Data Preprocessing
Data Preprocessing
Major Tasks
- Data cleaning: 填补缺失值,平滑噪声数据,识别或删除异常值,解决不一致问题
- Data integration: 整合多个数据库、数据集或文件
- Data transformation: Normalization and aggregation
- Data reduction: 在体积上获得较少的代表性,但产生相同或相似的分析结果
- Discretization「离散化」 and concept hierarchy generation
- 数据缩减的一部分,但特别重要,尤其是对数值数据而言
Why Preprocess Data
Data in the real world is dirty
- incomplete:缺少属性值,缺少某些感兴趣的属性,或仅包含汇总数据
- noisy: containing errors or outliers
- inconsistent: containing discrepancies「差异」 in codes or names
No quality data, no quality mining results!
- 优质决策必须以优质数据为基础
- Data warehouse needs consistent integration of quality data
Data Quality
Multi-Dimensional Measure of Data Quality
一种广为接受的多维观点:
- Accuracy
- Completeness
- Consistency
- Timeliness「时效性」
- Believability「可信性」
- Value added
- Interpretability「可解释性」
- Accessibility「可访问性」
Data Cleaning
Missing Data
Recall the feature engineering
Noisy Data
Noise: random error or variance in a measured variable
Incorrect attribute values may due to
- 错误的数据收集工具
- data entry problems
- data transmission problems
- technology limitation
- inconsistency in naming convention
Other data problems which requires data cleaning
- duplicate records
- incomplete data「数据不完整」
- inconsistent data「数据不一致」
How to Handle Noisy Data
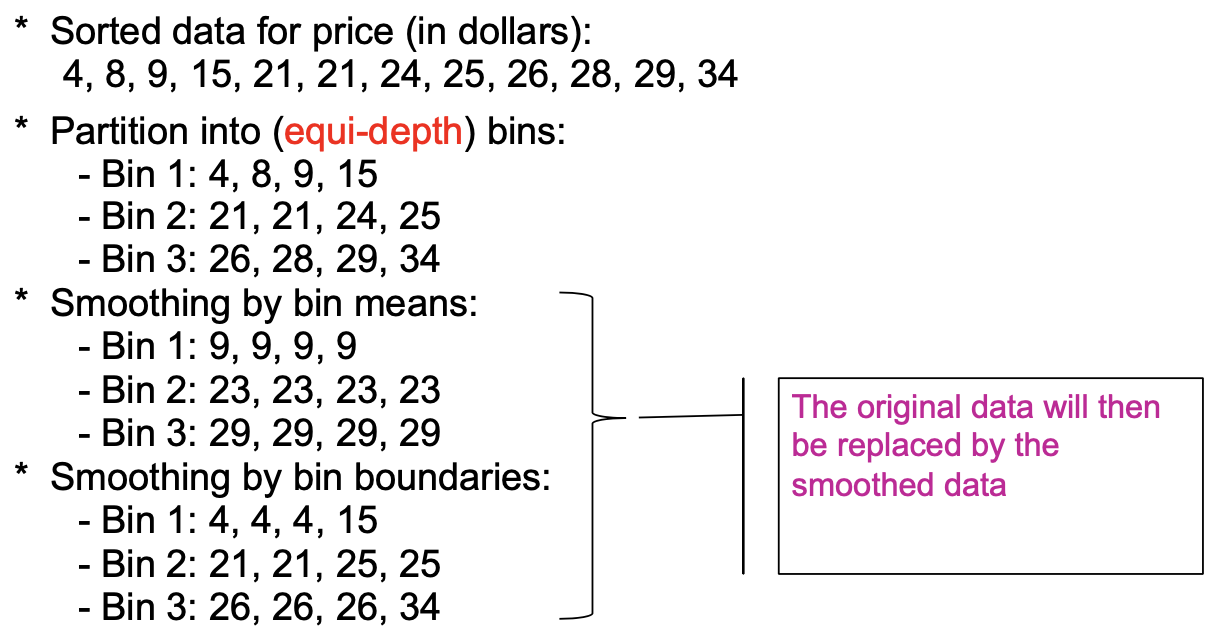
- Binning method「分箱法」:
- first sort data and partition into (equi-depth) bins「(等深)分区」
- 然后可以通过 bin 的均值、bin 的中值、bin 的边界等来平滑 bin 中的数据。
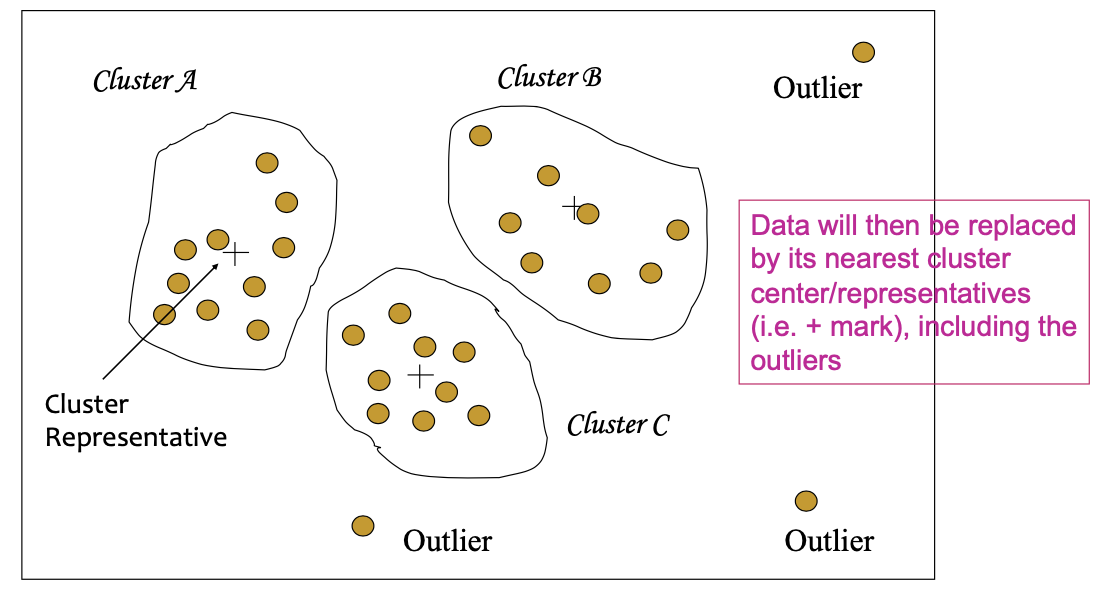
- Clustering:detect and remove outliers
- Combined computer and human inspection: 检测可疑值并由人工检查
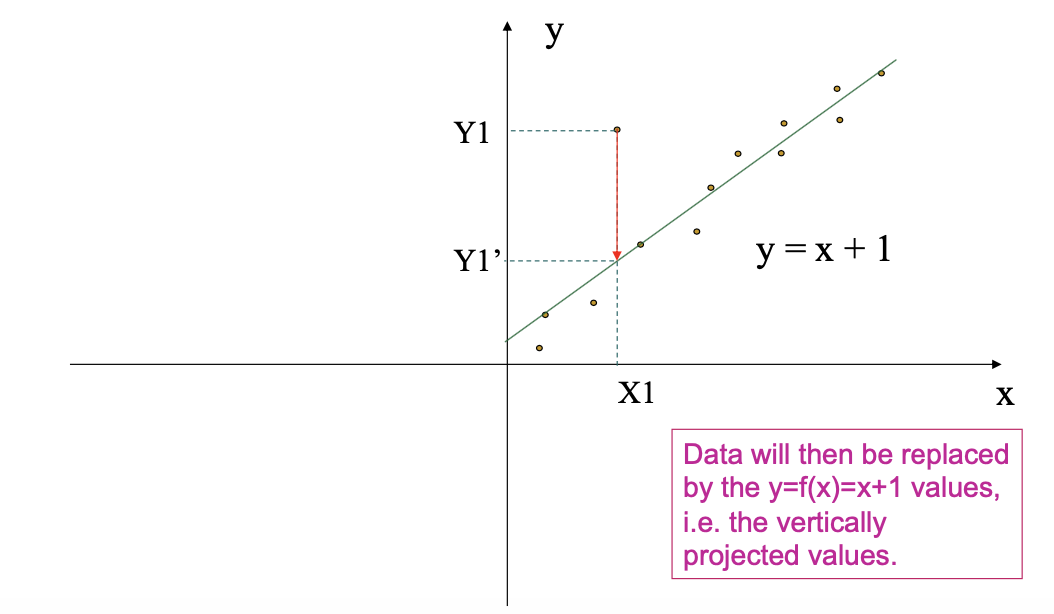
- Regression: smooth by fitting the data into regression functions
Binning
这是一种简单的离散化方法
- Equal-width (distance) partitioning
- 它将范围划分为 N 个大小相等的区间:均匀网格
- 如果 A 和 B 是属性的最低值和最高值,则区间宽度为W = (B-A)/N。
- 最直接
- 但离群值可能会在演示中占主导地位
- 偏斜数据「Skewed data」不好处理
- Equal-depth (frequency) partitioning:
- 它将范围划分为 N 个区间,每个区间包含大致相同数量的样本
- 良好的数据缩放
- 管理分类属性可能很棘手
Binning Methods for Data Smoothing
Smoothing by Cluster Analysis
Smoothing by Regression
Data Integration
Handling Redundant Data in Data Integration
- Redundant data occur often when integrating multiple databases
- 相同的属性在不同的数据库中可能有不同的名称
- 一个属性可能是另一个表中的“派生”属性,例如年收入
- 通过相关分析可以检测到冗余数据
- 仔细整合多个来源的数据,有助于减少/避免冗余和不一致,提高采矿速度和质量
Data Transformation
Different Forms of Transformation
- Smoothing (is a form of transformation): remove noise from data
- Aggregation: summarization, data cube construction
- Generalization「泛化」: concept hierarchy climbing
- Normalization: scaled to fall within a small, specified range
- 通过十进制缩放标准化
- min-max normalization
- z-score normalization
- Attribute/feature construction:从给定的属性构造新的属性
Data Reduction
仓库可存储 TB 级的数据:复杂的数据分析/挖掘可能需要很长时间才能在完整的数据集上运行
Data reduction: 获得数据集的缩减表示,体积更小,但能产生相同(或几乎相同)的分析结果
Data reduction strategies
- Dimensionality reduction
- Numerosity reduction
- Discretization and concept hierarchy generation「离散化和概念层次结构生成」
Dimensionality Reduction
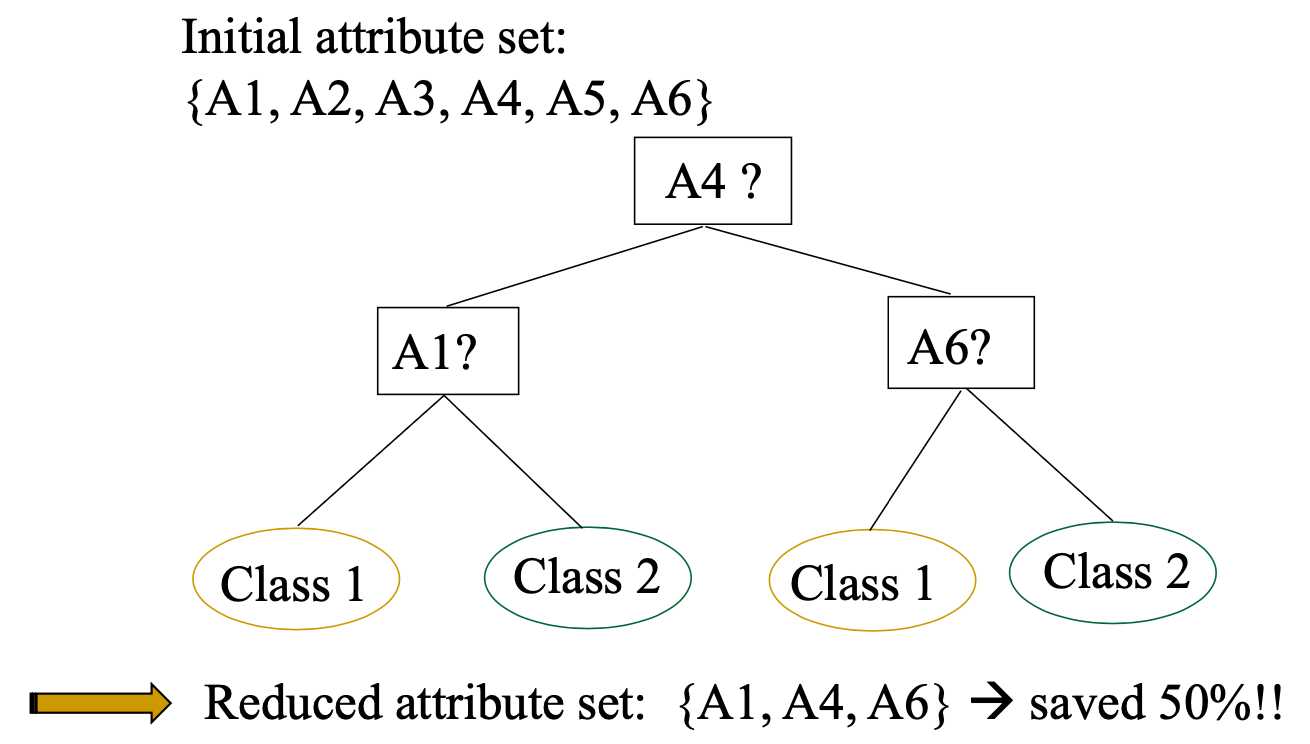
方法1:Feature selection (i.e., attribute subset selection):
- 选择最小的特征集,使给定这些特征值的不同类别的概率分布尽可能接近给定所有特征值的原始分布
- 减少模式中的模式数量,更容易理解

方法2:特征提取/转换 - 将现有特征组合(映射)为较少数量的新/替代特征
- 线性组合(投影「projection」)
- Nonlinear combination
Feature Selection vs Extraction
- 特征选择「Feature selection」:选择k<d个重要特征,忽略剩余的d-k
- 子集选择算法
- 特征提取「Feature extraction」:将原始 xi , i =1,...,d 维度投影到新的 k<d 维度,zj , j =1,...,k
- 主成分分析(PCA)、线性判别分析(LDA)、因子分析(FA)
Subset Selection

Linear dimensionality reduction
将 n 维数据线性投影到 k 维空间
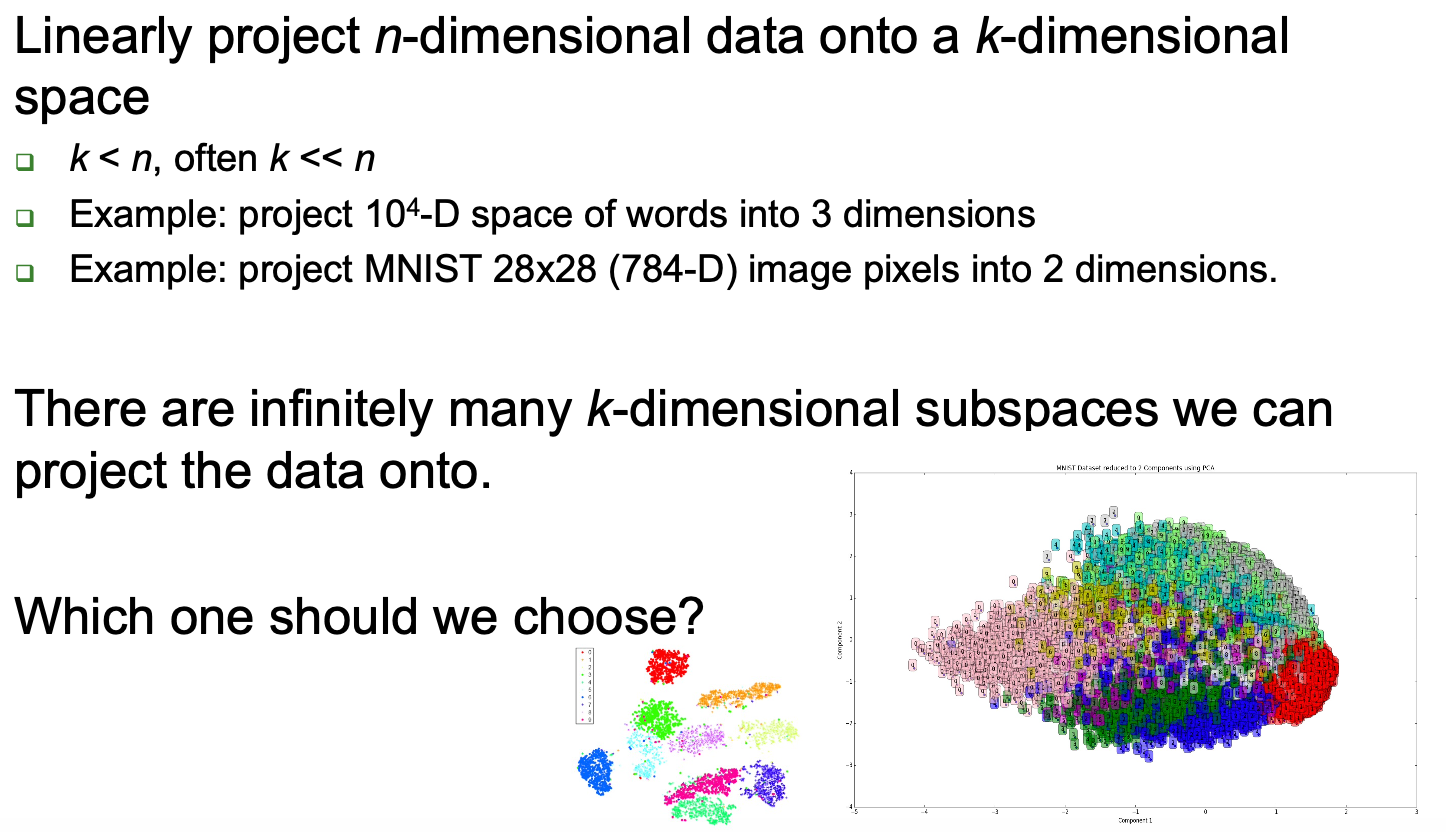
用于投影的最佳 k 维子空间取决于任务
- 分类:最大化类之间的分离(如 SVM)
- Example: linear discriminant analysis (LDA)
- Dimensionality reduction is not limited to unsupervised learning!
- 回归:最大化预测数据和响应变量之间的相关性
- Example: partial least squares (PLS)
- Unsupervised: retain as much data variance as possible
- Example: principal component analysis (PCA)
Decision Tree Induction for DR
Numerosity Reduction
“我们可以通过选择替代的、‘较小’的数据表示形式来减少数据量吗?”
Parametric methods「参数方法」
- 假设数据符合某个(回归)模型,估计模型参数,只存储参数,丢弃数据(可能的异常值除外)
- E.g. Linear regression where data are modeled to fit a straight line
Non-parametric methods
- Do not assume models
- Major families: histograms, clustering, sampling
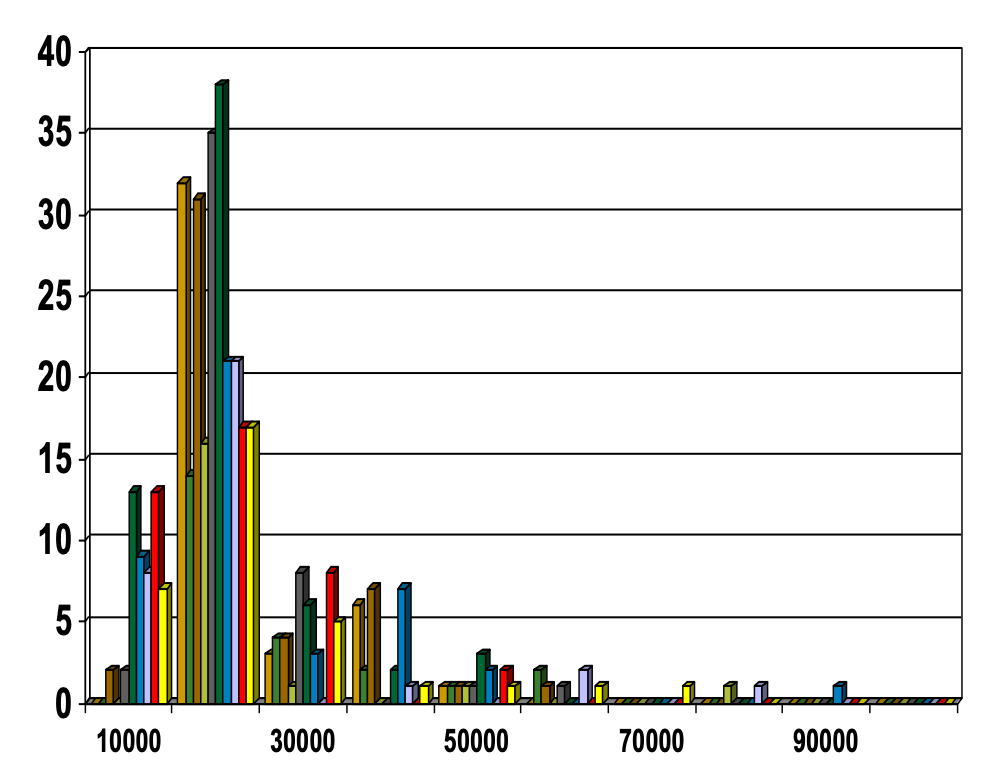
Non-parametric Numerosity Reduction: Histograms
- 流行的数据缩减技术
- 将这些数字分成若干个桶,并存储每个桶的平均值(总和)(以表示所有这些原始数字)
- 可通过动态编程在一维范围内进行优化构建
- 与量化问题有关。
Data Reduction By Clustering
将数据集划分为聚类,并且只能存储聚类表示法
如果数据是聚类的,则非常有效,但如果数据是 "模糊 "的,则无效
可以进行分层聚类,并存储在多维索引树结构中
聚类定义和聚类算法有多种选择
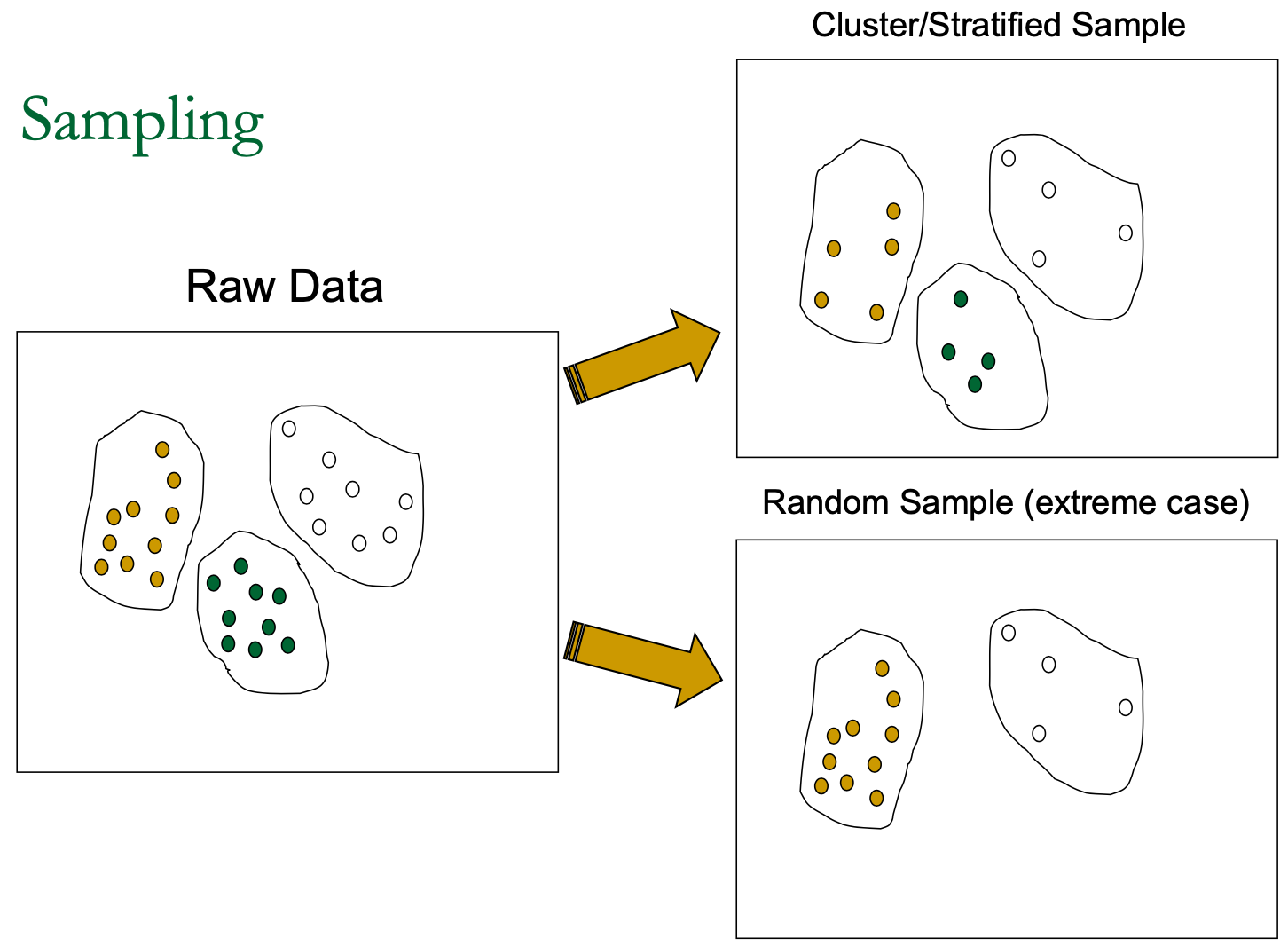
Data Reduction by Sampling
- 允许挖掘算法以与数据大小可能呈次线性关系的复杂性运行
- 选择具有代表性的数据子集
- 在存在偏斜的情况下,简单随机抽样的性能可能很差
- 开发适应性取样方法
- 分层抽样:
- 每个类别(或相关亚群)在整个数据库中的大致百分比
- 与偏斜数据结合使用
Discretization
Three types of attributes:
- Nominal/Discrete/Categorical — values from an unordered set (e.g. color set)
- Ordinal — 有序集合中的值(5 分制的 1,2,3,4,5,如电影评级)
- Continuous — real numbers
Discretization:
- 将连续属性的范围划分为区间,例如使用分箱方法
- 有些分类算法只接受分类属性
- 通过离散化减少数据量
- 为进一步分析做好准备
Discretization and Concept Hierarchy
Discretization: 通过将属性范围划分为区间,减少给定连续属性的数值数量。然后就可以用区间标签来替代实际数据值。
Concept hierarchies:
- 通过收集低级概念(如年龄属性的数值)并将其替换为高级概念(如青年、中年或老年)来减少数据。
- 其他示例包括构建→街道→地区→城市→国家以及用于广义关联规则挖掘的层次结构。