SARM: Sequential Analysis
SARM: Sequential Analysis
Mining Sequential Association Rules 是数据挖掘领域中的一种技术,用于从大量的序列数据中挖掘出有意义的模式和关系。这种技术在许多应用中都很有用,比如市场篮子分析、客户购买行为分析、网络日志分析、生物信息学中的基因和蛋白质序列分析等。
与传统的关联规则挖掘不同,序列关联规则挖掘关注的是在序列中的项目之间的时间或顺序关系。也就是说,它不仅仅是寻找经常一起出现的项目,而是寻找按特定顺序出现的项目。
简单来说,考虑这样一个例子:假设有一个零售商想要分析客户的购买记录,**以找出随着时间推移客户可能购买的产品序列。**他们可以使用序列关联规则挖掘来找到像“如果一个客户先买了 A,然后买了 B,那么他们很可能最后会买 C”这样的模式。
为了挖掘这些规则,研究者提出了许多算法,如Apriori-based、PrefixSpan、GSP(Generalized Sequential Patterns)等。这些算法首先识别频繁出现的序列模式,然后基于这些模式生成关联规则。
Example
- 客户通常会租借《星球大战》、《帝国反击战》和《绝地归来》
- HSI went “Up”, then “Level”, then “Up”, and then “Down”
- 客户阅读 "财经新闻",然后是 "头条新闻",最后是 "娱乐新闻"。
Frequent Sequences
什么是顺序模式「sequential pattern」挖掘?
Based on computing the frequent sequences (vs computing the frequent itemsets in non-sequential ARM)
Sequence consists of a list of itemset in temporal order 「按时间顺序」and is denoted as <s1, s2, ..., sn>, where si is the i-th itemset (not item!) in the sequence.
Objectives of SPM: Given a database D of customer transactions, the problem of mining sequential patterns is to find all sequential patterns with user-specified minimum support
Customer Sequence: 客户的所有交易是一个按交易时间递增排序的序列。
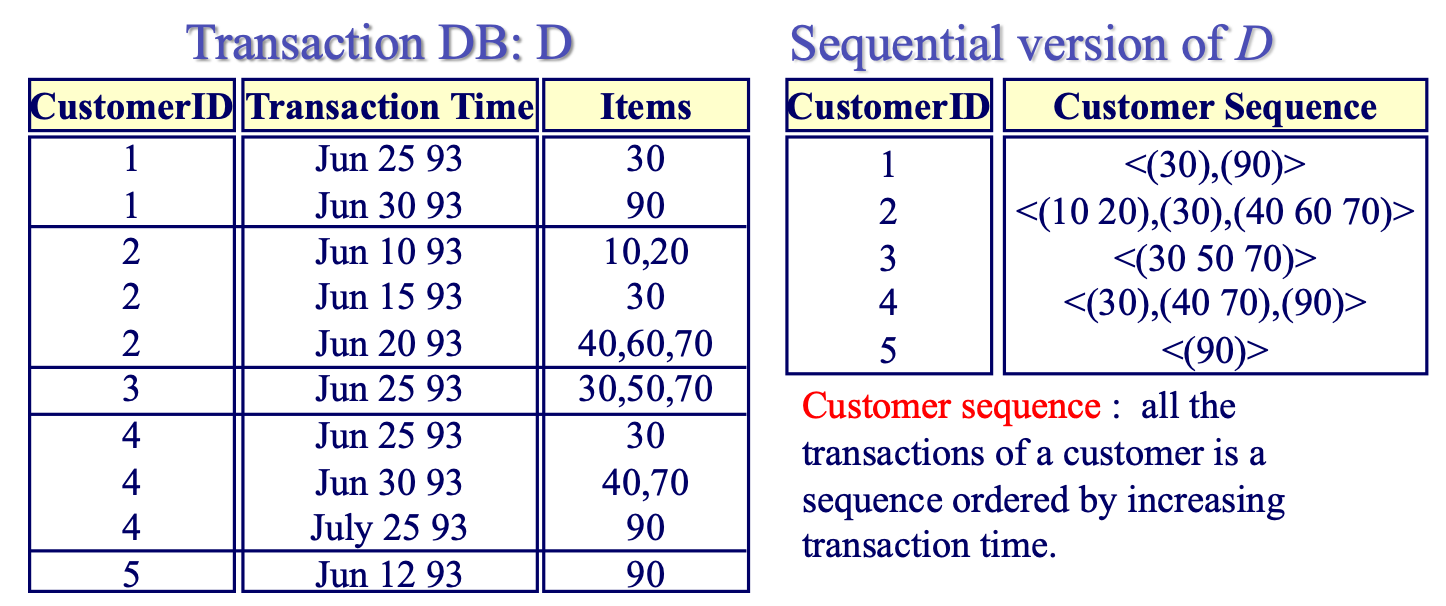
表格表示了如下的客户购买序列:
- 客户1: 先买了商品30,然后在之后的事务中买了商品90。
- 客户2: 先买了商品10和20,然后买了商品30,接着在之后的事务中买了商品40、60和70。
- 客户3: 在一个事务中买了商品30、50和70。
- 客户4: 先买了商品30,然后在之后的事务中买了商品40和70,接着在另一个事务中买了商品90。
- 客户5: 只在一个事务中买了商品90。
给定的最小支持度是25%,这意味着为了被视为频繁的序列,一个序列必须至少被5名客户中的25%,即至少2名客户所支持。
从上面的数据中,我们可以得到以下频繁序列:
- <(30),(90)>: 客户1和客户4都有这个序列,因此支持度是2/5 = 40% > 25%。
- < (30),(90) > 序列的意思是有至少25%的客户先购买了商品30,然后在之后的事务中购买了商品90。
- <(30),(40 70)>: 客户2和客户4都有这个序列,因此支持度是2/5 = 40% > 25%。
所以,这两个序列都是频繁的。
Mining Steps
从事务数据库中提取频繁序列:
- 排序阶段「Sort Phase」: 将数据库按照客户ID进行排序,若有相同的客户ID,则按照交易时间排序。
- 频繁阶段「Frequent Itemset Phase」: 使用 Apriori 算法找到所有频繁的商品集合。
- 转换阶段「Transformation Phase」: 将每个客户的交易序列转换为频繁商品集合的表示。
- 序列阶段「Sequence Phase」: 使用上面的频繁商品集合找到所需的序列。具体的算法可能是AprioriAll、AprioriSome或DynamicSome(具体请参阅原始论文)。
- 最大化阶段「Maximal Phase」 (可选): 在频繁序列集合中找到最大的序列。
Transformation Phase
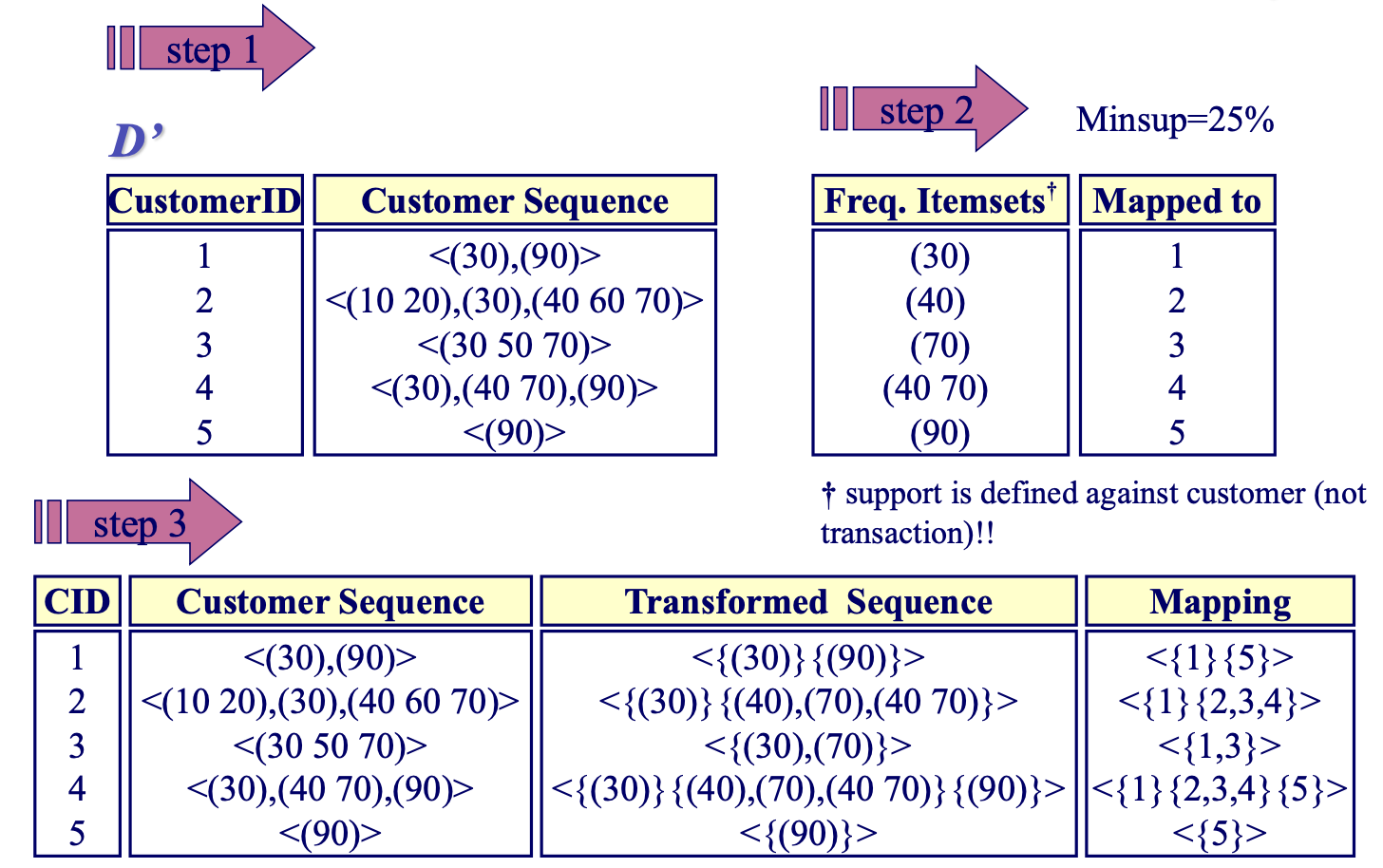
注意
需要注意的是 D' 表是 基于客户的表,而不是基于事务。这是因为在序列模式挖掘中,我们更关心的是多少个不同的客户遵循某个特定的购买模式,而不是这个模式在多少个不同的事务中出现。
如何从表1获得表2
计算每个商品的支持度:
- 商品30: 有3位客户购买了商品30(客户1、客户2和客户3),所以它的支持度是3/5 = 60%。
- 商品90: 有3位客户购买了商品90(客户1、客户4和客户5),所以它的支持度是3/5 = 60%。
- 商品10: 只有客户2购买了商品10,所以支持度是1/5 = 20%。
- 商品20: 同样,只有客户2购买了商品20,所以支持度是1/5 = 20%。
- 商品40: 有2位客户购买了商品40(客户2和客户4),所以它的支持度是2/5 = 40%。
- 商品50: 只有客户3购买了商品50,所以支持度是1/5 = 20%。
- 商品60: 只有客户2购买了商品60,所以支持度是1/5 = 20%。
- 商品70: 有3位客户购买了商品70(客户2、客户3和客户4),所以它的支持度是3/5 = 60%。
过滤小于最小支持度的商品: 由于 Minsup=25%,我们只保留那些支持度大于或等于25%的商品。因此,我们保留了商品30、90、40和70。
映射频繁商品集:
| Mapped to | Freq. Itemsets † |
|---|---|
| 1 | <(30)> |
| 2 | <(40)> |
| 3 | <(70)> |
| 4 | <(40),(90)> |
| 5 | <(90)> |
AprioriAll Algorithm
AprioriAll 算法的目标是找到频繁序列,即在数据中经常出现的顺序模式。

AprioriAll算法的基本原理是:任何非频繁的子序列都不会是频繁的序列。因此,该算法从长度为1的序列开始,逐渐增加序列的长度,只考虑那些子序列已经被证明是频繁的序列。
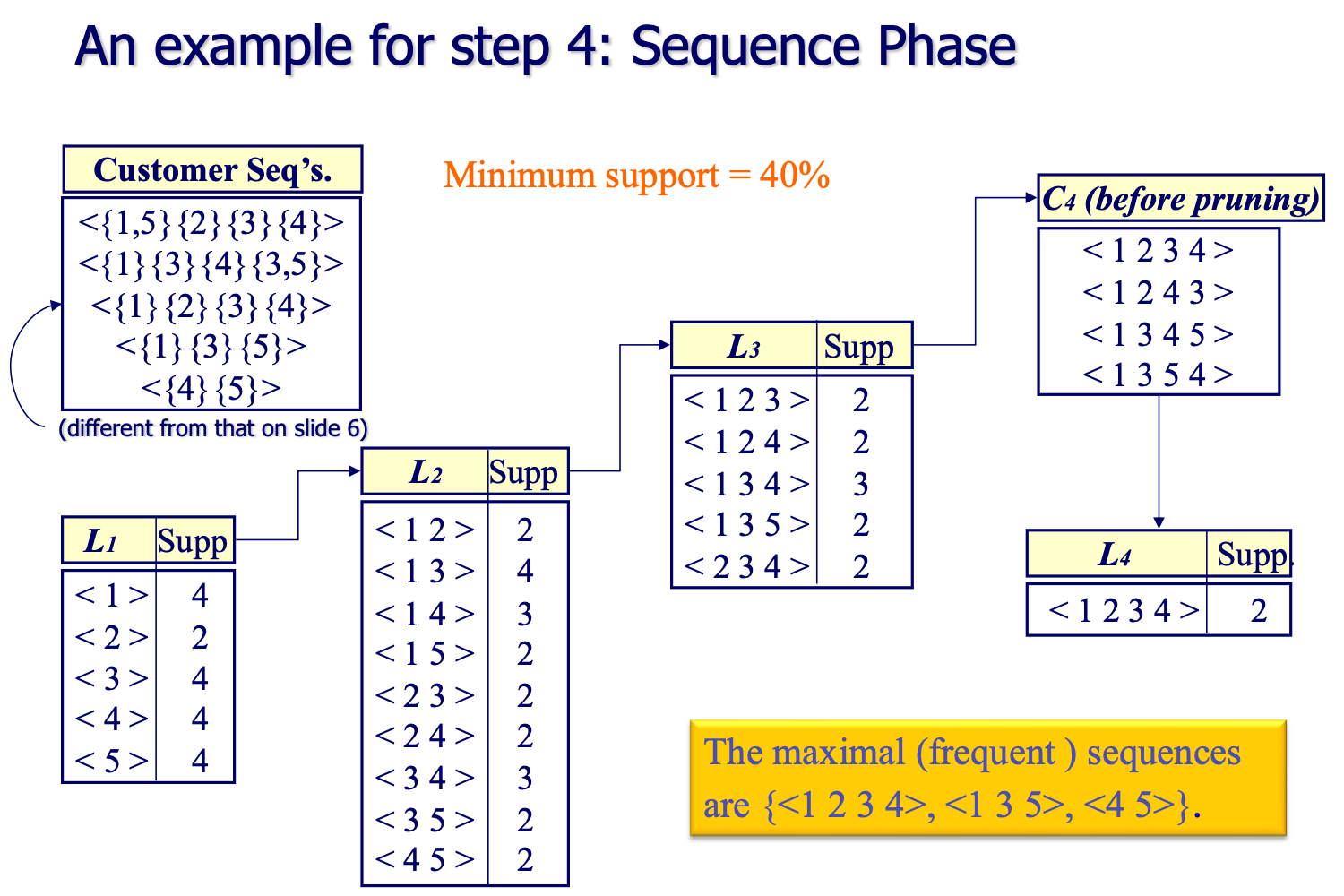
Generate Candidate Sequences

Example
- L3 =
{abc, abd, acd, ace, bcd} - Self-joining:
L3*L3abcdandabdcfromabcandabdacdeandacedfromacdandace
- Pruning:
abdcis removed becauseadc/bdcis not in L3acdeis removed becauseade/cdeis not in L3acedis removed becauseaed/cedis not in L3
- C4=
{abcd}
Maximal Phase
Essential Definitions for Phase 5: Maximal Phase
如果一个序列是频繁的,并且它没有任何频繁的超集,则该序列称为最大频繁序列。
Consider the examples:
<(3),(45),(8)>is contained in<(7),(38),(9),(456),(8)>? YES<(3),(5)>is contained in<(35)>? NO
Forming Rules
Again, the user specified confidence is used by the rule generation step to qualify the strength of the sequential association rules.
规则生成步骤相当简单,比如
- <1234> will form1→234,12→34, 123→4
- 但是,13→24,124→3, 等无法形成,因为时间顺序被扭曲了!!