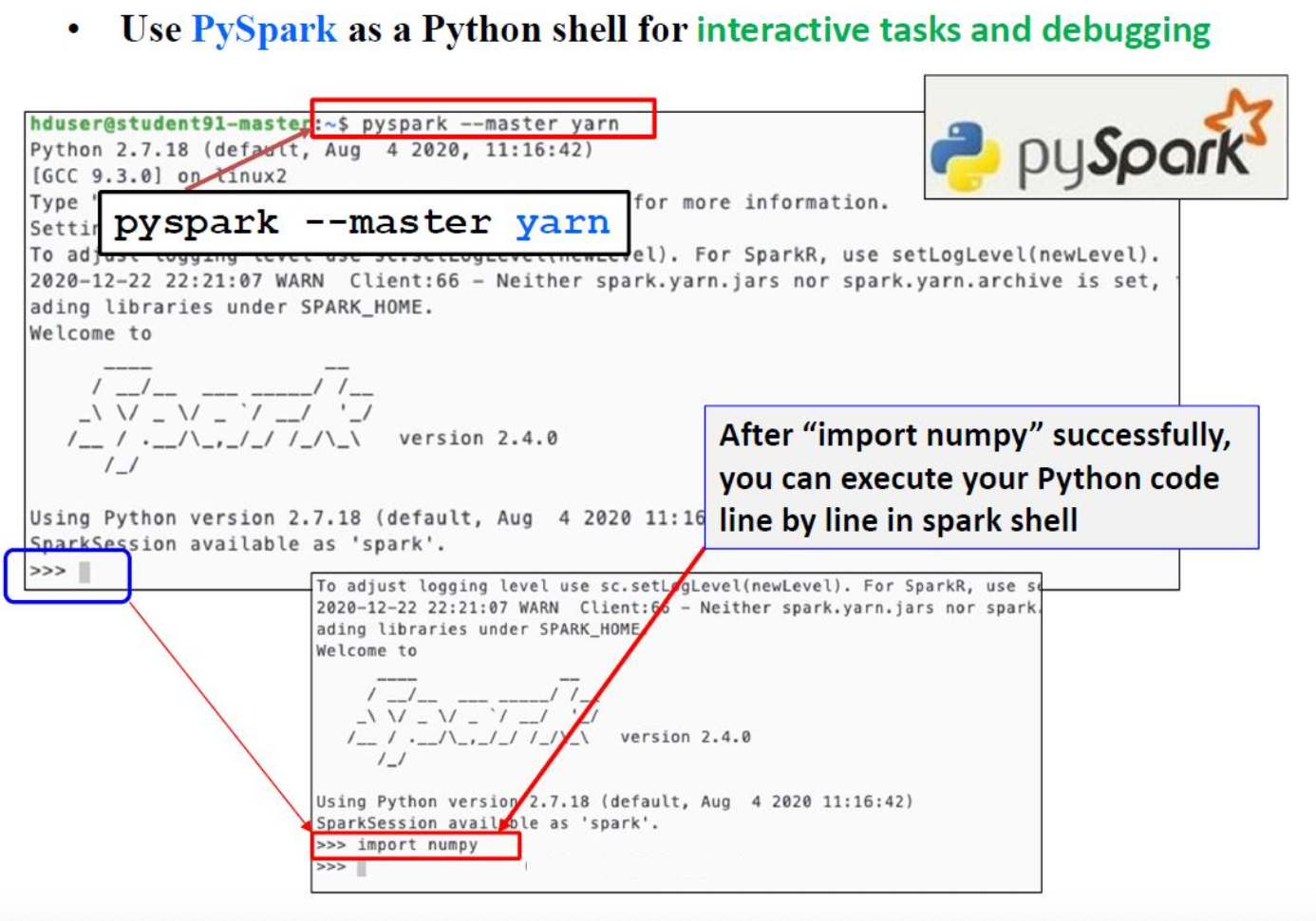
Method 2: spark-shell
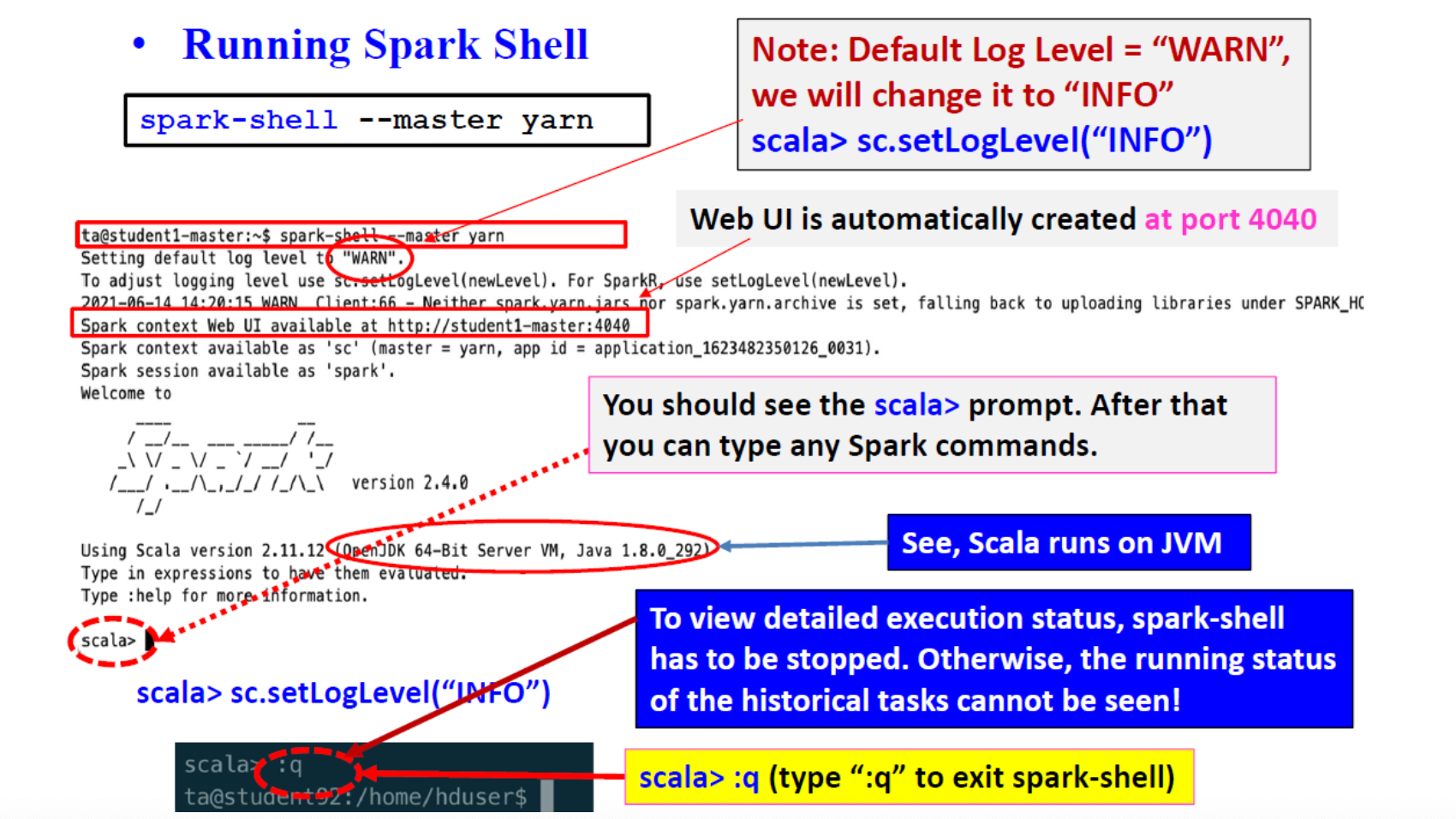
Use PySpark as a Python shell
Deploy Modes
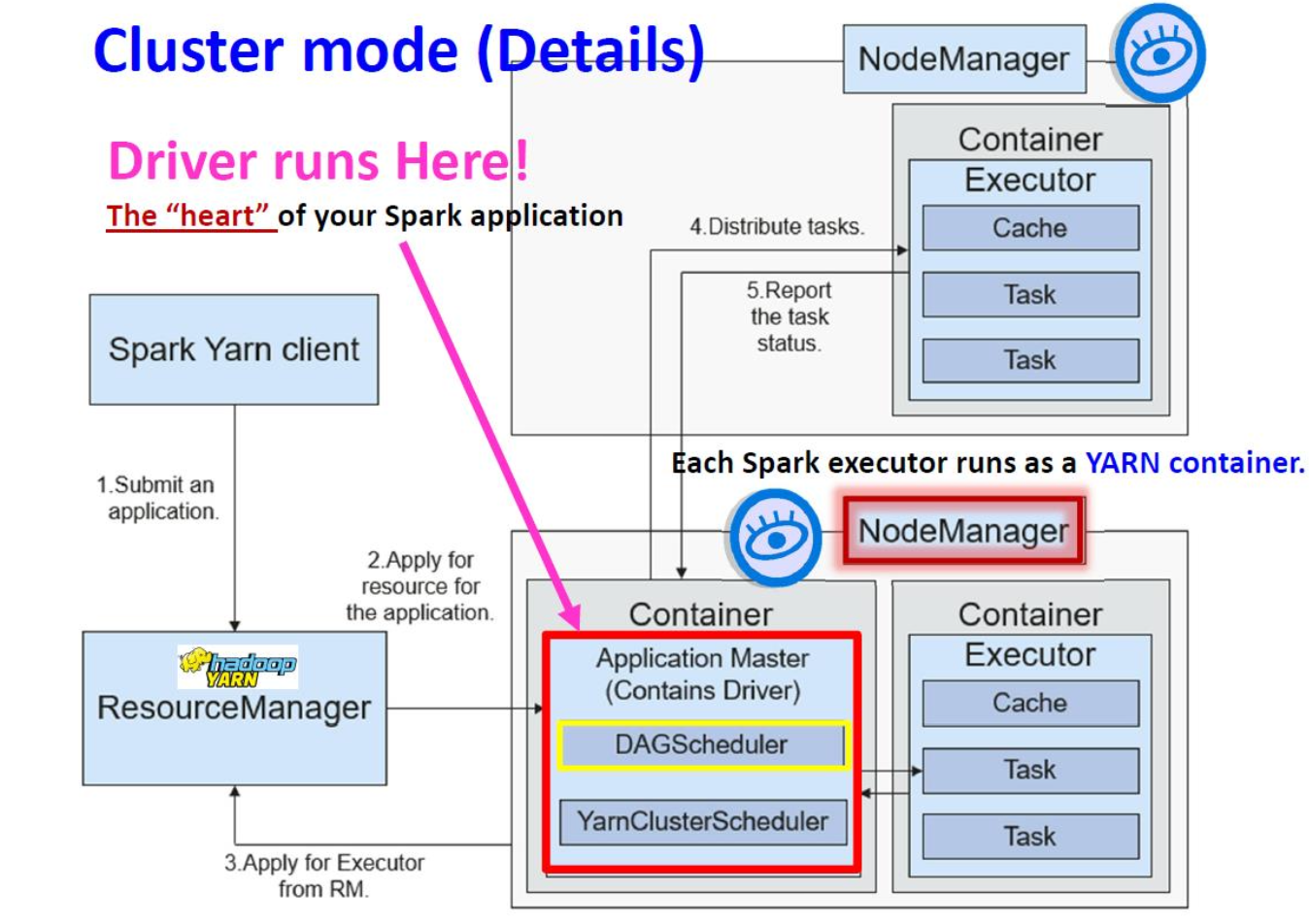
Spark Execution with Yarn: Cluster Mode
Client Mode
Spark 驱动程序在提交作业的主机上运行
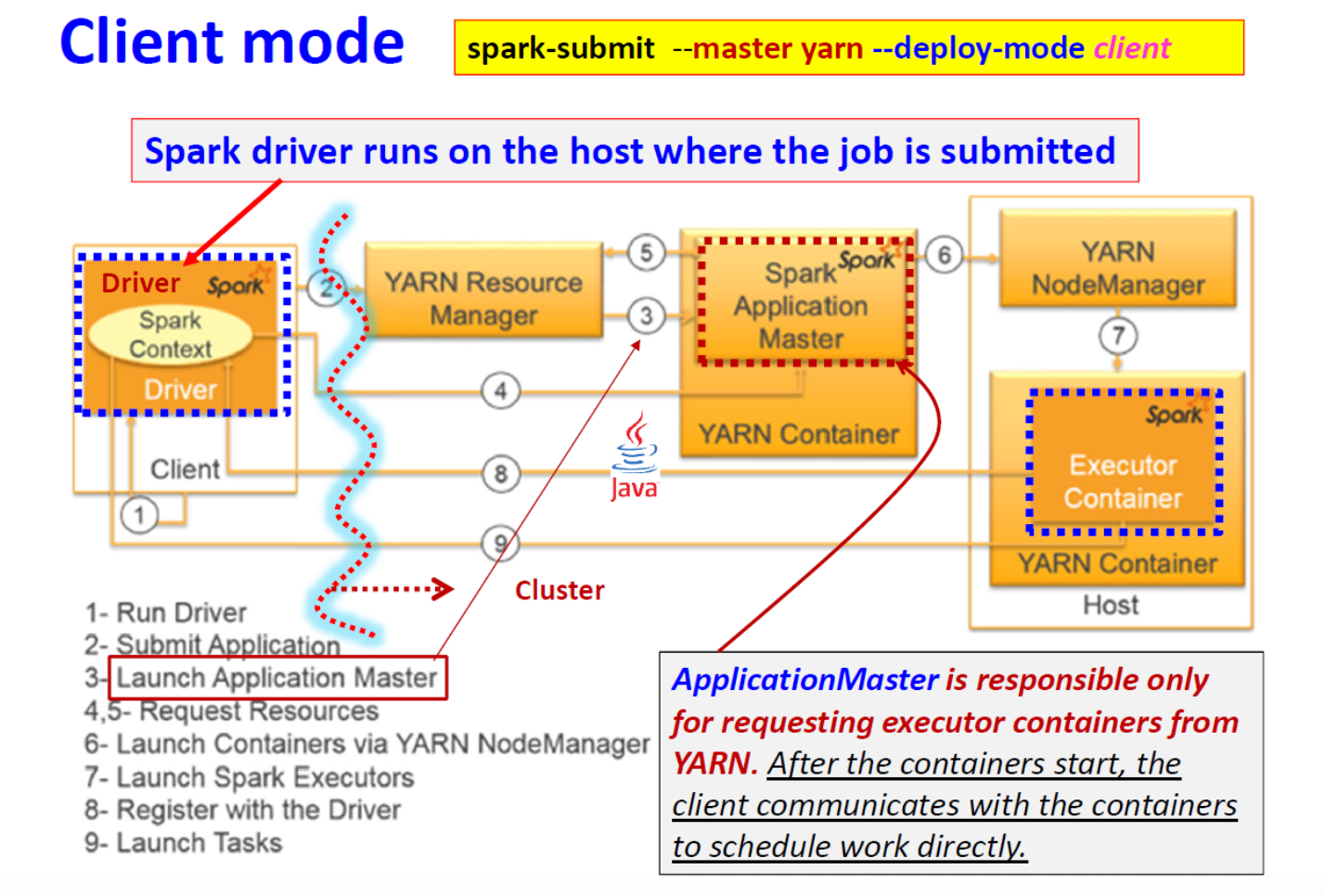
ApplicationMaster 只负责向 YARN 请求执行容器。容器启动后,客户端与容器通信,直接安排工作。
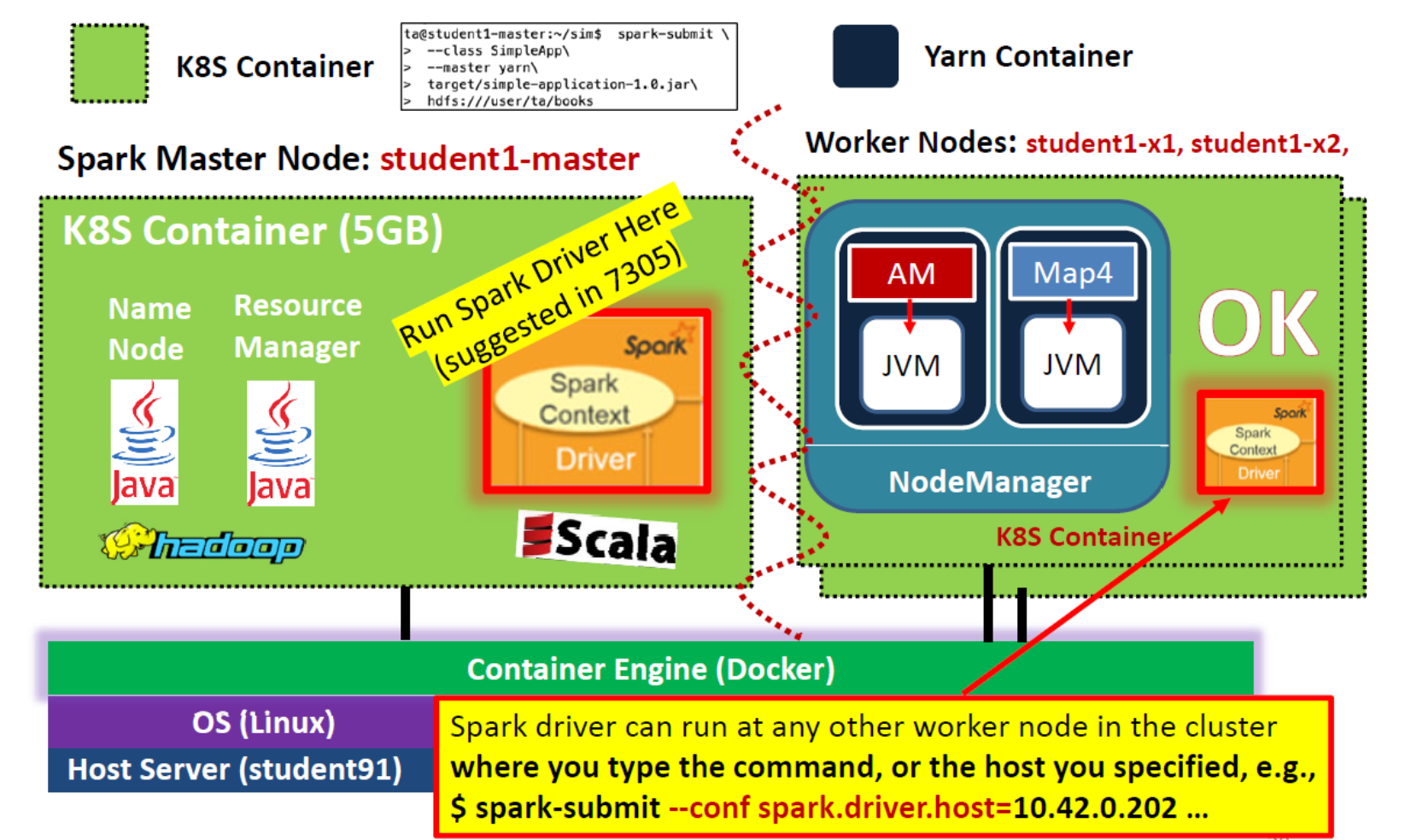
Cluster Mode vs. Client Mode
Client mode: (Interactive)
- 用于调试或希望以交互方式快速查看输出。
- 如果客户端不在群集中,则会遭受更高的延迟。
- 仍需要 ApplicationMaster(占用 1 个 Yarn 容器,但驱动程序代码不在其中运行)
Cluster mode: (Non-interactive)
- Used for applications in production.
- Spark Driver 和 Spark Executor 受到 YARN 自动故障恢复的监督。
- Not supported for spark-shell 和 PySpark.
View ApplicationMaster & Executor Processes at a Worker Node
ApplicationMaster 在 Spark 中的进程名称是 ExecutorLauncher。
