More about AR
More about AR
Multi-Dimensional Association
- Single-dimensional rules: buys(X, “milk”) -> buys(X, “bread”)
- Multi-dimensional rules: >=2 dimensions or predicates
- Inter-dimension association rules (no repeated predicates): age(X,”19-25”) ∧ occupation(X,“student”) -> buys(X,“coke”)
- hybrid-dimension association rules (repeated predicates): age(X,”19-25”) ∧ buys(X, “popcorn”) -> buys(X, “coke”)
- Categorical Attributes: 可能值的数量有限,值之间没有顺序
- Quantitative Attributes: 数字,值之间的隐式排序
Mining Quantitative Associations
可根据如何处理年龄或工资等数字属性对技术进行分类
- 基于预定义概念层次结构的静态离散化:这是一个将连续数据转换为离散数据的方法。所谓“预定义概念层次结构”指的是预先定义的分类。例如,年龄可以分为预先定义的几个区间:儿童(0-12岁)、青少年(13-18岁)、成年(19-60岁)和老年(>60岁)。
- 基于数据分布的动态离散化:与上述静态方法不同,这种方法并不依赖于预先定义的区间,而是根据数据的分布特性进行离散化。例如,可以使用四分位数将数据分为四个区间。
例子:考虑一个公司的员工工资数据。如果工资数据的分布是在30,000到100,000之间,并且中位数是50,000,那么可以根据这个中位数或其他分位数将工资数据离散化为“低工资”和“高工资”等类别。
聚类:基于距离的关联 -> 一维聚类然后关联:
这是一个更复杂的方法,涉及到先对数据进行聚类,然后在聚类结果上进行关联分析。这里的“基于距离的关联”指的是使用距离度量(例如欧几里得距离)来进行聚类。
例子:考虑一个电商网站的用户浏览记录,其中记录了用户浏览商品的价格。现在,如果要分析用户的浏览习惯,可以首先基于商品价格进行一维聚类,将价格相近的商品归为一类。然后,对这些聚类结果进行关联分析,以找出哪些价格区间的商品更受用户欢迎。
Quantitative Association Rules
是在关联规则挖掘中对数值型属性进行处理的一个研究方向。关联规则挖掘通常处理的是分类数据,但在现实生活中,许多数据都是数值型的。为了在这些数值型数据上挖掘关联规则,研究者提出了多种方法。
提示
这表示Quantitative Association Rules的概念首次在1997年的ICDE会议上由Lent、Swami和Widom提出。
数值属性动态离散化
这个方法的主要目标是根据数据自身的特点动态地将数值数据转化为离散类别,以使得挖掘出的关联规则的可信度或紧凑度达到最大。这与之前讨论的基于数据分布的动态离散化类似。
例子:在超市销售数据中,可能想知道哪些产品的销售价格会影响另一种产品的购买。例如,如果牛奶的价格在$3-$4范围内,面包的销量可能增加。这里,$3-$4就是牛奶价格的一个离散化的区间。
2-D quantitative association rules
Aquan1 ∧ Aquan2 -> Acat: 这是一个涉及两个数值属性(Aquan1和Aquan2)和一个分类属性(Acat)的关联规则格式。当Aquan1和Aquan2满足某些条件时,Acat也可能满足某个特定类别。
例子:考虑房地产数据。可能发现,当“占地面积”在50-100平方米并且“价格”在200,000-300,000元之间时,大多数房屋的“类型”是“公寓”。
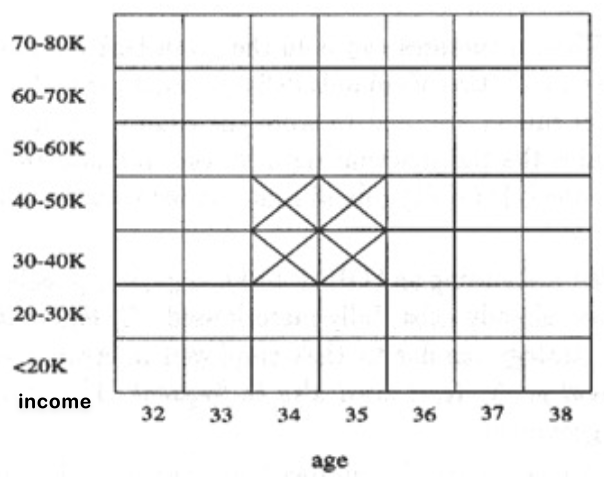
Cluster adjacent association Rules to form general rules using a 2-D grid
该方法是将邻近的关联规则聚合以形成更一般的规则。使用2-D网格来识别和组合相似或邻近的规则。
例子:考虑一个简单的2-D格子,表示年龄和收入。有两个关联规则:当年龄在30-40岁并且收入在$50k-$70k时,人们更喜欢购买A品牌的车;当年龄在35-45岁并且收入在$60k-$80k时,人们更喜欢购买A品牌的车。可以看到,这两个规则在2-D网格上是邻近的。可以将它们聚合为一个更一般的规则:当年龄在30-45岁并且收入在$50k-$80k时,人们更喜欢购买A品牌的车。
Another Example: age(X, “34-35”) ∧ income(X, “30-50K”) -> buys(X, “high resolution TV”)
Spatial Association Analysis
空间数据与传统的交易数据不同,它包含位置信息。空间关联规则分析的目标是发现空间数据中的模式和关系。
空间关联分析,是关联规则分析在地理空间数据上的应用。
Spatial association rule: A -> B [s%, c%]: 表示一个空间关联规则的格式。其中 A 和 B 是空间或非空间谓词的集合,s% 是规则的支持度,而 c% 是规则的置信度。
- A and B: 这是规则的前件和后件。它们包含一个或多个谓词,这些谓词描述了某种空间关系或属性。
- Topological relations: 这些是地理对象之间的空间关系,例如相交(intersects)、重叠(overlaps)和不相交(disjoint)。
- Spatial orientations: 描述了地理对象之间的方向关系,例如左边(left_of)、西边(west_of)和下面(under)。
- Distance information: 描述了地理对象之间的距离关系,例如靠近(close_to)和在某距离内(within_distance)。
- s% is the support: 支持度表示规则涉及的事务在所有事务中的百分比。
- c% is the confidence: 置信度表示给定前件 A 发生时后件 B 发生的条件概率。
Examples:
- is_a(x, large_town) ^ intersect(x, highway) -> adjacent_to(x, water) [7%, 85%]
- is_a(x, large_town) ^adjacent_to(x, georgia_strait) -> close_to(x, u.s.a.) [1%, 78%]
Main Contribution
关联规则挖掘的主要贡献是什么?关联规则挖掘基本上是一种统计技术,基本上不包含太多的智能!
然而,它为超大型数据库应用程序提供了可行(或高效的数据库)解决方案!它充分利用了有限的 RAM 来跟踪所谓的大量候选项集
从根本上说,关联规则挖掘的主要贡献在于它易于灵活应用。它几乎可以应用于所有应用程序(或您拥有的任何数据库)!
Application
- 您的应用程序中的事务是什么?
- 您的应用程序中的项目是什么?
- 您的应用程序中的客户是什么?(用于顺序关联规则挖掘)
作为一名数据科学家,你需要有足够的创造力来应对所有这些!