Feature Engineering
Feature Engineering
“归根结底,有些机器学习项目成功,有些则失败。是什么造成了差异?最重要的因素显然是所使用的 Feature”。
Pedro Domingos 教授指出,FE 对于数据挖掘项目的成功至关重要。
What Is
What is feature engineering (FE) about?
什么是特征,以及为什么我们需要对其进行工程设计?
- 机器学习和数据挖掘算法使用一些输入数据(包括特征)来创建输出结果
- Goals of FE:
- 准备符合机器学习算法要求的适当输入数据集。
- 提高机器学习模型的性能
《福布斯》的一项调查显示,数据科学家 80% 的时间都花在数据准备上
Feature Engineering-Science or Art
Feature Engineering is the process of selecting and extracting useful, predictive signals from data.
例如,下面的案例中
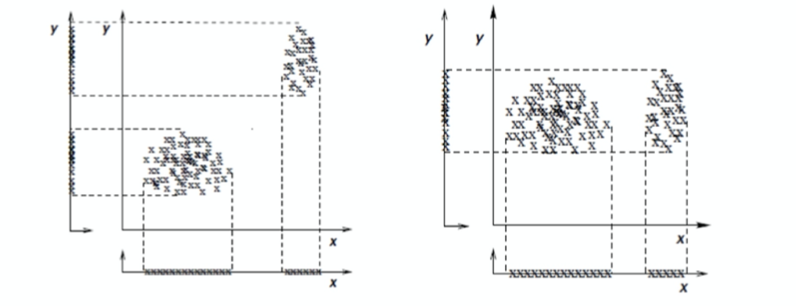
- 冗余特征「redundant feature」示例(左:特征 y 提供了与 x 相同的信息)
- 和无关特征「irrelevant feature」示例(右:特征 y 无法区分 x 所定义的聚类)
您如何设想在以下网络安全示例(监控欺诈活动)中使用 day-of-the-week feature?
Why Need
- 有些机器学习库不支持缺失值或字符串作为输入,例如 Scikit-learn
- 有些机器学习模型对特征的大小很敏感
- 有些算法对异常值很敏感
- 有些变量的原始格式几乎不提供任何信息,例如日期
- 通常情况下,变量预处理能让我们捕捉到更多信息,从而提高算法性能!
- 通常情况下,变量组合比单独的变量更具预测性,例如一组变量的总和或平均值。
- 有些变量包含交易信息,提供有时间戳的数据,我们可能希望将它们汇总到静态视图中。
More reasons behind...
- The most important factor of ML/DM project is the features used.
- 如果有很多独立的特征,而且每个特征都与预测的类别有很好的相关性,那么学习就很容易。
- 反之,如果类别是一个非常复杂的特征函数,则可能无法学习。
- ML/DM 通常是最快的部分,但这是因为我们已经掌握得相当好了 -> 特征工程比较困难,因为它是针对特定领域的,而学习器(ML/DM 模型)在很大程度上是通用的。
如今,通常的做法是自动生成大量候选特征,并通过(比如)与预测类别相关的信息增益来选择最佳特征。
- 需要注意的是,那些单独看起来无关紧要的特征,在组合起来后可能会变得相关。
- 另一方面,使用大量特征运行学习器来找出哪些特征组合起来有用,可能会耗费太多时间,或导致过度拟合。
Yet some final comments about FE -> 更多数据胜过更聪明的算法
人工智能研究人员主要关注的是创建更好的学习算法,但实际上,通往成功的最快途径往往是获取更多数据。
不过,这也带来了另一个问题:可扩展性 「scalability」。
- 在大多数计算机科学领域,时间和内存是两个主要的有限资源。在 ML 和 DM 中,还有第三个限制:训练数据。-> Data is the King!
- 首先尝试较简单的算法/模型,因为较复杂的算法/模型通常较难使用(在获得良好结果之前需要进行更多调整)。
What to Learn
- Missing data imputation 「缺失数据插补」
- Categorical variable encoding (e.g. one-hot encoding: link1, link2) 「分类变量编码(例如 one-hot 编码:link1、link2)」
- Numerical variable transformation 「数值变量转换」
- Discretization「离散化」
- Engineering of datetime variables「日期时间变量工程」
- Engineering of coordinates — GIS data「坐标工程——GIS数据」
- Feature extraction from text「从文本中提取特征」
- Feature extraction from images「从图像中提取特征」
- Feature extraction from time series「从时间序列中提取特征」
- New feature creation by combining existing variables「通过组合现有变量创建新功能」
Feature Encoding Methods
- 将分类特征「categorical features」转化为数字特征「numeric features」,提供更精细「fine-grained」的信息
- 有助于明确捕捉特征值之间的非线性关系「non-linear relationships」和相互作用「interactions」
大多数机器学习工具只接受数字作为输入,例如 XGBoost、gbm、glmnet、libsvm、liblinear 等。
Labeled encoding, one-hot encoding, frequency encoding, etc.
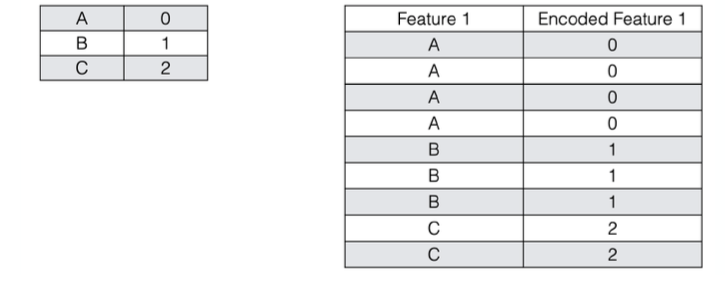
Labeled Encoding
- 将类别解释为有序整数(大部分是错误的)
- Python scikit-learn:LabelEncoder
- Ok for tree-based methods「适用于基于树的方法」
Feature Encoding Methods
One-hot Encoding
- 将类别转换为单独的二进制(0 或 1)特征
- Python scikit-learn:DictVectorizer, OneHotEncoder

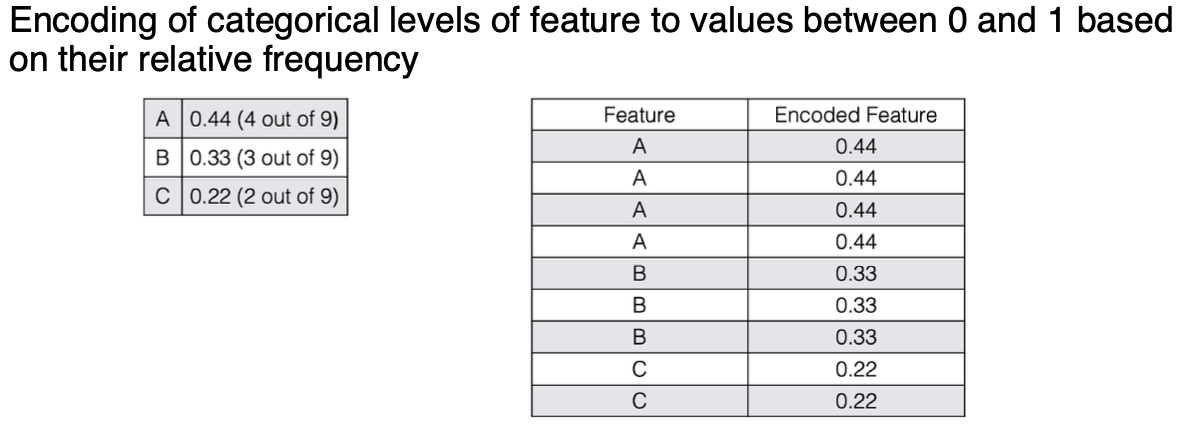
Frequency encoding
Missing Data Imputation
- 准备数据时的常见问题缺失值
- 数据并非总是可用
- 例如,许多图元的多个属性都没有记录值,如销售数据中的客户收入
- 数据缺失的原因可能是
- 设备故障
- 与其他记录数据不一致,因此被删除
- 由于误解而未输入数据
- 某些数据在录入时可能并不重要
- 未登记数据的历史或更改情况
- 可能需要推断丢失的数据!但如何呢?
How to Handle Missing Data
- 忽略元组:通常在缺失类标签时使用;但对属性值无效(假设是分类任务--当每个属性的缺失值百分比差异很大时无效)。
- 手动填写缺失值:繁琐+不可行?
- 使用全局常量来填补缺失值:如 "未知",一个新的类别?
- 使用属性平均值填补缺失值
- 使用属于同一类的所有样本的属性均值来填充缺失值:更聪明
- 使用最可能的值来填充缺失值:基于推理(例如贝叶斯公式或决策树)和基于关联
Guessing the missing data
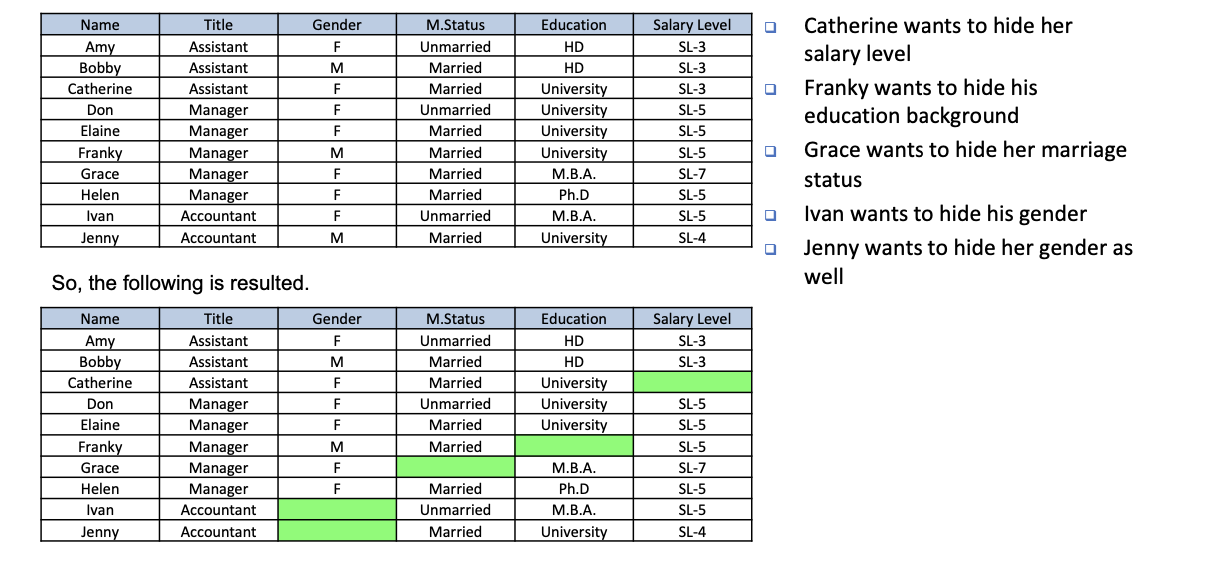
通过对缺失数据的数据集进行关联分析,我们可以得到
- R1:助理→SL-3(支持:2,置信度=100)
- R2:经理 Λ SL-5 → 大学(支持:2,信心度=66.7)
- R3:经理 Λ 女性 → 已婚(支持度:2,置信度=66.7)
因此,我们可以猜测缺失的数值如下。
- 凯瑟琳的工资级别是 SL-3
- 弗兰基的学历是大学
- 格蕾丝的婚姻状况是已婚
Data Transformation
不同形式的转型
- Smoothing: remove noise from data
- Aggregation: summarization, data cube construction「聚合:汇总、数据立方体构建」
- Generalization: concept hierarchy climbing「泛化:概念层次攀爬」
- Normalization: scaled to fall within a small, specified range
- min-maxnormalization
- z-score normalization
- normalization by decimal scaling
- Attribute/feature construction
- New attributes constructed from the given ones
Most commonly used transformation: Normalization
min-max normalization 可以是 X' = (X - Xmin) / (Xmax - Xmin)
